대규모 트래픽을 처리해야 하는 서비스에서 가장 큰 고민은 무엇일까요? 성능은 유지하면서도 비용을 낮추는 것, 그리고 지연 시간을 최소화하는 것입니다. 이번 글에서는 이러한 요구를 충족하기 위해 공개된 Gemini 3.1 Flash-Lite의 핵심 개념과 특징, 성능 지표, 그리고 실제 활용 가능성까지 정리합니다.
특히 고빈도 API 호출, 실시간 응답, 대규모 번역 및 콘텐츠 처리 환경에서 어떤 가치를 제공하는지에 초점을 맞춰 살펴보겠습니다.
Gemini 3.1 Flash-Lite 개요
Gemini 3.1 Flash-Lite는 Gemini 3 시리즈 중 가장 빠르고 비용 효율적인 모델로 설계되었습니다. 고품질 출력을 유지하면서도 대량 처리 환경에 최적화된 모델이라는 점이 핵심입니다.
현재 개발자는 Gemini API를 통해 사용할 수 있으며,
- 개발자 환경: Google AI Studio
- 엔터프라이즈 환경: Vertex AI
에서 프리뷰 형태로 제공되고 있습니다.
비용 효율성과 속도: 수치로 보는 경쟁력
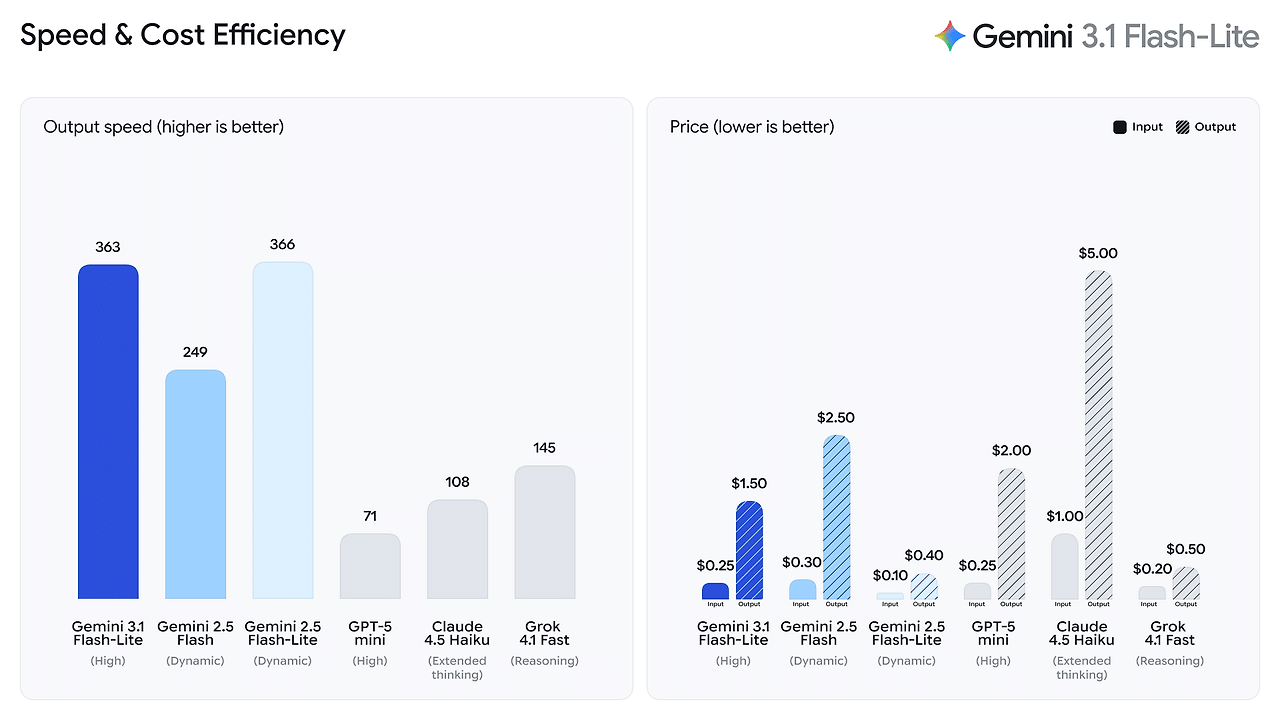
1. 비용 구조
- 입력: $0.25 / 100만 토큰
- 출력: $1.50 / 100만 토큰
대규모 호출이 필요한 서비스에서 토큰 단가는 곧 운영 비용과 직결됩니다. Flash-Lite는 이 지점을 정조준한 모델입니다.
2. 성능 개선
Gemini 2.5 Flash 대비:
- Time to First Answer Token 2.5배 향상
- 출력 속도 45% 증가
- 유사하거나 더 나은 품질 유지
해당 수치는 Artificial Analysis 벤치마크 기준입니다.
즉, 더 빠르게 첫 응답을 시작하고, 더 빠르게 결과를 완성합니다.
실시간 채팅, 자동 응답 시스템, 대화형 인터페이스에 적합한 이유입니다.
