기술이 발전함에 따라 대형언어모델(LLM)의 컨텍스트 창이 확대되며, RAG(검색 증강 생성)보다 더 빠르고 효율적인 접근 방식인 CAG(캐시 증강 생성)가 주목받고 있습니다. CAG는 검색의 복잡성을 줄이고, 모델의 성능과 정확도를 극대화할 수 있는 대안으로 부상하고 있는데요. 이번 블로그에서는 RAG와 CAG의 차이점, CAG의 작동 방식, 그리고 왜 이 기술이 주목받고 있는지 알아보겠습니다.
1. RAG와 CAG의 차이점
RAG(검색 증강 생성)란?
RAG는 외부 데이터베이스에서 검색한 정보를 LLM이 통합하여 응답을 생성하는 방식입니다. 하지만 RAG는 검색 과정에서 다음과 같은 문제를 발생시킬 수 있습니다:
- 검색 지연: 검색에 시간이 소요됩니다.
- 문서 선택 오류: 불필요한 정보를 검색하거나 중요한 정보를 놓칠 수 있습니다.
- 시스템 복잡성 증가: 검색 시스템과 LLM의 통합은 개발과 유지 보수 측면에서 비용이 큽니다.
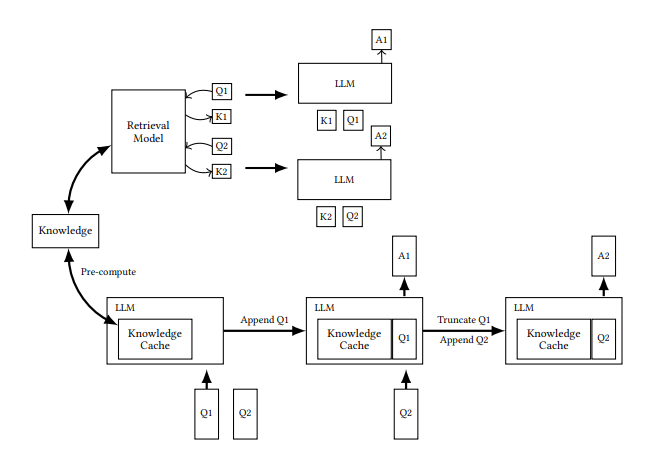
CAG(캐시 증강 생성)란?
CAG는 모델의 확장된 컨텍스트 창을 활용해 필요한 문서를 검색하지 않고 프롬프트에 직접 입력하여 응답을 생성하는 방식입니다.
- 빠른 처리 속도: 문서의 토큰 어텐션 값을 미리 계산하여 처리 속도를 단축합니다.
- 높은 정확도: 검색 과정이 없어 관련 없는 정보를 참조할 가능성이 줄어듭니다.
- 간소화된 시스템: 별도의 검색 시스템 없이도 작동하므로 시스템 구조가 단순합니다.
2. CAG의 주요 특징과 장점
2.1. 더 커진 컨텍스트 창
최근 LLM은 수십만에서 최대 400만 토큰까지 처리할 수 있는 컨텍스트 창을 지원합니다. 이를 통해 긴 문서를 한번에 모델에 입력할 수 있어 문서 단위의 전체 맥락을 고려한 응답이 가능해졌습니다.
2.2. 비용 및 대기 시간 감소
CAG는 오픈AI와 앤트로픽 등에서 제공하는 프롬프트 캐싱 기술을 활용하여 처리 비용과 시간을 획기적으로 줄였습니다.
- 예를 들어, 앤트로픽의 모델은 프롬프트 캐싱으로 **추론 비용을 90%**까지 줄일 수 있습니다.
2.3. 간편한 구현
CAG는 복잡한 검색 시스템을 구축할 필요 없이 프롬프트에 필요한 정보를 입력하면 되므로, 초기 구현이 상대적으로 간단합니다.
3. RAG와 CAG의 성능 비교 실험
CAG의 성능은 벤치마크 실험에서도 입증되었습니다.
