
한국어에 최적화된 진짜 ‘사람 같은 AI’가 나왔다?
요즘 생성형 AI 시장은 하루가 다르게 진화하고 있습니다. GPT-4o, 제미나이 등 이름만 들어도 강력한 글로벌 모델들이 쏟아지고 있는데요. 이 속도에 치여 국내 기술은 뒤처지는 거 아닌가… 걱정한 분들도 계셨을 겁니다.
그런데 이번에 카카오가 꺼낸 카드는 다릅니다. 텍스트, 음성, 이미지 — 이 3가지 정보를 통합적으로 이해하고 반응하는 멀티모달 언어모델, ‘카나나-o(Kanana-o)’입니다.
단순히 기능을 흉내 내는 것이 아니라, 배경음 속에서도 감정을 이해하고, 이미지에 맞는 목소리로 대답하는 수준까지 올라왔다는 것.
이 글에서는 카나나-o의 개념부터 기술적 구조, 어떤 점이 특별한지, 그리고 앞으로 어떤 가능성을 보여주는지까지 쉽게 풀어드릴게요.
1. ‘카나나-o’란 무엇인가요?
카나나-o는 텍스트·음성·이미지 세 가지 입력을 동시에 처리할 수 있는 **통합 멀티모달 언어모델(LMM)**입니다.
카카오는 이 모델을 통해 사람이 말하고 듣고 보는 방식에 더 가까운 AI를 구현하고자 했습니다.
기본 구조는 이렇습니다:
- 기존 이미지-텍스트 모델인 카나나-v
- 음성 중심의 모델 카나나-a
이 둘을 병합해 만든 것이 카나나-o입니다.
병합 방식의 장점은?
- 다중 모달리티 간 상호작용을 학습할 수 있음
- 학습 시간 절감, 기존 모델의 강점을 그대로 활용
- 다양한 상황에서도 유연하게 작동 가능
예를 들어, 이미지를 보고 해당 장면에 어울리는 목소리로 설명하거나, 배경 소음이 있는 음성 속 감정을 파악하는 게 가능해진 것이죠.
2. 기존 LMM과 뭐가 다르죠?
많은 멀티모달 모델은 보통 이미지+텍스트 또는 음성+텍스트 두 가지 조합으로 학습합니다.
하지만 카나나-o는 이미지+음성+텍스트, 즉 삼중 모달(tri-modal) 구조를 학습합니다. 이게 핵심 차이점입니다.
📌 기존 LMM은 두 개의 정보만 묶는 ‘짝짓기’를 했다면,
카나나-o는 세 가지 정보를 함께 ‘대화시키는’ 훈련을 받은 셈입니다.
이 과정에서 카카오가 사용한 전략은 다음과 같습니다:
- 이미지-텍스트 데이터를 학습한 카나나-v 활용
- 여기에 대응하는 TTS(텍스트 음성 변환) 데이터를 생성
- 최종적으로 3가지 모달리티 간의 연결성을 학습한 통합 데이터셋 구성
결국, 더 사람답게 사고하고 반응할 수 있는 기반을 마련한 겁니다.
3. 카나나-o, 무엇이 가능할까?
카나나-o의 기능은 단순히 인식과 응답을 넘어서, **‘이해’와 ‘공감’**에 가까운 방향으로 진화했습니다.
주요 기능 요약:
| 기능 | 설명 |
| 🎧 배경음 섞인 음성 인식 | 소음이 있어도 정확한 인식 가능 |
| 😊 감정 담긴 음성 이해 및 생성 | 슬픔·기쁨 등 감정까지 분석·생성 |
| 🗣 방언 이해 | 지역 사투리도 자연스럽게 해석 |
| 🌍 음성 통역 | 실시간 다국어 음성 대응 가능 |
| 🖼 이미지 이해 후 음성 응답 | 시각 정보에 맞는 대화형 음성 생성 |
이러한 기능은 단순 사용자 경험 개선을 넘어, 음성 기반 인터페이스, 접근성 기술, 교육/헬스케어 등 다양한 분야에 활용될 수 있습니다.
