대규모 문서나 파일을 기반으로 정확한 답변을 제공하는 RAG(Retrieval-Augmented Generation) 시스템을 구축하려면, 검색 품질과 문서 관리가 핵심입니다. 하지만 직접 인덱싱과 검색 인프라를 구성하는 것은 결코 간단하지 않습니다.
이번 글에서는 Grok Collections API를 중심으로, 이 API가 어떤 문제를 해결하는지, 어떤 방식으로 문서를 이해하고 검색하는지, 그리고 왜 최신 RAG 시스템에서 주목받는지에 대해 정리합니다. 특히 금융, 법률, 코드 분석과 같이 난도가 높은 영역에서 어떤 성능을 보이는지도 함께 살펴봅니다.
Grok Collections API란 무엇인가?
Grok Collections API는 전체 데이터셋을 업로드하고 검색할 수 있는 RAG 전용 API입니다.
PDF, 엑셀, 텍스트 파일, 대규모 코드베이스까지 하나의 컬렉션(Collection)으로 관리하며, 정확하고 빠른 검색을 지원합니다.
핵심은 개발자가 직접 인덱싱, 검색, 재색인 인프라를 관리하지 않아도 된다는 점입니다.
즉, RAG 애플리케이션을 만들기 위한 “검색 기반”을 API 차원에서 제공하는 것이 이 API의 목적입니다.
왜 Collections API가 필요한가?
RAG 시스템에서 가장 큰 문제는 **정확한 문서 검색 실패로 인한 환각(Hallucination)**입니다.
특히 다음과 같은 경우에는 난도가 급격히 올라갑니다.
- 금융 보고서처럼 숫자와 표가 많은 문서
- 법률 계약서처럼 긴 문장과 복잡한 참조 구조
- 수천 개 파일로 구성된 코드베이스
Collections API는 이런 환경을 전제로 설계된 시스템으로, 정확한 문서 검색과 구조 이해를 핵심 가치로 둡니다.
Indexing: 문서를 이해하는 방식이 다르다
1. 구조를 보존하는 문서 이해
Collections API는 단순히 텍스트만 추출하지 않습니다.
- OCR을 활용한 텍스트 추출
- PDF 레이아웃 구조 유지
- 엑셀 테이블의 계층 구조 인식
- 코드 파일의 문법 구조 파악
이를 통해 문서의 “의미”뿐 아니라 형태와 맥락까지 유지한 인덱싱이 가능합니다.
2. 스마트 파일 관리
- 파일 업로드, 업데이트, 다운로드 지원
- 파일 변경 시 자동 재인덱싱
- 항상 최신 상태의 컬렉션 유지
대규모 문서를 운영하는 환경에서 특히 중요한 부분입니다.
3. 다양한 파일 포맷 지원
PDF, Excel, 텍스트, 코드 파일 등 다양한 형식을 하나의 컬렉션으로 관리할 수 있습니다.
Retrieval: 목적에 맞는 검색 방식 선택
Collections API는 사용 목적에 따라 검색 방식을 선택할 수 있습니다.
1. Semantic Search
질문의 의미와 의도를 기반으로 검색합니다.
자연어 질문에 적합합니다.
2. Keyword Search
정확한 키워드 매칭이 필요할 때 사용합니다.
법률 조항이나 특정 용어 검색에 유리합니다.
3. Hybrid Search
Semantic + Keyword 검색을 결합한 방식입니다.
재정렬 모델(Reranker)과 Reciprocal Rank Fusion을 지원해 가장 높은 정확도를 목표로 합니다.
특히 표와 숫자가 많은 문서에서는 Hybrid Search가 강점을 보입니다.
실제 예시: 금융 문서 질의 응답
질문
What is our financial forecast for Q1 2026?
Collections API는 Financial_plan_2026.txt 문서에서
- Q1 2026 예상 성장률 15%
- 기술 투자와 공급망 최적화에 따른 매출 증가
- EBITDA 및 순이익률 개선 전망
과 같은 정확한 수치와 문맥을 포함한 정보를 검색 기반으로 제공합니다.
이는 단순 생성이 아니라, 실제 문서에서 근거를 찾아 응답하는 구조입니다.