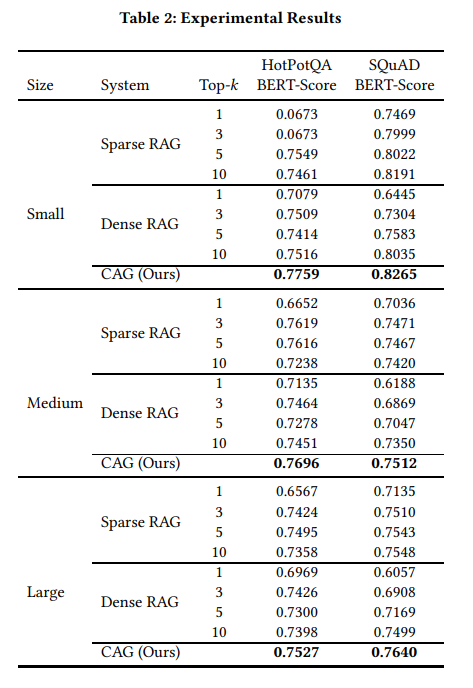
- 테스트 환경:
- 단일 문서 Q&A(SQuAD)와 다중 문서 추론(HopPotQA)에서 테스트.
- 사용 모델: 라마 3.1 8B, 컨텍스트 창 12만8000 토큰.
- 결과:
CAG는 대부분의 상황에서 RAG보다 성능이 뛰어났으며, 특히 다음과 같은 장점이 확인되었습니다:- 검색 오류 제거.
- 관련 정보에 대한 전체 맥락 이해.
- 답변 생성 시간 단축.
4. CAG를 도입할 때 주의할 점
CAG는 강력한 도구지만 모든 상황에 적합한 것은 아닙니다.
- 컨텍스트 창 크기 제한: 너무 큰 문서를 입력하면 모델 속도가 느려질 수 있습니다.
- 빈번한 문서 변경 문제: 입력 문서가 자주 변경되는 경우에는 캐싱 효과가 감소합니다.
- 상충하는 정보 처리: 기업 문서에 상충되는 정보가 포함될 경우 모델이 혼란을 겪을 수 있습니다.
따라서 CAG를 도입하기 전, 문서 크기와 구성에 대한 사전 검토가 필요합니다.
5. 시사점 및 기대 효과
CAG는 RAG의 한계를 극복하며, 차세대 LLM 활용의 새로운 가능성을 제시합니다.
- 효율성: 처리 속도와 비용에서 큰 이점을 제공합니다.
- 확장성: 발전하는 모델과 함께 더 복잡하고 다양한 애플리케이션에 적용될 수 있습니다.
- 간단한 구현: 복잡한 검색 시스템 없이도 높은 성능을 기대할 수 있습니다.
앞으로 RAG와 CAG가 공존하거나 CAG가 주도하는 방식으로 기술이 발전할 가능성이 높습니다. 특히 긴 컨텍스트를 효과적으로 활용해야 하는 기업과 연구 환경에서 CAG는 강력한 선택지가 될 것입니다.
캐시 증강 생성(CAG)은 대형언어모델 기술의 새로운 패러다임을 열고 있습니다. 이 기술은 RAG의 단점을 보완하며, 더 효율적이고 간편한 방식으로 LLM을 활용할 수 있게 해줍니다. 앞으로 더 많은 실험과 검증을 통해 다양한 도메인에서 활용될 CAG의 가능성을 기대해도 좋을 것입니다.
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Retrieval-augmented generation (RAG) has gained traction as a powerful approach for enhancing language models by integrating external knowledge sources. However, RAG introduces challenges such as retrieval latency, potential errors in document selection, a
arxiv.org


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'인공지능' 카테고리의 다른 글
| 마이크로소프트의 AI 보안 강화 전략: 레드 팀 활동과 생성형 AI의 잠재적 위험 관리 (0) | 2025.01.23 |
|---|---|
| LLM의 추론 성능을 높이는 새로운 접근법: 마인드 진화(Mind Evolution)와 제미나이 1.5 Pro (0) | 2025.01.22 |
| AI와 TDD의 만남: LLM을 활용한 코드 개발 효율화 전략 (0) | 2025.01.22 |
| DeepSeek-R1: 새로운 세대의 추론 AI와 모델 혁신의 시작 (0) | 2025.01.21 |
| AI로 만드는 신소재의 미래: 마이크로소프트 '매터젠(MatterGen)'이 혁신을 이끄는 방법 (0) | 2025.01.20 |



