
요즘 LLM은 크기만 키우면 끝일까?
대형 언어 모델(LLM)이 갈수록 커지고 있습니다. 크기가 곧 지능이라 여기는 분위기 속에서, ‘컴팩트하지만 강력한 모델’은 그저 이상에 불과해 보이기도 합니다. 그런데 여기, 작지만 더 똑똑한 모델을 만들어낸 연구가 나왔습니다. 바로 DeepSeek가 발표한 논문 "Inference-Time Scaling for Generalist Reward Modeling" 입니다.
이 블로그에서는 다음 내용을 다룹니다:
- 일반적인 리워드 모델(Reward Model)의 한계
- Self-Principled Critique Tuning (SPCT)의 개념과 역할
- DeepSeek-GRM이 보여준 추론 시간 확장의 잠재력
- 실제 실험 결과와 기대되는 미래 활용
모델 크기를 키우지 않고도 추론 능력을 극대화할 수 있는 방법이 궁금하다면, 이번 포스팅을 끝까지 읽어보세요.
📌 리워드 모델링이 뭐길래 이렇게 중요한가요?
리워드 모델(Reward Model, RM)은 생성 AI가 더 좋은 출력을 하도록 도와주는 ‘심판’ 역할을 합니다. 특히 강화 학습 기반의 튜닝(RLHF) 에서는, 어떤 출력이 더 나은지 판단해주는 이 보상 모델이 핵심이죠.
그런데 문제는 이 RM이 다음과 같은 한계를 가진다는 겁니다:
- 복잡한 질의에는 점수를 매기기 어렵다: 과학, 수학, 코딩처럼 정답이 뚜렷한 분야는 RM이 성능을 잘 냅니다. 하지만 일상적인 대화나 instruction-following 같은 경우는?
- 스칼라 점수로는 부족하다: 단순 숫자 점수만으론 충분히 섬세한 평가를 할 수 없습니다.
이런 한계를 극복하고자 DeepSeek는 Generalist Reward Modeling(GRM) 이라는 접근을 제안합니다.

🧬 GRM과 SPCT: 리워드 모델링의 진화
✅ Pointwise Generative Reward Modeling (GRM)
GRM은 단순히 응답 간 비교(pairwise)만 하는 기존 방식에서 벗어나, 각 응답에 대해 직접 보상과 비평(critique)을 생성합니다.
이렇게 하면 다음과 같은 장점이 생깁니다:
- 다양한 입력 유형에 대응 가능
- 스칼라 점수 대신 언어적 설명 포함한 평가 가능
즉, 보상 모델이 단순한 숫자 대신 “왜 이 응답이 더 좋은지”를 말로 설명하게 되는 것이죠.