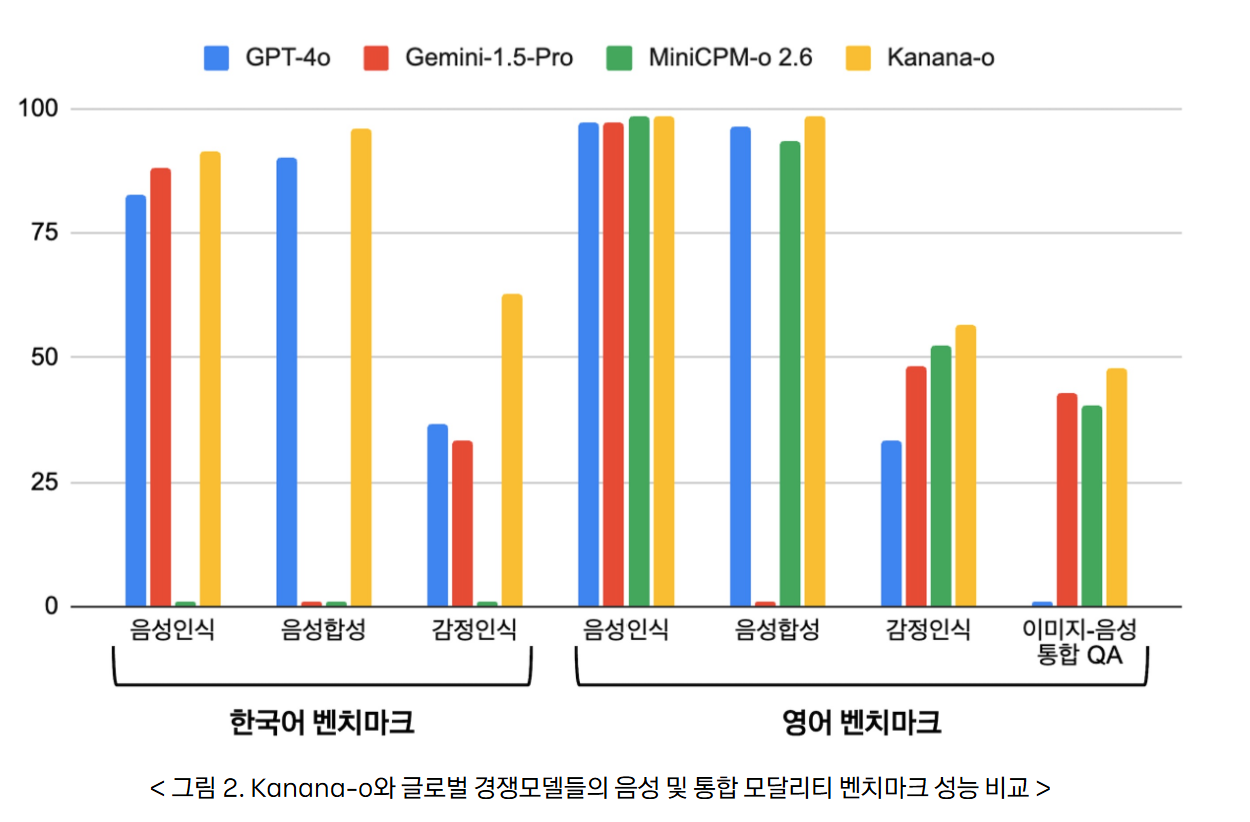
4. 성능은 실제로 어떤가요?
성능 검증도 철저히 진행됐습니다. 카카오는 삼중 모달 평가셋을 직접 구성해 아래와 같이 평가했습니다:
- 텍스트 명령어 → 음성으로 변환
- 해당 음성과 이미지 → 카나나-o 입력
- 응답 텍스트의 정확도, 자연스러움 등 평가
또한 한국어 맞춤형 평가 데이터셋을 활용한 비교 결과에서는 놀라운 결과가 나왔습니다:
✅ GPT-4o, 제미나이-1.5보다 한국어 감정 인식에 더 뛰어남
이는 단순 언어 모델이 아니라, 언어적 맥락+감정적 뉘앙스까지 이해하는 멀티모달 AI의 가능성을 보여줍니다.
5. 어디에, 어떻게 활용할 수 있을까?
가능한 활용 시나리오:
- 📱 AI 상담사: 감정 읽는 고객센터
- 🎙 음성 인터페이스: 시각장애인을 위한 이미지 묘사 AI
- 🧓 시니어 케어봇: 감정을 반영한 대화형 돌봄
- 🎧 다국어 통역기: 실시간 오디오 기반 번역
그리고 아직 초기 단계이지만, 카카오는 앞으로 다음과 같은 방향으로 확장할 계획입니다:
- 멀티턴 대화 처리 (AI가 문맥을 잇는 대화 가능)
- 다국어 확대 (한국어 외 언어도 대응)
- 양방향 시스템 대화 구조
- 안전성과 신뢰성 강화
‘카나나-o’가 던지는 의미
카나나-o는 단순히 “카카오도 LLM 만들었다” 수준이 아닙니다.
사람처럼 보고, 듣고, 말하는 AI를 위한 본격적인 도전이자, 한국어에 강점을 가진 국산 멀티모달 AI의 출현이라는 점에서 의미가 큽니다.
지금은 실험적이고 제한적인 부분도 있지만,
이 모델이 나아가는 방향은 분명합니다 — 감정까지 공감하는 진짜 사람 같은 AI.
앞으로 얼마나 더 정교해질지, 어디까지 활용될지 주목해볼 필요가 있습니다.
👀 요약 정리
- 카나나-o는 텍스트·음성·이미지를 통합한 멀티모달 모델
- 기존 모델을 병합해 학습 시간 단축 + 기능 특화
- 삼중 모달 연결성 학습으로 정교한 감정 이해 가능
- GPT-4o, 제미나이보다 한국어 감정 처리에서 우수
- 다국어·다분야 확장 가능성 보유
이미지와 음성을 아우르는 카카오의 멀티모달 언어모델 Kanana-o 알아보기 - tech.kakao.com
안녕하세요, 카카오의 AI 모델 개발을 담당하는 카나나(Kanana) 조직의 Ed...
tech.kakao.com

'인공지능' 카테고리의 다른 글
| 오픈소스 AI의 새로운 시대, LlamaCon 2025에서 발표된 모든 것 (0) | 2025.05.03 |
|---|---|
| 알리바바의 새로운 한 수, 'Qwen2.5-Omni-3B' — 작지만 강력한 음성 대화 AI (0) | 2025.05.03 |
| ChatGPT를 '주니어 개발자'처럼 쓰는 법? 마틴 파울러가 알려준 페어 프로그래밍 전략 (0) | 2025.05.02 |
| Claude가 당신의 팀원이 된다면? - Claude Integrations로 업무 자동화와 협업을 완전히 바꾸는 방법 (0) | 2025.05.02 |
| AI가 당신 대신 코드를 짠다? 마크 저커버그의 충격 발언과 다가오는 개발의 미래 (0) | 2025.05.02 |