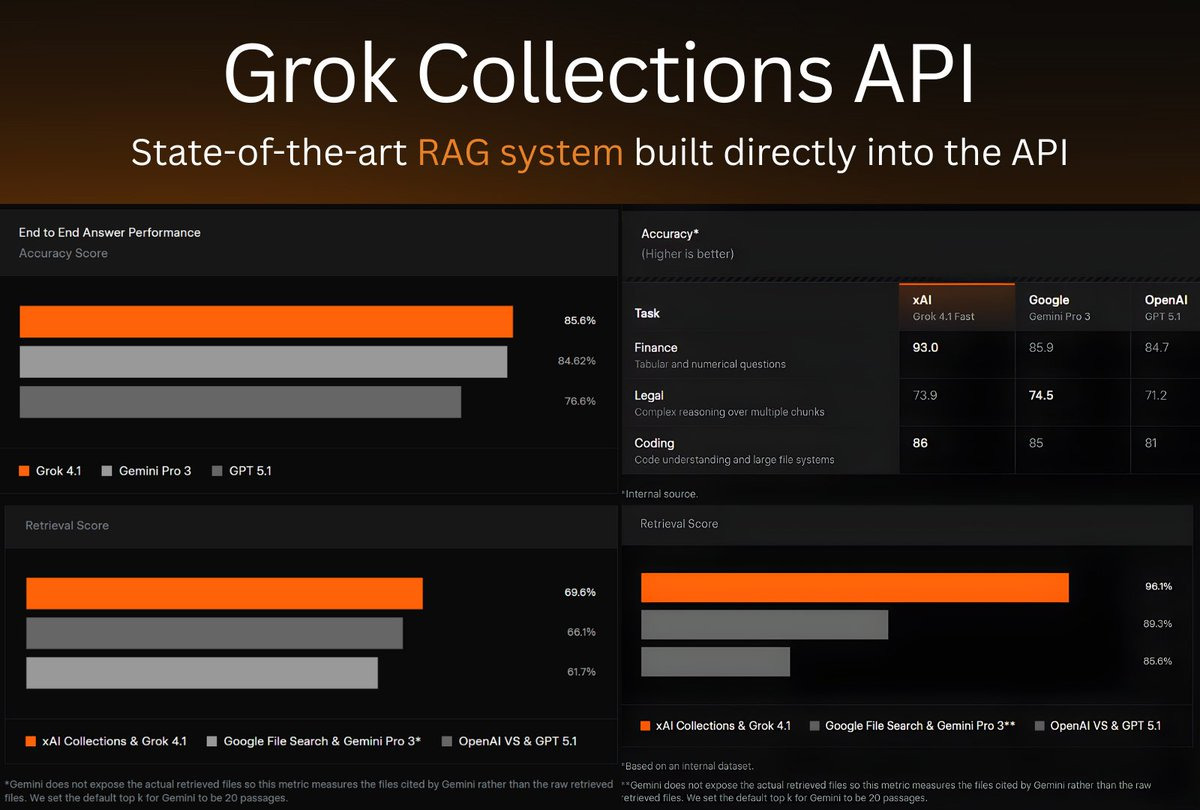
벤치마크로 보는 성능 경쟁력
Collections API는 실제 RAG 환경을 가정한 벤치마크에서 경쟁 모델 대비 높은 성능을 기록했습니다.
금융(Finance) – 표와 숫자 질의
- 정확도: 93.0%
- Google Gemini Pro 3: 85.9%
- OpenAI GPT 5.1: 84.7%
법률(Legal) – 복잡한 추론
- 정확도: 73.9%
- Google Gemini Pro 3: 74.5%
- OpenAI GPT 5.1: 71.2%
코드(Coding) – 대규모 코드베이스 이해
- 정확도: 86%
- Gemini Pro 3: 85%
- GPT 5.1: 81%
특히 긴 문서와 고밀도 정보 환경에서 강점을 보입니다.
전문 분야별 Retrieval 성능 비교
금융 분석
- xAI Collections & Grok 4.1: 96.1%
- Google File Search & Gemini Pro 3: 89.3%
- OpenAI VS & GPT 5.1: 85.6%
법률 분석 (LegalBench)
- xAI Collections & Grok 4.1: 69.6%
- Google: 66.1%
- OpenAI: 61.7%
코드 분석 (DeepCodeBench)
End-to-End 정확도
- Grok 4.1: 85.6%
- Gemini Pro 3: 84.62%
- GPT 5.1: 76.6%
데이터 프라이버시 정책
Collections에 저장된 사용자 데이터는
사용자의 명시적 동의 없이는 모델 학습에 사용되지 않습니다.
엔터프라이즈 환경에서 중요한 데이터 보호 요구사항을 충족하도록 설계되어 있습니다.
요금 정책 요약
- 파일 인덱싱 및 저장: 첫 주 무료
- 검색 비용: 1,000회당 $2.50
초기 테스트 및 PoC 단계에서 부담 없이 사용해볼 수 있는 구조입니다.
Collections API가 의미하는 것
Grok Collections API는 단순한 파일 검색 API가 아닙니다.
이 API는 **“정확한 검색이 가능한 RAG 시스템의 기반”**을 제공합니다.
- 대규모 문서에서도 신뢰할 수 있는 검색
- 구조를 이해하는 인덱싱
- 금융, 법률, 코드처럼 어려운 영역에서도 검증된 성능
RAG 시스템의 품질은 결국 검색에서 결정됩니다.
Collections API는 그 핵심을 API 레벨에서 해결하려는 시도이며, 향후 고정확도 AI 애플리케이션 구축에서 중요한 선택지가 될 것으로 기대됩니다.
https://x.ai/news/grok-collections-api

'인공지능' 카테고리의 다른 글
| Anthropic Agent Skills 리포지토리로 이해하는 AI 스킬 시스템 구조와 활용 방법 (0) | 2025.12.26 |
|---|---|
| Self-hosted AI Package란? 로컬 환경에서 AI 워크플로우를 구축하는 올인원 솔루션 (0) | 2025.12.24 |
| Magentic UI란 무엇인가? - 사람처럼 상호작용하는 웹 에이전트를 만드는 새로운 접근 (0) | 2025.12.24 |
| 에이전트 도구를 80% 제거했더니 성능이 더 좋아진 이유 ― Vercel이 말하는 ‘파일 시스템 에이전트’의 힘 (0) | 2025.12.24 |
| Qwen-Image-Edit-2511 공개: 오픈소스 이미지 편집 모델의 새로운 기준 (0) | 2025.12.24 |



