금융 시장에서 AI를 활용하는 시도는 꾸준히 이어져 왔습니다. 하지만 현실에서는 두 가지 큰 문제가 존재합니다. 퀀트 모델은 성능은 뛰어나지만 너무 복잡해 사람이 이해하기 어렵고, 일반 대규모 언어 모델(LLM)은 읽기 좋은 텍스트를 만들어내지만 실제 거래 전략으로 이어지지 않는다는 한계가 있습니다. 이 간극을 메우기 위해 등장한 것이 Trading-R1입니다. 이 모델은 금융 데이터를 구조적으로 해석해 읽기 쉬운 분석을 제공하면서도, 그 분석을 실제 매매 의사결정으로 연결할 수 있도록 설계되었습니다.
이번 글에서는 Trading-R1의 개념과 학습 과정, 그리고 실제 성능과 시사점을 살펴보겠습니다.
Trading-R1이란 무엇인가
Trading-R1은 금융 도메인에 특화된 40억 파라미터 규모의 LLM 기반 모델입니다. 핵심 목표는 **명확한 투자 분석(Thesis)**을 작성하고, 이를 근거로 **실제 매매 행동(Strong Buy, Buy, Hold, Sell, Strong Sell)**을 도출하는 것입니다.
이 모델은 18개월 동안 14개 주요 종목을 대상으로 10만 건 이상의 사례를 학습하며, 백테스트에서 기존 소형 및 대형 모델보다 더 나은 위험 조정 수익률과 작은 낙폭(Max Drawdown)을 보였습니다.
Trading-R1이 해결하는 문제
- 퀀트 모델의 한계: 수학적 계산과 통계 기반으로 높은 성능을 보이지만 결과가 블랙박스 형태라 이해하기 어렵습니다.
- 일반 LLM의 한계: 글은 유려하지만 실제 투자 결정을 내릴 수 있는 구조화된 분석을 제공하지 못합니다.
Trading-R1은 이 두 문제를 동시에 해결합니다. 구조화된 투자 논리를 작성하면서, 각 주장이 반드시 근거를 포함하도록 강제하고, 최종적으로 매매 결정을 제시합니다.
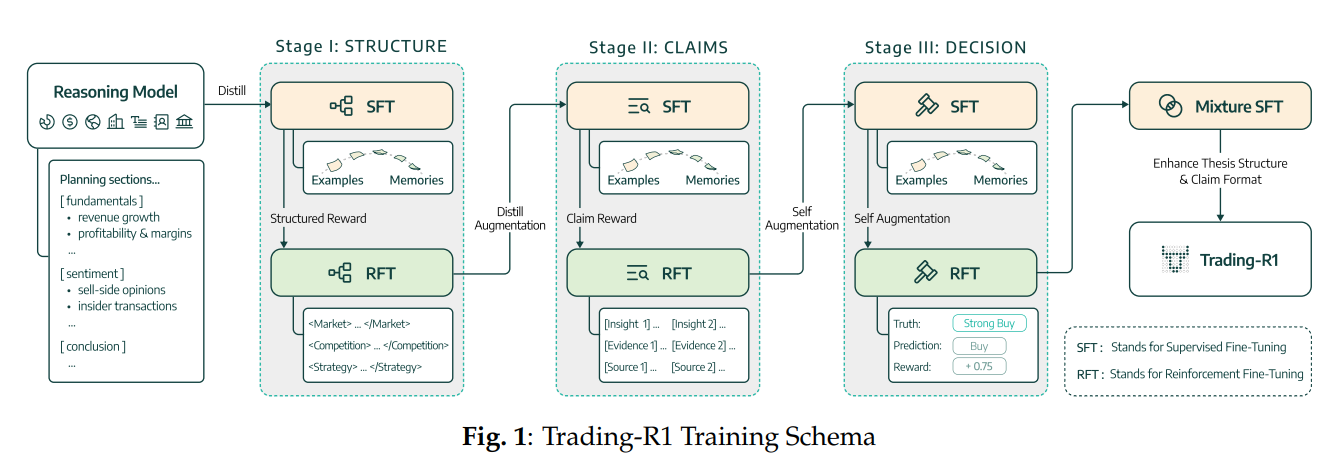
3단계 학습 파이프라인
1. 구조(Structure) 학습
모델이 투자 논리를 작성할 때는 반드시 일정한 포맷을 따릅니다.
- 시장 동향(Market Trends)
- 기업 펀더멘털(Fundamentals)
- 시장 심리(Sentiment)
각 항목은 구분되어 있으며, 분석은 산만한 나열이 아니라 구조화된 보고서 형태로 작성됩니다.
2. 주장(Claims) 학습
모든 주장은 증거를 동반해야 합니다.
예: “매출이 성장하고 있다”라는 주장을 한다면, 반드시 해당 수치를 맥락 데이터에서 인용해야 합니다. 이를 통해 근거 없는 추측이나 환상을 줄입니다.
3. 의사결정(Decision) 학습
구조화된 분석과 증거 기반 주장을 바탕으로 매매 결정을 내립니다. 가능한 선택지는 Strong Buy, Buy, Hold, Sell, Strong Sell 다섯 가지입니다. 모델은 실제 시장 결과와 비교해 정확하면 보상, 틀리면 패널티를 받습니다.
학습 방식의 특징
지식 전이(Distillation)
Trading-R1은 더 강력한 모델(GPT-4, Qwen 등)에서 나온 고품질 reasoning을 압축해 학습합니다.
- 투자 논리 전이(Thesis Distillation): 뉴스, 재무제표, 평판 데이터 등에서 큰 모델이 생성한 제안이 정확하다면 그대로 학습 예시로 채택합니다.
- 역추론 전이(Reverse Distillation): 최종 매매 추천에서 다시 큰 모델이 reasoning을 풀어내고, 이를 작은 모델이 흡수합니다.
이 과정을 통해 작은 모델도 명확하고 근거 있는 분석 능력을 갖추게 됩니다.
지도 학습(Supervised Fine-Tuning)
샘플링된 금융 데이터를 기반으로, 모델은 구조화된 분석과 매매 결정을 정해진 템플릿에 따라 출력합니다. 이를 통해 항상 일관성 있는 보고서 형식을 유지합니다.
강화학습(Reinforcement Learning)
모델의 출력은 구조의 질, 증거 기반 주장, 의사결정 정확도 세 가지 기준으로 보상 또는 패널티를 받습니다. 단순히 정답을 맞히는 것이 아니라, 읽기 쉽고 근거 있는 분석을 유지하면서 정확한 매매 결정을 내리도록 학습됩니다.
성능 검증 결과
Trading-R1은 NVDA, AAPL, AMZN, META, MSFT, SPY 등 주요 종목에서 테스트되었습니다. 결과는 다음과 같은 점에서 두드러집니다.
- Sharpe Ratio 개선: 위험 대비 수익률이 향상됨.
- 낙폭(Max Drawdown) 감소: 손실 구간의 크기를 줄임.
- 전통 모델 대비 우수한 안정성: 작은 모델과 큰 모델을 모두 능가하는 성능.
저자들은 이 모델을 초단타 거래(HFT) 자동화가 아니라, 연구 지원 도구로서 위치 지었습니다. 즉, 투자자가 참고할 수 있는 신뢰성 있는 분석과 의사결정 근거를 제공하는 것이 목표입니다.
금융 AI의 새로운 방향
Trading-R1은 단순히 매매 추천을 하는 도구가 아니라, 이해하기 쉬운 구조화된 분석을 제공하면서 실제 의사결정으로 이어지게 만든 첫 시도라 할 수 있습니다. 기존 퀀트 모델의 불투명성과 일반 LLM의 실행력 부족을 동시에 극복한 것입니다.
앞으로 이 모델은 금융 애널리스트와 투자자들이 더 빠르고 명확한 의사결정을 내리는 데 중요한 도구가 될 가능성이 큽니다. 동시에 LLM을 복잡한 금융 의사결정에 접목하는 새로운 연구 방향을 제시한다는 점에서 의미가 큽니다.
Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning
Developing professional, structured reasoning on par with human financial analysts and traders remains a central challenge in AI for finance, where markets demand interpretability and trust. Traditional time-series models lack explainability, while LLMs fa
arxiv.org

'인공지능' 카테고리의 다른 글
| MemoRAG: 차세대 RAG를 위한 메모리 기반 지식 검색 혁신 (0) | 2025.09.24 |
|---|---|
| Qwen3-Omni: 텍스트·이미지·오디오·비디오를 하나로 통합한 차세대 AI 모델 (0) | 2025.09.24 |
| 벡터 검색을 넘어: 텐서 기반 검색이 여는 AI의 미래 (0) | 2025.09.23 |
| Backlog.md: Git 리포지토리만 있으면 완성되는 로컬 퍼스트 프로젝트 관리 도구 (0) | 2025.09.23 |
| AI 에이전트 시대, 코드 리뷰가 진짜 경쟁력이 되는 이유 (0) | 2025.09.23 |



