[Data Lake란 무엇인가?]
"가공되지 않은 다양한 종류의 데이터를 한 곳에 모아둔 저장소의 집합이다."
오랜 시간 데이터들은 데이터가 생성된 영역별로 수집 및 관리가 이루어졌으며 주로 정형화된 데이터로만 분석되어왔다. 하지만 빅데이터와 인공지능 기술의 중요성이 커지면서 다양한 영역의 다양한 데이터가 만나 새로운 가치를 만들어내기 시작하였다. 이와 같이 빅데이터를 효율적으로 분석하고 사용하고자 다양한 영역의 Raw 데이터(가공되지 않은 데이터)를 한 곳에 모아서 관리하고자 하는 것을 바로 Data Lake라 한다.
[Data Lake Framework 탄생]
"Data Lake에 빅데이터를 사용자가 보다 쉽고 빠르게 사용할 수 있도록 제공해주는 Framework"
Data Lake라는 개념이 나오고 데이터를 한곳에 모으기 시작하였지만 데이터 사용자는 데이터 준비 과정에만 작업 시간의 80%를 소요하였다. 이와 같은 문제점을 해결하고자 나온것이 바로 Data Lake Framework이다. 데이터 엔지니어가 데이터 사용자들의 데이터 준비 시간을 단축시켜 주는 것이다.
[Data Lake Framework는 데이터 사용자에게 어떤 가치를 제공해줄까?]
Data Lake Framework가 등장하면서 데이터 분석가나 인공지능 전문가들은 더이상 빅데이터를 준비하는 영역의 기술을 고민하지 않아도 되게 되었다. 즉 사전에 데이터를 준비하는데 필요한 기술의 고민은 Framework를 개발하는 엔지니어의 몫이 된 것이다. 이렇게 데이터를 준비하는 과정이 단순화 됨으로서 데이터 사용자는 자신의 본 업무에 보다 집중할 수 있게 되었다. 그렇다면 Framework가 사용자에게 제공해야하는 기능적인 범위는 어디까지일까?
기능적인 범위를 한정짓기는 어렵다. 데이터 사용자에게 데이터를 효율적으로 수집하고 가공하며 제공하는 데이터의 흐름에 전영역이 포함될 것이다. 그렇다면 단계별로 Framework가 제공해야 하는 기술 및 역할들을 간단히 살펴보자.
<수집>
Data Lake는 앞서 이야기한바와 같이 다양한 영역으로부터 생성된 데이터를 한 곳에 모아두는 것을 의미한다. 그렇기 때문에 데이터들을 효율적으로 수집하기 위한 기능들을 제공해야 한다.
-데이터의 형태는 다양하기 (정형, 비정형, 반정형) 때문에 각각에 맞는 수집 방법을 고려하여 제공한다.
-주기적으로 데이터를 수집하는 것이외에도 실시간 서비스로부터 생성된 Stream 데이터 수집 또한 지원한다.
-수집 파이프라인은 빠르고 신뢰할 수 있으며 유연하다.
-다양한 데이터 소스(RDB, HDFS, NoSQL 등...)로부터 연결 어댑터를 제공함으로서 사용자가 하나의 저장소로부터 데이터를 사용한 것과 같이 제공한다.
<가공 및 제공>
사용자가 자신이 데이터를 사용하기 위한 목적에 맞게 가공하는 행위를 말한다.
Data Lake에서 관리하고 있는 데이터들은 Raw Data로서 데이터 분석을 하기 위해 추가적으로 가공 작업이 필요한 상태이다. (예를 들면 Noise 제거 및 의미있는 데이터 도출 등이 이에 해당할 것이다.)
-Data Lake 플랫폼의 구성 요소중 가장 트렌디한 기술에 해당한다.
-머신러닝을 기반으로 정제/변환/탐색을 자동화하여 사용자가 쉽고 빠르게 원하는 데이터를 준비할 수 있도록 지원한다.
-데이터셋을 자동으로 분류, 표준화하고 서로 유사한 데이터셋을 찾아준다.
-데이터 변환에 다양한 함수를 적용할 수 있도록 지원한다.
-더 나아가 데이터 스키마 정보를 이용해 데이터를 미리 수집하지 않고 JOIN / MERGE를 통해 새로운 데이터 셋을 생성할 수 있도록 해야 한다.
(데이터 가상화 기술로 데이터 셋에 대한 프로토타이핑을 위해 사용된다. _ 저장 공간의 효율화)
-다양한 크기의 데이터와 서로 다른 데이터 형식을 보다 쉽고 빠르게 통합한다.
-데이터 분석가나 인공지능 전문가들이 빅데이터를 다루는 기술 없이도 분석에 필요한 데이터를 준비할 수 있도록 해주는 영역이다.
<관리>
많은 데이터가 모여있는 곳인 만큼 데이터의 품질 및 이력을 관리해야 한다.
- 데이터에 대한 품질 / 프로파일링 정보(데이터 분표, 통계, 샘플)를 제공한다.
- 지정된 데이터 포맷으로 되어 있는지 여부를 체크한다.
- 중복된 데이터를 확인하고 제거해야 한다.
- 개인 정보 및 데이터 표준화, 결측치 보정, 이상치 탐지등의 데이터 정제 작업도 해당한다.
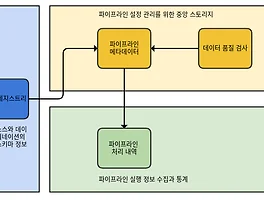
- 메타 데이터 관리를 해야 한다. 여기서 메타 데이터는 데이터에 대한 데이터로 수집한 데이터에 대한 추가적인 정보를 의미한다. (메타 데이터에 해당하는 요소는 데이터가 언제, 어떻게, 누구에 의해 생성되었는지에 대한 것이며
메타 데이터는 데이터를 검색하고 추적하는데 도움이 된다.)
- 데이터의 무결성을 보장하기 위해 Raw Data의 관계와 속성, 계층구조, 처리 규칙등에 대한 정보를 관리하는 것이 좋다.
앞으로 데이터는 더욱 많이 생성되고 사용될 것이다.
5G통신 및 Iot기기가 늘어나면서 이와 같은 흐름은 더욱 가속화 될 것으로 판단된다.
Data Lake도 시대가 변해하는 것과 함께 발전되어 갈 것으로 생각된다.
https://digitalbourgeois.tistory.com/145
[빅데이터] Data Mesh란 무엇인가?
데이터 메쉬(Data Mesh) 개념데이터 메쉬는 기존의 중앙집중식 데이터 아키텍처의 한계를 극복하기 위해 제안된 분산 데이터 아키텍처 패턴입니다. 주로 대규모 조직에서 데이터 관리 및 분석의
digitalbourgeois.tistory.com
'빅데이터' 카테고리의 다른 글
| [빅데이터] 데이터 플랫폼 스키마 관리 하기 (0) | 2023.04.04 |
|---|---|
| [빅데이터] 메타데이터에 대해 알아보자 (0) | 2023.04.03 |
| 데이터 플랫폼 - 스토리지 설계 및 구축 방법 (0) | 2023.03.28 |
| [데이터 플랫폼] 클라우드 데이터 플랫폼 설계 및 구축 (0) | 2022.10.23 |
| [빅데이터] 데이터 웨어 하우스란? (0) | 2019.04.22 |