벤치마크 성능과 지능 수준
Gemini 3.1 Flash-Lite는 단순히 빠른 모델이 아닙니다. 지능 수준 역시 동급 모델 대비 높은 평가를 받았습니다.
- Arena.ai Leaderboard Elo 점수 1432
- GPQA Diamond: 86.9%
- MMMU Pro: 76.8%
여기서 언급된:
- GPQA Diamond
- MMMU Pro
는 추론 및 멀티모달 이해 능력을 평가하는 지표입니다.
이전 세대의 대형 모델보다도 일부 영역에서 더 높은 점수를 기록했다는 점은, "경량 모델 = 낮은 지능"이라는 공식을 깨는 사례라 할 수 있습니다.
Thinking Level: 개발자가 조절하는 추론 깊이
Gemini 3.1 Flash-Lite는 AI Studio와 Vertex AI에서 Thinking Level을 기본 제공합니다.
이는 모델이 문제를 얼마나 깊게 “생각”할지를 개발자가 제어할 수 있는 기능입니다.
왜 중요한가?
고빈도 트래픽 환경에서는 모든 요청에 깊은 추론이 필요하지 않습니다.
예를 들어:
- 단순 번역 → 낮은 thinking level
- 콘텐츠 모더레이션 → 중간 수준
- UI 자동 생성, 대시보드 구성 → 높은 수준
이처럼 작업 특성에 따라 지능 수준을 조절함으로써 비용과 응답 속도를 효율적으로 관리할 수 있습니다.
활용 시나리오
1. 대규모 번역 및 콘텐츠 모더레이션
비용이 중요한 환경에서 Flash-Lite는 최적의 선택지입니다.
대량 처리 작업에서 지연 시간과 단가를 동시에 줄일 수 있습니다.
2. UI 및 대시보드 자동 생성
복잡한 지시를 따르며 인터페이스를 구성하거나 시뮬레이션을 생성하는 작업도 수행 가능합니다.
예시:
- 전자상거래 와이어프레임에 수백 개의 상품 자동 배치
- 카테고리별 제품 구성 자동 생성
3. 고빈도 실시간 서비스
- 고객 상담 챗봇
- 실시간 번역
- 자동 응답 시스템
- 대시보드 생성 도구
응답 지연이 사용자 경험을 좌우하는 서비스에 적합합니다.
실제 도입 사례
초기 액세스 기업으로는 다음과 같은 기업들이 있습니다.
- Latitude
- Cartwheel
- Whering
이들 기업은 대규모 문제 해결과 복잡한 입력 처리에서 Flash-Lite의 효율성과 추론 능력을 높이 평가했습니다. 특히 대형 모델 수준의 정밀함과 지시 준수 능력을 유지하면서도 비용 부담을 줄일 수 있다는 점이 강조되었습니다.
Gemini 3 시리즈 내에서의 위치
Flash-Lite는 Gemini 3 series 중에서도 “고효율·고처리량”에 특화된 모델입니다.
- 대형 모델: 고난도 추론 중심
- Flash 계열: 균형형
- Flash-Lite: 대량 처리 및 비용 최적화 특화
워크로드 특성에 따라 모델을 선택할 수 있도록 포트폴리오가 세분화된 것입니다.
Gemini 3.1 Flash-Lite는 단순한 경량 모델이 아닙니다.
- 빠른 응답 속도
- 낮은 토큰 비용
- 경쟁력 있는 추론 성능
- 조절 가능한 thinking level
이 네 가지 요소를 결합해 대규모 트래픽 환경에 최적화된 모델로 자리잡고 있습니다.
특히 고빈도 API 호출 기반 서비스, 실시간 인터랙티브 애플리케이션, 대량 번역·모더레이션 플랫폼에서는 비용과 성능의 균형을 동시에 확보할 수 있는 선택지가 될 수 있습니다.
앞으로 AI 서비스는 단순히 “더 똑똑한 모델”이 아니라, “어떤 워크로드에 최적화된 모델인가”가 중요한 기준이 됩니다.
Gemini 3.1 Flash-Lite는 그 변화의 흐름 속에서, 대규모 실전 환경을 겨냥한 전략적 모델이라고 볼 수 있습니다.

'인공지능' 카테고리의 다른 글
| GPT-5.3 Instant 업데이트 정리: 대화 품질·정확도·웹 통합 능력 전면 강화 (0) | 2026.03.04 |
|---|---|
| AI 에이전트 시대, Go가 주목받는 이유와 선택 배경 정리 (0) | 2026.03.04 |
| AI 이후의 데이터 엔지니어링: ETL을 넘어 ECL과 Context Architect로 (0) | 2026.03.03 |
| MCP는 죽었다? CLI가 다시 주목받는 이유와 실무에서의 선택 기준 (0) | 2026.03.03 |
| 알리바바 Qwen3.5-Medium 공개: 로컬 GPU에서 Sonnet 4.5급 성능 구현하는 오픈소스 LLM (0) | 2026.03.03 |



