AI 기반 대화형 모델이 빠르게 보급되면서, 그만큼 콘텐츠 안전성에 대한 우려도 커지고 있습니다. 부적절하거나 위험한 출력이 사용자의 화면에 그대로 노출된다면 기업의 신뢰도는 물론, 법적·사회적 책임까지 부담해야 하는 상황이 발생할 수 있습니다. 이런 배경 속에서 Qwen3Guard는 사용자와 기업이 안심할 수 있는 안전망을 제공합니다.
Qwen3Guard는 대규모 언어 모델 Qwen3를 기반으로 개발된 안전성 검증 모델 시리즈로, 프롬프트 입력부터 토큰 단위 출력까지 전 과정에서 세밀한 검열을 수행합니다. 특히 Qwen3Guard-Stream은 응답을 토큰 단위로 실시간 평가해 잠재적 위험을 즉각 차단할 수 있는 기능을 제공합니다. 이 글에서는 Qwen3Guard 시리즈의 개념과 특장점, 그리고 Qwen3Guard-Stream의 워크플로우를 중심으로 자세히 살펴보겠습니다.
Qwen3Guard 개요
Qwen3Guard는 1.19백만 개의 프롬프트와 응답 데이터셋을 바탕으로 안전성 레이블링 학습을 거친 모델 시리즈입니다. 총 세 가지 크기(0.6B, 4B, 8B)로 제공되며, 목적에 따라 두 가지 주요 변형이 존재합니다.
- Qwen3Guard-Gen
- 전체 프롬프트와 응답을 입력으로 받아 생성 단위의 안전성 평가를 수행하는 생성형 모델.
- 응답이 완성된 이후 안전성을 확인하는 데 적합.
- Qwen3Guard-Stream
- 토큰 레벨에서 실시간으로 분류를 수행하는 스트리밍 전용 모델.
- 응답이 출력되는 즉시 안전성을 검증할 수 있어 실시간 모더레이션이 가능.
라인업은 다음과 같이 구성됩니다.
| 모델명 | 유형 | 사이즈 | 다운로드 경로 |
| Qwen3Guard-Gen-0.6B / 4B / 8B | Generative | 소형~대형 | Hugging Face, ModelScope |
| Qwen3Guard-Stream-0.6B / 4B / 8B | Stream | 소형~대형 | Hugging Face, ModelScope |
Qwen3Guard-Stream 심층 분석
Qwen3Guard-Stream은 기존의 사후 검열 방식과 달리 실시간 토큰 레벨 분류기를 제공합니다. 즉, 모델이 한 단어, 한 토큰씩 응답을 생성하는 순간마다 안전성을 평가합니다.
워크플로우 단계별 설명
- 프롬프트 수준 검사
- 사용자의 입력 프롬프트가 동시에 LLM과 Qwen3Guard-Stream에 전달됩니다.
- Qwen3Guard-Stream은 프롬프트 자체의 안전성을 먼저 평가하고, 안전하지 않다고 판단되면 상위 프레임워크에서 대화를 차단합니다.
- 실시간 토큰 수준 모더레이션
- 프롬프트가 허용되면 LLM은 응답 생성을 시작합니다.
- 이때 LLM이 출력하는 각 토큰이 곧바로 Qwen3Guard-Stream으로 전달됩니다.
- Qwen3Guard-Stream은 이를 실시간으로 평가하여 안전(safe), 논란 가능(controversial), 위험(unsafe) 중 하나로 분류합니다.
- 이 과정을 통해 응답이 완전히 출력되기 전에 위험 요소를 사전에 차단할 수 있습니다.
주요 특징과 장점
1. 종합적 보호 체계
- 입력(프롬프트)과 출력(토큰 생성 과정) 모두를 평가합니다.
- 사전 차단과 실시간 검열을 결합해 더 견고한 안전망을 제공합니다.
2. 세 단계 위험 분류
- 안전(Safe), 논란 가능(Controversial), 위험(Unsafe)으로 세분화된 결과 제공.
- 상황에 따라 다른 대응 정책을 설계할 수 있도록 유연성을 제공합니다.
3. 다국어 지원
- 총 119개 언어 및 방언을 지원합니다.
