인공지능 모델이 빠르게 발전하면서 방대한 양의 데이터를 다루는 일이 일상화되고 있습니다. 그러나 문제는 단순히 데이터를 보관하거나 검색하는 것이 아니라, 맥락을 이해하고 적절한 시점에 필요한 정보를 꺼내 활용하는 것입니다. 기존 RAG(Retrieval-Augmented Generation)는 쿼리에 맞는 정보를 불러오는 데 효과적이지만, 데이터 전반의 맥락을 고려하거나 장기적인 문맥을 유지하는 데 한계가 있었습니다.
이러한 한계를 극복하기 위해 등장한 것이 MemoRAG입니다. MemoRAG는 초장기 메모리 모델을 기반으로 하여 단순한 검색을 넘어, 데이터 전체의 맥락을 기억하고 쿼리에 필요한 단서를 찾아내는 방식으로 더 정교한 답변을 제공합니다. 이 글에서는 MemoRAG의 개념, 특징, 기능, 업데이트 현황, 사용 예시를 차례대로 살펴보고, 나아가 어떤 기대 효과를 가져올 수 있을지 정리하겠습니다.
MemoRAG란 무엇인가?
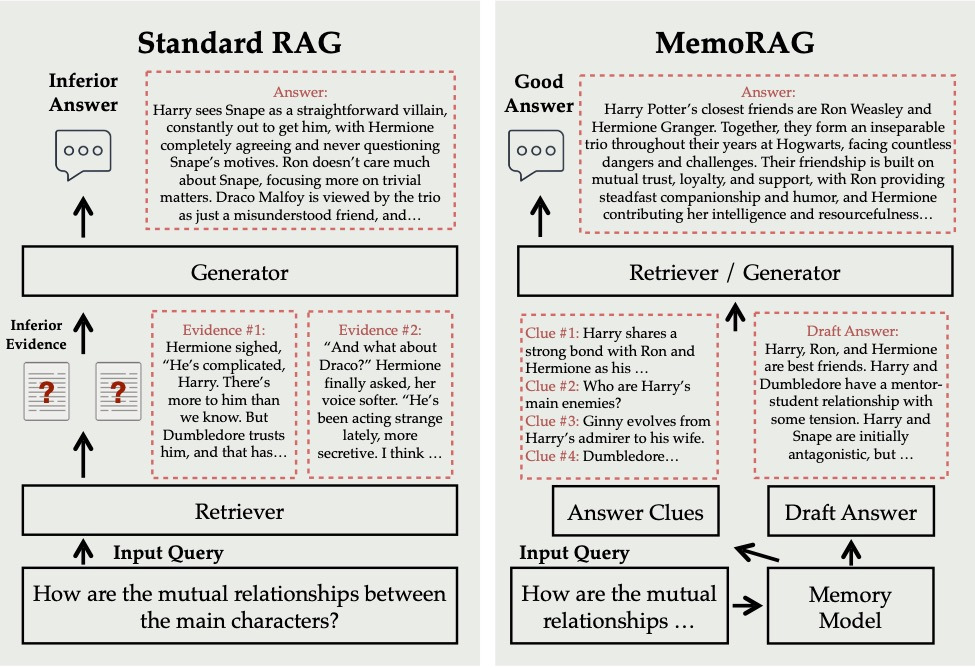
MemoRAG는 기존 RAG의 구조적 한계를 보완하고 확장한 새로운 프레임워크입니다.
- 기존 RAG: 사용자의 질문에 맞는 문서나 데이터를 검색해 해당 정보를 바탕으로 답변을 생성
- MemoRAG: 데이터 전체를 전역 메모리(Global Memory)에 저장해 두고, 질문이 들어왔을 때 관련 단서를 회상(recall)하여 보다 풍부하고 정확한 답변을 생성
즉, MemoRAG는 단순히 검색하는 시스템이 아니라, 마치 사람이 과거 경험을 떠올리듯 방대한 데이터 속에서 맥락을 기억하고 필요한 정보를 꺼내는 시스템이라고 이해할 수 있습니다.
특히 MemoRAG는 TheWebConf 2025에서 논문이 채택될 만큼 그 기술적 혁신성을 인정받았습니다.
MemoRAG의 주요 특징
1. Global Memory: 전역 메모리 처리
MemoRAG의 가장 큰 강점은 전역 메모리 구조입니다.
- 최대 100만 토큰을 한 번에 처리할 수 있어 대규모 데이터셋에서도 맥락을 유지할 수 있습니다.
- 단순히 특정 구간의 데이터를 검색하는 것이 아니라, 전체적인 흐름과 관계성을 고려한 답변이 가능합니다.
2. 최적화 가능성과 유연성
MemoRAG는 새로운 작업 환경에 빠르게 적응할 수 있습니다.
- 수 시간 정도의 추가 학습만으로 새로운 도메인에 최적화된 성능을 발휘할 수 있습니다.
- 이를 통해 다양한 산업 분야와 업무 환경에 유연하게 적용할 수 있습니다.
3. 맥락 단서(Contextual Clues) 생성
MemoRAG는 전역 메모리에서 질문과 관련된 단서를 생성합니다.
- 단순히 데이터를 끌어오는 것이 아니라, 질문과 데이터 사이의 연결고리를 파악해 증거 기반의 답변을 제공합니다.
- 복잡한 데이터셋에서도 사용자가 쉽게 발견하지 못하는 숨은 인사이트를 드러낼 수 있습니다.
4. 효율적인 캐싱 메커니즘
컨텍스트를 미리 채우는 과정에서 최대 30배 빠른 속도를 보여줍니다.
- 캐싱(chunking), 인덱싱, 인코딩을 지원하여 반복 작업에서 특히 높은 효율성을 발휘합니다.
- 이를 통해 대규모 데이터를 다루는 환경에서 처리 속도를 획기적으로 개선할 수 있습니다.
5. 컨텍스트 재사용 기능
한 번 인코딩한 긴 컨텍스트를 반복적으로 사용할 수 있습니다.
- 동일한 데이터셋을 여러 번 접근해야 하는 업무 환경에서 성능 저하 없이 안정적으로 활용할 수 있습니다.
- 이는 데이터 분석이나 반복적인 QA 작업에서 큰 장점이 됩니다.
업데이트 및 로드맵
MemoRAG는 2024년 9월에 프로젝트가 시작된 이후 꾸준히 기능이 추가되고 있습니다.
- 2025.04.23: 학습 스크립트 및 학습 데이터셋 공개
- 2024.09.21: Lite 모드 도입, 수백만 토큰 규모의 메모리 기반 RAG 처리 가능
- 2024.09.13: Meta-Llama-3.1 기반 메모리 모델 추가
- 2024.09.10: 기술 보고서 공개
- 2024.09.09: Google Colab 무료 체험 지원
- 2024.09.05 ~ 09.03: Qwen2 및 Mistral 기반 메모리 모델 제공
- 2024.09.01: 프로젝트 공식 시작
이처럼 MemoRAG는 단기간에 빠른 발전을 이루며 다양한 모델과 기능을 지원하고 있습니다.
기대 효과 및 시사점
MemoRAG가 제공하는 기술적 혁신은 여러 방면에서 의미가 큽니다.
- 데이터 관리 효율성 향상
기업이나 연구 기관이 방대한 데이터를 관리하고 활용하는 데 있어 MemoRAG는 기존보다 훨씬 빠르고 정확한 검색 결과를 제공합니다. - 정확하고 풍부한 답변 생성
단순히 쿼리에 맞는 결과를 보여주는 것을 넘어, 데이터 전체 맥락을 반영한 답변을 생성합니다. - 다양한 분야에서의 활용 가능성
지식 관리, 고객 응대, 연구 데이터 분석, 대화형 AI 등 여러 산업 분야에 폭넓게 적용할 수 있습니다.
앞으로 MemoRAG의 발전은 차세대 RAG 기술의 표준을 제시하며, AI가 단순한 검색 도구를 넘어 지식을 기억하고 활용하는 지능형 시스템으로 나아가는 길을 열어갈 것입니다.
MemoRAG는 기존 RAG의 한계를 넘어, 방대한 데이터를 기억하고 맥락을 이해하며, 더 정교한 지식 검색을 가능하게 하는 차세대 프레임워크입니다. 빠른 처리 속도, 강력한 메모리 구조, 높은 적응성은 향후 AI 연구와 산업 현장에서 큰 가치를 만들어낼 것입니다.
앞으로 MemoRAG가 발전함에 따라 데이터 활용 방식은 더욱 혁신적으로 변할 것이며, 이는 AI 기술의 새로운 전환점이 될 것입니다.
GitHub - qhjqhj00/MemoRAG: Empowering RAG with a memory-based data interface for all-purpose applications!
Empowering RAG with a memory-based data interface for all-purpose applications! - qhjqhj00/MemoRAG
github.com

'인공지능' 카테고리의 다른 글
| Qwen3-TTS-Flash: 다국어·다방언을 넘나드는 초고속 AI 음성 합성 모델 (0) | 2025.09.24 |
|---|---|
| 에이전틱 AI, 왜 실패하는가? 기업 도입 실패 원인 4가지와 해결 방향 (0) | 2025.09.24 |
| Qwen3-Omni: 텍스트·이미지·오디오·비디오를 하나로 통합한 차세대 AI 모델 (0) | 2025.09.24 |
| 블랙박스를 넘어: 금융 의사결정을 위한 LLM 기반 모델, Trading-R1 (0) | 2025.09.24 |
| 벡터 검색을 넘어: 텐서 기반 검색이 여는 AI의 미래 (0) | 2025.09.23 |



