AI 모델의 발전 속도가 눈에 보일 정도로 빨라지는 요즘, 새로운 비전-언어 모델이 나올 때마다 “이번 모델은 무엇이 달라졌는가”라는 질문이 생길 수밖에 없습니다. 특히 이미지, 텍스트, 비디오를 통합하는 멀티모달 모델은 성능을 정확히 이해하기 어렵기 때문에 핵심만 정리된 정보가 더욱 필요합니다.
이번 글에서는 Alibaba Qwen 팀이 공개한 Qwen3-VL 기술 리포트 내용을 기반으로, 모델의 주요 특징과 기술적 변화, 실제 활용 가치까지 정리합니다.
Qwen3-VL란 무엇인가
Qwen3-VL은 Qwen 시리즈 중 가장 강력한 비전-언어 모델로 발표된 모델입니다. 텍스트·이미지·비디오가 섞인 입력을 최대 256K 토큰까지 한 번에 처리할 수 있으며, 순수 텍스트 이해 능력부터 장문 문서와 영상까지 아우르는 긴 문맥 처리, 그리고 복잡한 멀티모달 reasoning까지 지원합니다.
모델 라인업은 2B부터 32B의 Dense 모델, 그리고 30B-A3B와 235B-A22B 규모의 MoE(Mixture-of-Experts)까지 마련되어 있어 다양한 지연(latency)·품질 환경에서 선택적으로 활용할 수 있습니다.
Qwen3-VL의 핵심 특징
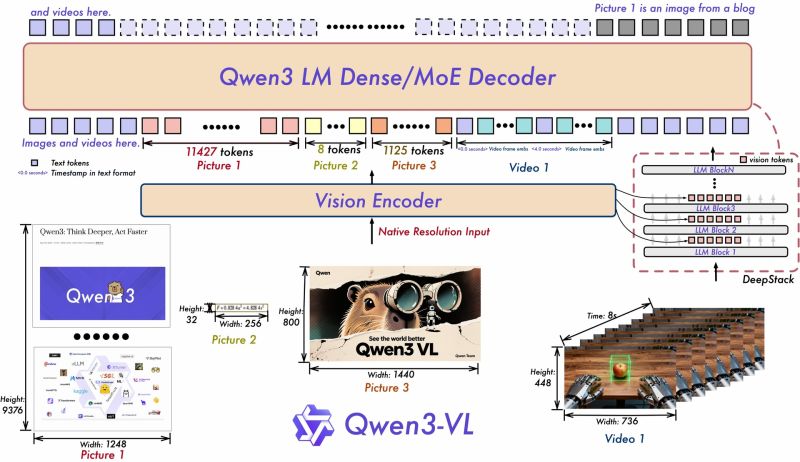
1. 256K 토큰의 Interleaved 멀티모달 컨텍스트
Qwen3-VL은 텍스트·이미지·영상을 섞어서 입력하는 ‘interleaved context’를 최대 256K 토큰까지 지원합니다.
이는 긴 보고서, 복잡한 멀티 이미지 설명, 심지어 수 시간 길이의 영상 분석까지 하나의 입력 흐름으로 처리할 수 있음을 의미합니다.
특히 장문 문서·매뉴얼·과거 대화 기록을 참조하여 지속적인 reasoning을 수행하는 데 매우 유리합니다.
2. 강화된 순수 텍스트 이해 능력
비전-언어 모델임에도 불구하고, Qwen3-VL은 단순 텍스트 전용 모델보다 더 나은 성능을 보이는 케이스를 보여줍니다.
이는 텍스트 처리 역량을 비전과 결합하며 약화시키지 않고 오히려 강화한 구조 덕분입니다.
3. 발전된 멀티모달 reasoning 성능
Qwen3-VL은 이미지, 여러 이미지, 영상 기반 reasoning에서 뛰어난 성능을 보이며, MMMU·MathVista·MathVision과 같은 대표적 멀티모달 벤치마크에서도 선도 그룹에 위치합니다.
이는 단순 시각 이해를 넘어, 복잡한 추론·계산·문제 해결까지 가능하다는 의미입니다.
Qwen3-VL의 기술적 업그레이드
1. Interleaved-MRoPE(공간·시간 표현 강화)
기존 MRoPE를 개선해 이미지·영상의 공간적·시간적 구조를 더 정확하고 조밀하게 표현하는 방식으로 업그레이드했습니다.
이를 통해 이미지와 영상의 위치 정보, 시간 흐름 정보 등을 더 정교하게 모델링할 수 있습니다.
2. DeepStack 기반 Vision-Language Alignment
DeepStack은 다단계 Vision Transformer(ViT) 특징을 결합하여 비전과 언어의 표현 간격을 좁히는 방식입니다.
즉, 이미지 구조를 해석하는 비전 모듈과 언어 모델 간 결합이 더 자연스럽고 강해졌습니다.
그 결과, 이미지 기반 질의응답, 객체 인식 문장 생성 등에서 오차가 줄어듭니다.
3. 텍스트 기반 Video Time Alignment
기존 T-RoPE 방식에서 더 발전해, 영상의 시간 정보를 명시적인 텍스트 기반 타임스탬프로 정렬하는 방식을 도입했습니다.
이 접근은 프레임 간 관계를 더 정확히 파악하며, “어느 시점에 어떤 일이 발생했는지”에 대한 질문을 더 잘 처리하도록 만듭니다.
Dense 모델 vs MoE 모델
Dense 모델
- 2B / 4B / 8B / 32B 제공
- 구조가 단순해 응답 지연이 낮고 안정적
- 모바일·경량 서버·실시간 응답 기반 서비스에 적합
MoE(Mixture-of-Experts) 모델
- 30B-A3B / 235B-A22B 제공
- 필요한 전문가(expert)만 활성화되므로 큰 모델임에도 효율적
- 고품질 reasoning·복잡한 멀티모달 작업에 강함
환경에 따라 빠른 응답이 필요하면 Dense, 고성능이 필요하면 MoE를 선택하는 식으로 유연하게 운영할 수 있습니다.
Qwen3-VL이 활용되는 영역
이미지 기반 reasoning
복잡한 장표, UI, 지도, 표 등 해석
이미지-텍스트 결합 분석
비디오 기반 분석
시간 흐름을 포함한 이벤트 감지
영상 기반 QA 및 장면 추출
코드·GUI 에이전트
PC·모바일 화면을 분석해 자동 동작을 수행하는 에이전트
비전 기반 디버깅·코드 생성
고도화된 OCR
32개 언어 지원
문서 디지털화, 표 추출, 데이터 인식에 활용 가능
Qwen3-VL은 멀티모달 모델의 한계를 크게 확장한 모델입니다.
256K 토큰의 장문 처리 능력, 강화된 텍스트 이해, 영상까지 포함하는 공간·시간 reasoning은 기존 모델 대비 명확한 수준 상승을 보여줍니다.
또한 Dense와 MoE를 나눠 다양한 환경에서 사용할 수 있도록 설계된 점도 실용적입니다.
이 모델은 앞으로 이미지 기반 의사결정, 자동화 에이전트, 영상 분석, 멀티모달 코딩 등 현실적인 AI 활용 시나리오에서 중요한 기반 엔진 역할을 할 것으로 보입니다.
특히 영상 분석과 장문 문맥 처리 능력을 동시에 갖춘 모델은 아직 많지 않다는 점에서, Qwen3-VL은 향후 멀티모달 AI의 기준점 역할을 할 가능성이 높습니다.
https://huggingface.co/papers/2511.21631
Paper page - Qwen3-VL Technical Report
Qwen3-VL Technical Report
huggingface.co

'인공지능' 카테고리의 다른 글
| 논문 작성 방식이 붕괴한다 - PaperDebugger에 연구 생산성 대폭발 방법 소개 (0) | 2025.12.06 |
|---|---|
| AG-UI: 에이전트 기반 애플리케이션을 위한 인터랙션 프로토콜 (0) | 2025.12.06 |
| Mixture of Experts와 NVIDIA GB200 NVL72가 만든 10배 성능 혁신: 차세대 AI 모델 구조의 현재와 미래 (0) | 2025.12.05 |
| 브라우저에서 실행되는 Postgres, PGlite 완전 정리 (0) | 2025.12.05 |
| Anthropic Interviewer: 1,250명 전문가가 말한 AI 활용의 진짜 변화 (0) | 2025.12.05 |