🧪 Self-Principled Critique Tuning (SPCT)
SPCT는 GRM의 학습 방법입니다. 이름 그대로, 모델이 스스로 원칙(principle)을 만들고, 그에 따라 비평(critique)을 생성하게 학습시킵니다.
1. Rejective Fine-Tuning (RFT)
- 초기 조정 단계
- 잘못된 원칙과 비평을 거부하면서 형식을 바로잡음
2. Rule-Based Online RL (GRPO)
- 실시간 보상 학습
- 정확도 기준(rule)에 따라 좋은 원칙과 비평을 강화함
이 두 단계로 SPCT는 RM이 다양한 쿼리에서 더 일관되고 설명력 있는 판단을 내리도록 훈련합니다.
⏱️ 추론 시간 확장(Inference-Time Scaling)의 마법
기존에는 모델을 더 정밀하게 만들려면 더 큰 파라미터와 더 많은 학습 시간이 필요했습니다. 하지만 DeepSeek는 새로운 접근을 보여줍니다: 추론할 때 연산을 더 많이 하면 더 나은 결과가 나온다!
주요 방법
1. 병렬 샘플링
- 다양한 원칙과 비평을 한 번에 샘플링
- 판단의 다양성과 질을 향상
2. Meta Reward Model (Meta RM)
- 샘플링된 원칙/비평을 다시 평가하는 심판의 심판
- 최종 투표(voting)를 가이드하여 더 나은 결과 도출
즉, 모델이 학습 중이 아닌 실행 중에 더 열심히 생각하고 더 정확한 결과를 낼 수 있게 만든 셈입니다.
🚀 DeepSeek-GRM, 작지만 강한 이유
DeepSeek-GRM은 SPCT로 학습된 Gemma-2-27B 기반의 모델입니다. 이 모델은 다음 특징을 가지고 있습니다:
- 컴팩트한 크기: 대형 모델이 아님에도 고성능 발휘
- 다양한 샘플링과 투표 방식 도입
- Meta RM까지 더해졌을 때 가장 높은 성능
실험 결과, DeepSeek-GRM은 기존 모델보다 더 많은 리즈닝 후보를 만들수록 성능이 높아졌으며, 다양한 RM 벤치마크에서 편향 없이 우수한 결과를 보여줬습니다.
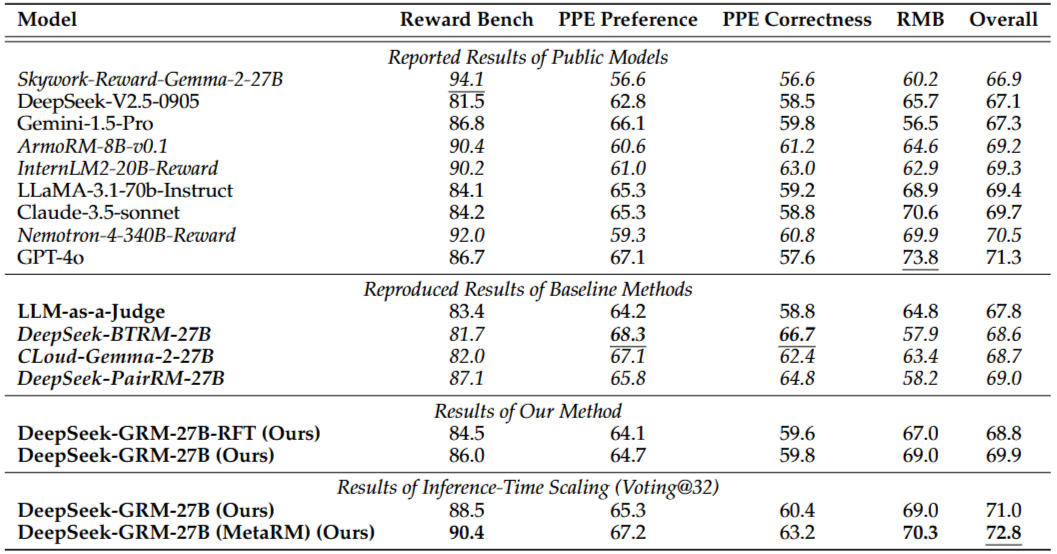
📊 실험이 증명한 DeepSeek-GRM의 가능성
- 더 많은 reasoning token을 생성할수록 정확도가 올라간다
- 스칼라 RM보다 정성적 평가를 포함한 GRM이 더 유연하다
- Meta RM을 활용한 voting 기법이 성능을 극대화한다
- 작은 모델(Gemma-2-27B)도 대형 모델 수준의 품질을 낸다
이제 LLM의 미래는 단순히 크기에만 달린 것이 아님을 보여준 사례입니다.
DeepSeek의 GRM 연구는 단순히 기술적으로 흥미로운 수준을 넘어서, 모든 LLM 개발자와 기업에게 중요한 메시지를 던집니다.
- 보상의 방식이 바뀌면, 모델의 한계도 달라진다
- 추론 단계에서의 연산 설계가 모델 품질을 좌우할 수 있다
- 작고 효율적인 모델도 ‘생각하는 힘’을 키울 수 있다
LLM이 이제 수학, 과학을 넘어 일상 대화, 에이전트 역할까지 확장되는 시대에, GRM과 SPCT는 새로운 표준이 될 가능성이 큽니다
그리고 이번 DeepSeek의 사례는 단지 엔지니어링 기술력뿐만 아니라, 강력한 연구 저력을 보여주었습니다.
Inference-Time Scaling for Generalist Reward Modeling
Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective i
arxiv.org

'인공지능' 카테고리의 다른 글
| Apple MCP: 메시지부터 지도까지 맥OS 자동화를 완성하는 애플 네이티브 툴킷! (0) | 2025.04.07 |
|---|---|
| “모든 파일을 Markdown으로!” – LLM 시대를 위한 경량 변환 도구, MarkItDown 완전 분석 (0) | 2025.04.07 |
| “LLM 추론 능력, 한 단계 도약” – 바이트댄스가 공개한 DAPO 알고리즘의 모든 것 (0) | 2025.04.07 |
| 중국판 GPT-4? ‘지푸 AI’의 초고속 AI 에이전트, 왜 주목받는가 (0) | 2025.04.06 |
| GitHub Copilot의 에이전트 모드와 MCP로 VS Code가 더 똑똑해졌다 (0) | 2025.04.06 |



