
소프트웨어 엔지니어링은 단순히 코드 몇 줄을 작성하는 일이 아닙니다. 실제 기업 환경에서는 복잡한 비즈니스 로직, 여러 파일에 걸친 패치, 그리고 장기적인 문제 해결 능력이 요구됩니다. 최근 공개된 SWE-Bench Pro는 이런 현실적인 난제를 반영한 새로운 벤치마크로, 기존의 SWE-Bench를 넘어서는 수준의 복잡성을 갖추고 있습니다. 이 글에서는 SWE-Bench Pro가 무엇인지, 어떤 특징을 갖고 있으며, 왜 중요한지 살펴봅니다.
SWE-Bench Pro란 무엇인가?
SWE-Bench Pro는 기존 SWE-Bench를 기반으로 만들어진 차세대 소프트웨어 엔지니어링 벤치마크입니다.
- 문제 규모: 총 1,865개 문제로 구성
- 출처: 41개 적극적으로 유지·관리되는 저장소에서 수집 (비즈니스 애플리케이션, B2B 서비스, 개발자 도구 등)
- 데이터셋 구분
- Public set: 11개 저장소 기반, 공개 접근 가능
- Held-out set: 12개 저장소 기반, 비공개
- Commercial set: 18개 독점 저장소 기반, 스타트업과 파트너십을 통해 확보
SWE-Bench Pro의 특징
1. 현실적인 엔터프라이즈 수준 문제 반영
- 단순한 알고리즘 문제가 아닌, 실제 현업 개발자가 며칠씩 투자해야 할 문제를 다룹니다.
- 여러 파일을 수정하거나 대규모 코드 변경을 요구하는 경우가 많습니다.
2. 장기 과제(Long-horizon tasks)
- 짧은 시간 내 해결이 불가능하며, 맥락 이해와 긴 의사결정 과정이 필요합니다.
- 기존 모델들이 잘 해결하지 못했던 영역을 집중적으로 평가합니다.
3. 인간 검증(Human-verified)
- 모든 과제가 전문가 검증을 거쳐 실제로 해결 가능하다는 점을 보장합니다.
- 단순한 벤치마크가 아닌, 현업 복잡성을 반영한 신뢰성 있는 데이터셋입니다.
4. 오염 저항성(Contamination-resistant)
- 학습 데이터와의 중복 문제를 최소화하여, AI 모델의 순수한 능력을 평가할 수 있습니다.
AI 모델 성능 평가
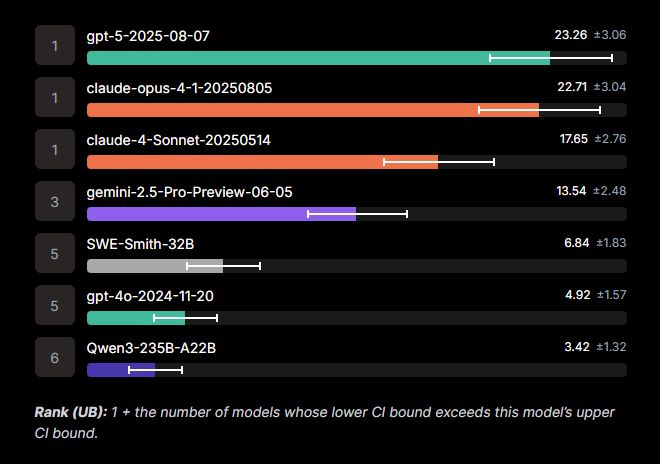
SWE-Bench Pro는 최신 AI 코딩 모델들을 평가하는 데 사용되었습니다.
- Pass@1 기준 성능: 전체적으로 25% 미만
- GPT-5 성능: 23.3%로 가장 높은 점수를 기록
- 결론: 현존 AI 모델은 복잡한 소프트웨어 엔지니어링 문제 해결에 한계가 있음
연구진은 모델의 실패 패턴을 분석하기 위해 AI 에이전트가 문제를 풀다 실패한 과정을 수집하고, 이를 클러스터링하여 실패 원인을 체계적으로 분류했습니다.
왜 중요한가?
현실적인 기업 환경에서는 단순한 코드 자동 생성보다, 복잡한 프로젝트 전반을 관리하고 해결할 수 있는 AI가 필요합니다. SWE-Bench Pro는 바로 이런 영역에서 AI가 실제 엔지니어 수준의 업무를 수행할 수 있는지 검증하는 첫걸음이 됩니다.
SWE-Bench Pro는 기존 AI 모델들의 성능을 냉정하게 평가할 수 있는 벤치마크입니다.
- 현실적이고 장기적인 문제를 반영
- 인간 검증을 통해 신뢰성 확보
- AI 모델들의 한계와 실패 패턴을 명확히 드러냄
향후 SWE-Bench Pro는 진정한 자율 소프트웨어 엔지니어링 에이전트 개발을 위한 시험대가 될 것입니다. 아직은 AI가 전문 개발자를 완전히 대체하기는 어렵지만, 이 벤치마크를 통해 AI의 한계와 가능성을 동시에 확인할 수 있습니다.
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
scale.com

'인공지능' 카테고리의 다른 글
| Qwen3Guard: 실시간 스트리밍 모더레이션으로 AI 안전성을 강화하는 방법 (0) | 2025.09.25 |
|---|---|
| 개발자의 AI 비서, Qwen Code 완벽 가이드 (0) | 2025.09.25 |
| 모든 인프라는 곧 AI 인프라가 된다: 기업이 준비해야 할 차세대 IT 전략 (0) | 2025.09.25 |
| 컨텍스트 최적화와 서브에이전트 전략: 대규모 코드베이스를 다루는 새로운 접근법 (0) | 2025.09.25 |
| Qwen3-VL: 멀티모달 AI의 새로운 기준, 시각과 언어를 넘어 ‘이해와 실행’으로 (0) | 2025.09.25 |



