이 글은 Google Cloud AI Research가 제안한 PaperOrchestra라는 새로운 멀티 에이전트 기반 논문 작성 프레임워크를 정리합니다. PaperOrchestra는 연구자가 가진 아이디어 요약과 원시 실험 로그만을 입력으로 받아, 문헌 조사, 그림 생성, 인용 검증, LaTeX 논문 작성까지 자동으로 수행하는 시스템입니다. 기존 자동화 도구들이 해결하지 못했던 “실험 이후의 논문 작성 병목”을 어떻게 해결하는지, 구조와 특징, 성능 결과를 중심으로 살펴봅니다.
연구 논문 작성의 현실적인 문제
연구에서 가장 고통스러운 순간은 실험이 끝난 뒤입니다.
정리되지 않은 실험 로그, 흩어진 결과 테이블, 머릿속에만 있는 아이디어를 학회 포맷에 맞는 논문으로 바꾸는 데 몇 주가 걸립니다. 특히 초기 연구자에게 이 단계는 논문이 중도에 포기되는 주요 원인이 됩니다.
기존 자동 논문 작성 시스템들은 다음과 같은 한계를 갖고 있었습니다.
- 단순 텍스트 생성 중심: 데이터 기반 과학 서사를 완성하지 못함
- 자체 실험 파이프라인 의존: 사용자가 가진 데이터만으로는 논문 작성 불가
- 문헌 조사 한계: 맥락 없는 서베이 수준에 머무르거나, 사전 BibTeX 입력을 요구
이로 인해 “실제 연구자가 가진 날것의 자료를 그대로 받아 완성된 논문으로 만들어주는 도구”는 부재한 상태였습니다.
PaperOrchestra란 무엇인가
PaperOrchestra는 Google Cloud AI Research 팀이 제안한 독립형 논문 작성 프레임워크입니다.
실험을 대신 수행하는 연구 봇이 아니라, 연구자가 이미 수행한 실험 결과를 논문으로 번역해주는 시스템이라는 점이 핵심입니다.
입력은 단순합니다.
- 아이디어 요약(거친 메모 수준 가능)
- 원시 실험 로그(수치, 결과, 관찰 내용)
- 학회 LaTeX 템플릿과 가이드라인
출력은 다음을 포함합니다.
- 제출 가능한 LaTeX 논문 전체
- 검증된 BibTeX 인용 목록
- 자동 생성된 그림과 표
- 학회 형식에 맞춘 구조화된 원고
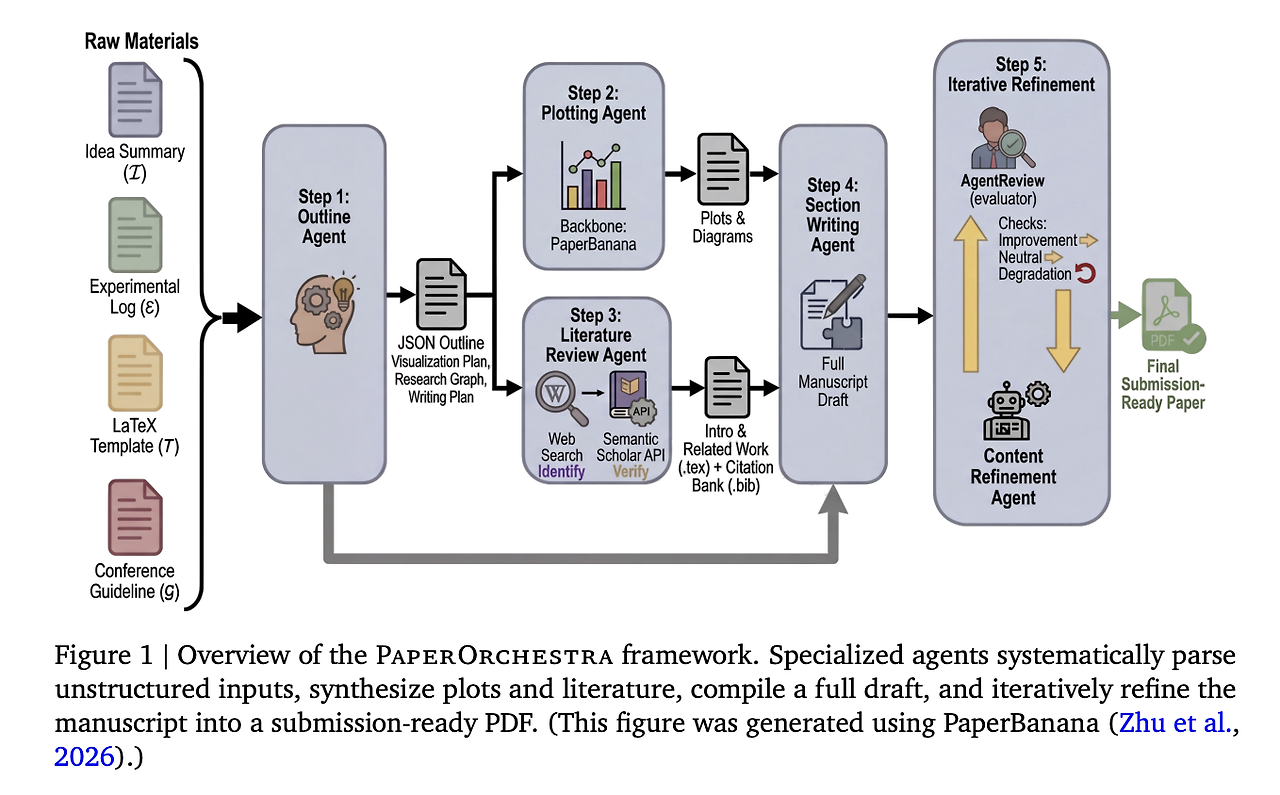
PaperOrchestra의 멀티 에이전트 파이프라인 구조
1단계: Outline Agent
- 아이디어 요약, 실험 로그, 학회 템플릿을 분석
- 전체 논문 구조를 JSON 형태의 아웃라인으로 생성
- 그림 생성 계획, 문헌 조사 전략, 섹션별 인용 힌트 포함
2–3단계: Plotting Agent & Literature Review Agent (병렬 실행)
Plotting Agent
- 시각화 계획에 따라 그림 생성
- PaperBanana 도구와 VLM 기반 비평 루프를 통해 반복 개선
Literature Review Agent
- 웹 검색 기반 후보 논문 수집
- Semantic Scholar API로 실제 존재 여부 검증
- 허위·검증 불가 인용 제거
- BibTeX 파일 생성 후 Introduction과 Related Work 작성
- 수집한 문헌의 90% 이상을 실제로 인용하도록 강제
4단계: Section Writing Agent
- 초록, 방법론, 실험, 결론 작성
- 실험 로그에서 수치를 직접 추출해 표 구성
- 생성된 그림을 LaTeX에 통합
5단계: Content Refinement Agent
- AgentReview라는 가상 피어리뷰 시스템을 활용
- 리뷰 점수가 개선될 때만 수정 사항을 반영
- 점수 하락 시 즉시 롤백 및 종료
이 단계는 선택이 아닌 필수입니다. 실험 결과에 따르면, 이 과정을 거친 논문은 거치지 않은 초안 대비 79~81% 승률을 기록했습니다.
성능 평가를 위한 PaperWritingBench
연구팀은 함께 PaperWritingBench라는 표준 벤치마크를 제안했습니다.
- CVPR 2025, ICLR 2025 채택 논문 200편 사용
- 실제 논문에서 아이디어 요약과 실험 로그를 역추출
- 저자 정보, 제목, 인용 제거로 완전 익명화
이를 통해 “실험 파이프라인과 무관한 순수 논문 작성 능력”을 평가할 수 있도록 설계되었습니다.
정량적·정성적 평가 결과
자동 평가 결과
- 문헌 조사 품질에서 기존 AI 대비 88~99% 압도적 우위
- 전체 논문 품질에서 AI Scientist-v2 대비 39~86% 개선
인간 연구자 평가
- 문헌 조사 품질: 50~68% 승률
- 전체 논문 품질: 14~38% 승률
- 문헌 종합 능력에서 인간 작성 논문과 43% 동률 또는 우위
인용 품질의 차이
- 기존 AI: 평균 9~14개 인용 (필수 인용 위주)
- PaperOrchestra: 평균 45~48개 인용
- 인간 논문 평균(~59개)에 근접
- “있으면 좋은 인용(P1)” 회수율 대폭 개선
핵심 시사점
- 논문 작성에 특화된 독립형 도구
실험을 대신하지 않고, 연구자가 가진 자료를 그대로 활용합니다. - 인용의 양이 아니라 질과 범위
학문적 깊이를 보여주는 인용 분포를 자동으로 구현합니다. - 멀티 에이전트 구조의 실질적 효과
단일 LLM 호출로는 도달할 수 없는 품질을 달성합니다. - 피어리뷰 기반 반복 개선의 중요성
최종 완성도를 끌어올리는 핵심 요소입니다. - 인간 연구자의 책임은 여전히 필수
새로운 실험 결과를 만들어내지 않으며, 최종 검증과 책임은 연구자에게 있습니다.
PaperOrchestra는 “논문 작성은 시간이 남아야 하는 부가 작업”이라는 인식을 뒤집습니다.
실험 이후 가장 큰 병목이었던 정리, 서술, 인용, 형식 맞추기를 자동화함으로써, 연구자는 더 많은 시간을 아이디어와 실험 설계에 집중할 수 있습니다.
완전 자동 연구자를 대체하는 도구가 아니라,
연구자의 사고를 논문이라는 형식으로 정확히 번역해주는 조력자라는 점에서,
향후 AI 기반 연구 생산성 도구의 중요한 방향성을 제시하는 사례라고 볼 수 있습니다.
Google AI Research Introduces PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Google AI Research Introduces PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
www.marktechpost.com

'인공지능' 카테고리의 다른 글
| EXAONE 4.5: LG AI Research의 오픈 웨이트 멀티모달 비전-언어 모델 핵심 정리 (0) | 2026.04.10 |
|---|---|
| MiniMax AI Platform 공식 CLI(mmx-cli)로 시작하는 멀티모달 AI 개발 환경 정리 (0) | 2026.04.10 |
| Google LangExtract와 OpenAI 모델로 구현하는 문서 인텔리전스 파이프라인 구축 가이드 (0) | 2026.04.10 |
| Opus 어드바이저 전략으로 진화한 Claude 에이전트 아키텍처 이해하기 (0) | 2026.04.10 |
| Claude Managed Agents: 프로덕션 에이전트 개발과 배포를 10배 빠르게 만드는 방법 (0) | 2026.04.09 |