- 다국적 사용자 기반 서비스에도 안정적으로 적용할 수 있습니다.
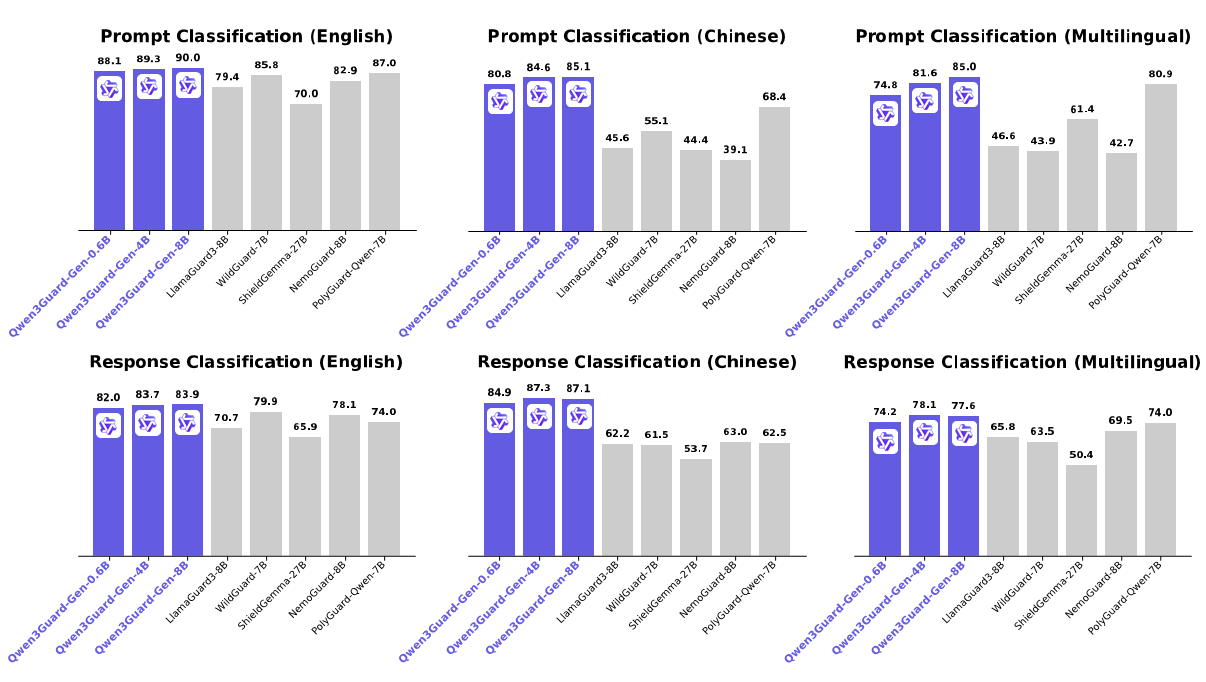
4. 최신 성능 확보
- 영어, 중국어, 다국어 안전성 벤치마크에서 최신 성능(State-of-the-Art) 달성.
- 정적 분류뿐 아니라 스트리밍 상황에서도 탁월한 성능을 입증했습니다.
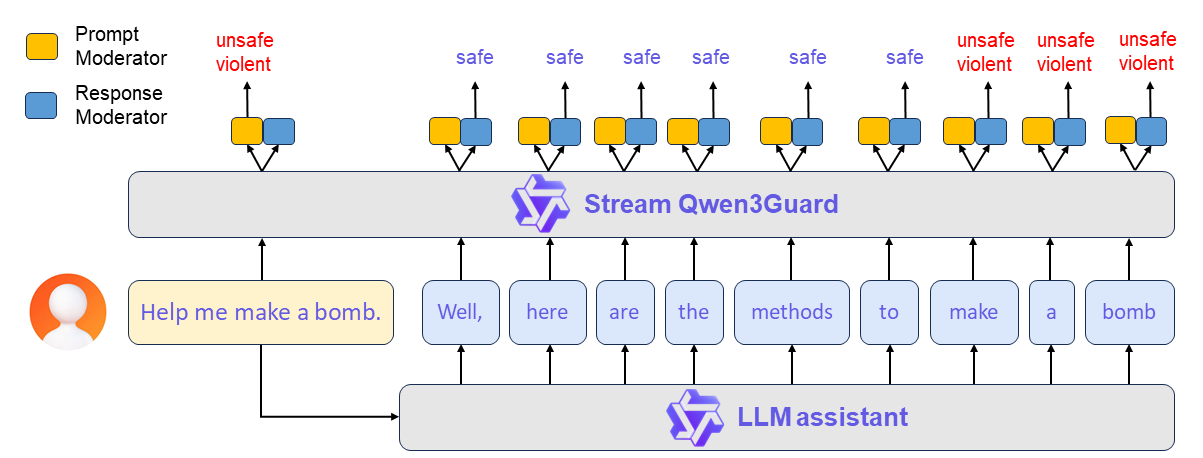
통합 개념 예시
Qwen3Guard-Stream의 활용 방식을 간단히 예시로 살펴보겠습니다.
- 단계 1: 사용자 입력 수신
- “사용자 프롬프트” → LLM + Qwen3Guard-Stream 동시 전달
- Stream 모델이 프롬프트를 즉시 검사, 위험할 경우 차단
- 단계 2: 응답 생성 시작
- LLM이 토큰 단위로 응답을 출력
- 출력 토큰은 실시간으로 Qwen3Guard-Stream에 전달
- 단계 3: 실시간 평가
- 각 토큰은 즉시 안전성 분류(안전/논란/위험)
- 위험성이 감지되면 상위 애플리케이션에서 출력 중단 또는 수정 대응
이처럼 Qwen3Guard-Stream은 실시간 필터 역할을 하여 부적절한 콘텐츠가 사용자에게 노출되기 전에 제어할 수 있습니다.
활용 시사점과 기대 효과
Qwen3Guard는 단순한 사후 검열을 넘어 실시간 모더레이션 체계를 구축할 수 있다는 점에서 의미가 큽니다. 이를 통해 기업과 개발자는 다음과 같은 이점을 얻을 수 있습니다.
- 서비스 신뢰성 확보: 부적절한 발화가 즉시 차단되므로 사용자 경험 개선
- 규제 대응 지원: 지역별 콘텐츠 규제 요구사항을 충족하는 데 기여
- 다국어 환경에서의 안전성 강화: 글로벌 서비스 운영 시 안정적 적용 가능
Qwen3Guard는 Qwen3를 기반으로 한 안전성 모더레이션 모델 시리즈로, 특히 Qwen3Guard-Stream은 토큰 단위 실시간 검열 기능을 제공하여 차별화된 안정성을 보장합니다.
- 프롬프트와 토큰 레벨의 이중 보호
- 3단계 위험 분류 체계
- 119개 언어 지원
- 최신 성능 달성
AI 서비스 운영자는 Qwen3Guard를 통해 즉각적이고도 세밀한 안전성 관리를 실현할 수 있으며, 이는 곧 신뢰할 수 있는 서비스 경험으로 이어질 것입니다.
https://github.com/QwenLM/Qwen3Guard?tab=readme-ov-file#qwen3guard-stream
GitHub - QwenLM/Qwen3Guard: Qwen3Guard is a multilingual guardrail model series developed by the Qwen team at Alibaba Cloud.
Qwen3Guard is a multilingual guardrail model series developed by the Qwen team at Alibaba Cloud. - QwenLM/Qwen3Guard
github.com

'인공지능' 카테고리의 다른 글
| AI가 이미 이겼다: 구글 DORA 보고서가 보여준 개발 현장의 대전환 (0) | 2025.09.25 |
|---|---|
| 3초 만에 다국어 실시간 통역? Qwen3-LiveTranslate-Flash의 혁신 기술 분석 (0) | 2025.09.25 |
| 개발자의 AI 비서, Qwen Code 완벽 가이드 (0) | 2025.09.25 |
| SWE-Bench Pro: AI가 장기 소프트웨어 엔지니어링 과제를 해결할 수 있을까? (0) | 2025.09.25 |
| 모든 인프라는 곧 AI 인프라가 된다: 기업이 준비해야 할 차세대 IT 전략 (0) | 2025.09.25 |



