음성 AI 분야는 최근 몇 년간 가장 빠르게 발전하는 영역 중 하나입니다. 특히 실시간 음성 대화와 감정 표현까지 가능한 AI 모델은 차세대 상호작용의 핵심으로 꼽히죠. 중국의 AI 스타트업 스텝펀(StepFun AI) 은 이를 한 단계 끌어올리며, 오픈소스로 공개된 스텝-오디오 2 미니(Step-Audio 2 Mini) 를 선보였습니다.
이 모델은 단순히 말을 인식하거나 읽어주는 수준을 넘어, 실제 사람처럼 억양·감정·스타일까지 반영하며, 성능에서도 GPT-4o 오디오 모델을 능가하는 결과를 보여 업계의 주목을 받고 있습니다.
이번 글에서는 스텝-오디오 2 미니의 기술적 특징, 성능, 활용 가능성을 차근차근 살펴보겠습니다.
스텝-오디오 2 미니란?
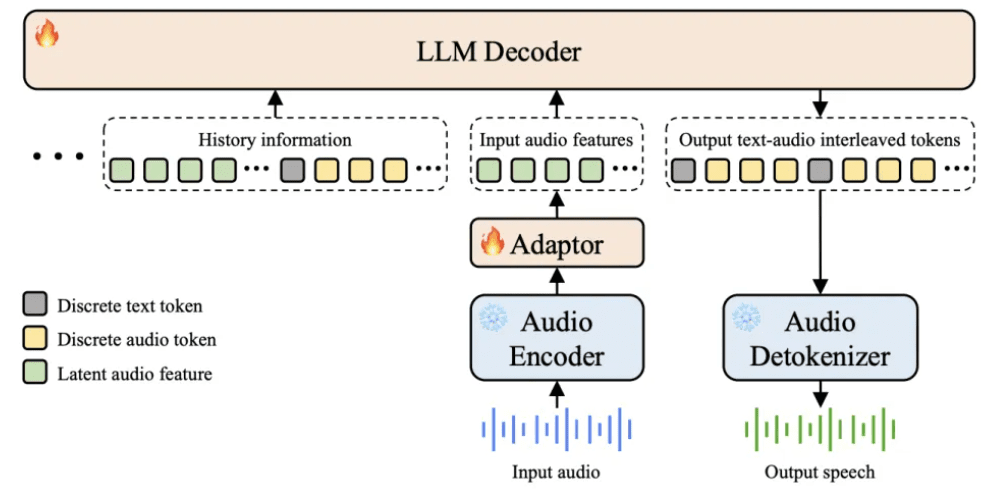
스텝-오디오 2 미니는 80억 매개변수를 가진 오픈소스 음성-음성 언어 모델입니다.
기존 음성 모델은 보통 다음과 같은 파이프라인을 거칩니다:
- ASR(자동음성인식) → LLM(언어모델 추론) → TTS(텍스트 음성 변환)
하지만 스텝-오디오 2 미니는 이를 단일 모델로 통합했습니다. 멀티모달 이산 토큰 모델링(Multimodal Discrete Token Modeling) 을 활용해 텍스트와 오디오 토큰을 같은 스트림에서 처리할 수 있습니다.
주요 특징
- 실시간 음성 스타일 전환: 상황에 따라 목소리 톤과 감정을 자연스럽게 바꿀 수 있음.
- 일관성 유지: 억양, 운율, 의미, 감정을 하나의 흐름으로 연결.
- 현실감 있는 감정 표현: 속삭임·슬픔·흥분 등 다양한 감정 톤 구현.
- 멀티모달 검색 RAG 지원: 웹 검색과 오디오 검색을 통해 사실 기반 응답 및 음성 스타일 모방 가능.
방대한 데이터 학습 기반
스텝-오디오 2 미니는 단순히 모델 구조만 혁신적인 게 아니라, 학습 데이터와 과정에서도 강점을 가집니다.
- 학습 데이터 규모:
- 1.356조 토큰(텍스트+오디오)
- 800만 시간 이상의 오디오
- 5만 명 이상의 화자 데이터
- 사전학습 커리큘럼:
- ASR, TTS, 음성 번역, 감정 라벨 대화 합성 등을 단계별로 학습
- 이를 통해 텍스트 추론 능력과 오디오 표현 능력을 동시에 강화
즉, 단순히 말을 “따라 하는” 수준이 아니라, 언어와 오디오 모두에 깊이 있게 이해할 수 있도록 설계된 것입니다.
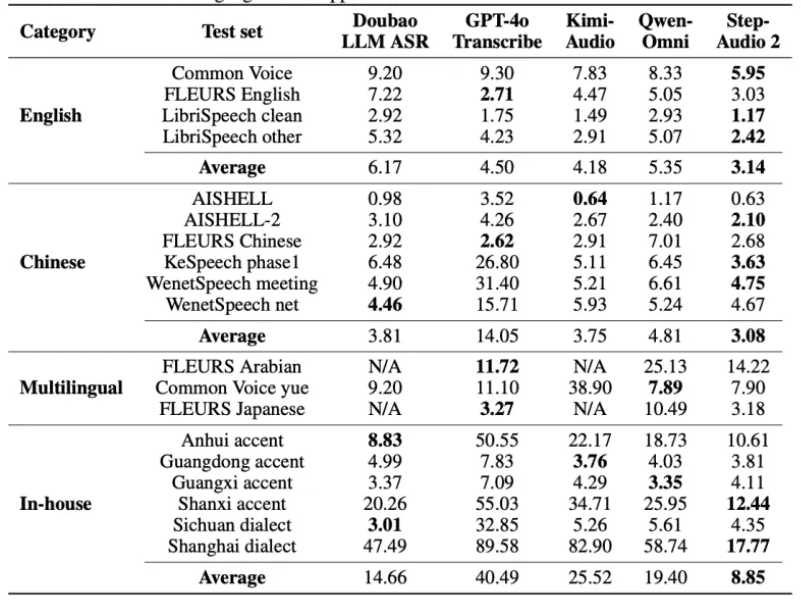
성능 벤치마크 결과
스텝-오디오 2 미니는 다양한 벤치마크에서 경쟁 모델을 압도했습니다.
- 음성 인식(ASR):
- 영어·아랍어 WER 평균 3.14%
- 중국어·광둥어·일본어 CER 평균 3.08%
- GPT-4o, Qwen-Omni를 능가
- 오디오 이해(MMAU):
- 점수 78.0 (GPT-4o 오디오 모델보다 우위)
- 음성 번역(CoVoST 2, CVSS):
- BLEU 점수 각각 39.26, 30.87 → GPT-4o보다 높음
- 대화 성능(URO-Bench):
- 중국어: 83.3 (기본), 68.2 (전문가) → 업계 최고 수준
- 영어: GPT-4o와 유사한 84.5
- 부가 언어 능력(감정·스타일 등):
- 정확도 83.1% (GPT-4o는 43.5%)
즉, 정확도·이해도·대화 자연스러움에서 모두 뛰어난 성과를 보인 셈입니다.
오픈소스로서의 가치
스텝-오디오 2 미니는 허깅페이스(HuggingFace) 를 통해 누구나 접근할 수 있습니다.
- 상업적 사용 가능
- 수정 및 배포 자유로움
이는 기업이나 개발자가 새로운 음성 기반 서비스(예: AI 상담원, 게임 NPC 음성, 실시간 통역기)를 만드는 데 큰 기회를 제공합니다.
스텝펀의 스텝-오디오 2 미니는 단순한 기술 공개가 아닙니다.
- 음성 AI의 대중화를 촉진
- 실시간 상호작용 UX 혁신 가능
- 오픈소스 생태계 속에서 다양한 파생 솔루션과 서비스 개발 기대
무엇보다 GPT-4o 오디오 모델을 뛰어넘는 성능을 오픈소스로 공개했다는 점에서, 글로벌 AI 경쟁 구도에도 큰 파장을 일으킬 것으로 보입니다.
https://huggingface.co/stepfun-ai/Step-Audio-2-mini
stepfun-ai/Step-Audio-2-mini · Hugging Face
Introduction Step-Audio 2 is an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation, presented in the paper Step-Audio 2 Technical Report. Advanced Speech and Audio Understanding: Promising
huggingface.co

'인공지능' 카테고리의 다른 글
| 데이터로 물리 법칙을 찾다: PDE-FIND로 알아보는 데이터 기반 편미분방정식 발견 (0) | 2025.09.15 |
|---|---|
| Cognita: 실험에서 프로덕션까지 RAG 시스템을 손쉽게 전환하는 오픈소스 프레임워크 (0) | 2025.09.15 |
| Temperature 하이퍼파라미터 값을 0으로 설정해도LLM의 추론 결과가 비결정론적인 이유 - 완전히 정복하기 !! 핵심 원인에서 솔루션까지 (0) | 2025.09.15 |
| GitLab Knowledge Graph: 코드베이스를 이해하는 새로운 패러다임 (0) | 2025.09.15 |
| AI Quests: 청소년을 위한 새로운 AI 리터러시 학습 모험 (0) | 2025.09.15 |



