대규모 언어 모델(LLM)을 실제 서비스 환경에 배포하려면 단일 GPU 실행만으로는 한계가 있습니다. 모델 크기가 커질수록 여러 GPU, 여러 노드에 걸쳐 병렬로 모델을 실행하고 요청을 처리하는 분산 아키텍처가 필요합니다. vLLM은 이를 위해 텐서 병렬화(TP), 데이터 병렬화(DP), 그리고 **멀티 프로세스 실행기(MultiProcExecutor)**를 기반으로 한 분산 서빙 인프라를 제공합니다.
이번 글에서는 vLLM을 분산 환경에서 어떻게 실행하고, API 서버까지 포함된 요청-응답 과정이 어떻게 동작하는지 구체적으로 살펴보겠습니다.
분산 환경에서의 기본 설정
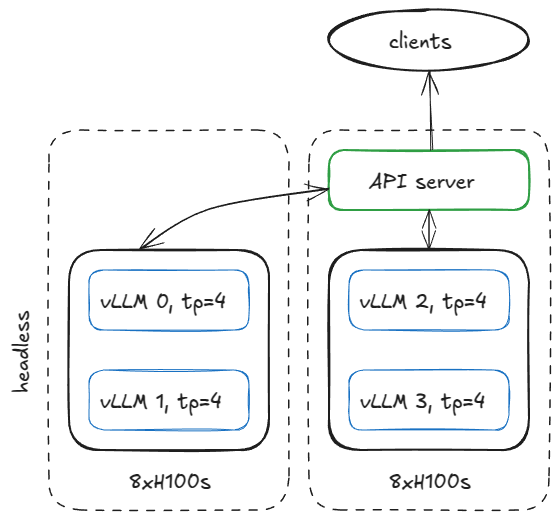
예를 들어, 두 개의 H100 GPU 노드에서 네 개의 vLLM 엔진을 실행한다고 가정해봅시다. 모델은 TP=4 구성이 필요하다고 할 때, 다음과 같은 방식으로 노드를 나눌 수 있습니다.
- 첫 번째 노드 (headless 모드, API 서버 없음)
vllm serve <model-name> \
--tensor-parallel-size 4 \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 0 \
--data-parallel-address <master-ip> \
--data-parallel-rpc-port 13345 \
--headless
- 두 번째 노드 (API 서버 포함)
vllm serve <model-name> \
--tensor-parallel-size 4 \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address <master-ip> \
--data-parallel-rpc-port 13345
즉, 첫 번째 노드는 순수 엔진 실행만 담당하고, 두 번째 노드에서 API 서버를 구동하여 외부 요청을 처리하게 됩니다.

Headless 노드: 엔진 코어 실행
Headless 모드에서 vLLM은 CoreEngineProcManager를 실행하여 여러 프로세스를 띄우고, 각 프로세스는 EngineCoreProc.run_engine_core를 수행합니다. 이 과정에서 다음과 같은 초기화가 일어납니다.
- 큐 생성: 입력 큐와 출력 큐를 만들어 요청과 결과를 관리
- 프론트엔드와 초기 통신: DEALER ZMQ 소켓을 이용해 API 서버와 handshake
- 데이터 병렬 그룹 초기화: NCCL 백엔드 기반으로 DP 그룹을 형성
- 멀티 프로세스 실행기 초기화: TP=4 환경에서 MultiProcExecutor를 실행
- 스레드 실행:
- 입력 스레드: API 서버 요청을 소켓에서 수신
- 메인 스레드: 큐에서 요청을 꺼내 모델 실행
- 출력 스레드: 결과를 API 서버로 반환
결국 각 DP 복제본마다 입력/메인/출력 스레드가 항상 대기 상태로 돌며 요청을 처리하게 됩니다.
API 서버 노드: 요청 처리와 로드 밸런싱
API 서버가 있는 노드에서는 AsyncLLM 객체가 생성됩니다. 이는 내부적으로 DPAsyncMPClient를 통해 분산 엔진과 비동기적으로 통신합니다.
- 입력 요청 처리
- 클라이언트 요청이 들어오면 FastAPI 엔드포인트(/completion, /chat/completion 등)가 이를 수신
- 프롬프트를 토크나이징하고 요청 메타데이터를 구성
- AsyncLLM.generate를 호출하여 요청을 DP 클러스터에 전달
- 로드 밸런싱
- DP 코디네이터가 각 엔진의 큐 상태(대기/실행 중 요청 수)를 수집
- 로드가 가장 적은 엔진으로 요청을 분산
- 필요 시 SCALE_ELASTIC_EP 명령을 통해 엔진 복제 수를 동적으로 조정 가능 (Ray 백엔드 기반)
- 출력 처리
- 엔진의 출력 스레드가 결과를 반환하면, asyncio task가 이를 수신
- 출력 토큰과 메타데이터를 모아 최종 JSON 응답을 생성
- FastAPI가 이를 Uvicorn을 통해 클라이언트로 반환
요청-응답 흐름 요약
예를 들어, 아래와 같은 요청을 보낸다고 해봅시다.
curl -X POST http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "The capital of France is",
"max_tokens": 50,
"temperature": 0.7
}'
- API 서버: 요청 수신 → 토크나이징 → AsyncLLM.generate 호출
- DP 코디네이터: 부하 상태 확인 후 최적의 엔진 선택
- Headless 노드 엔진: 입력 스레드 → 메인 스레드 → MultiProcExecutor 실행 → 출력 스레드
- API 서버: 결과 수신 → JSONResponse 변환 → 클라이언트 반환
사용자는 단순히 curl 요청을 보내지만, 내부적으로는 수십 개의 프로세스와 스레드, 메시지 큐, 네트워크 통신이 협력하여 응답을 반환하는 구조입니다.
이번 글에서는 vLLM의 분산 서빙 아키텍처를 살펴보았습니다.
- Headless 노드는 모델 실행만 담당하고, API 서버 노드는 요청 분산과 응답 반환을 담당
- DP 코디네이터와 ZMQ 기반 메시징으로 분산 환경에서 동기화 및 로드 밸런싱을 수행
- MultiProcExecutor와 TP/DP 병렬화를 통해 GPU 리소스를 최대로 활용
- 최종적으로는 FastAPI + Uvicorn 인터페이스를 통해 사용자는 단순 REST API로 모델을 활용 가능
이 아키텍처의 장점은 내부 복잡성을 모두 추상화하여, 개발자가 단순한 API 호출만으로 대규모 LLM을 분산 환경에서 활용할 수 있게 만든다는 점입니다. 앞으로 Ray 기반의 동적 확장 기능이나 멀티 API 서버 구성이 더해지면, 대규모 상용 서비스 환경에서도 안정적으로 vLLM을 운영할 수 있을 것입니다.
Inside vLLM: Anatomy of a High-Throughput LLM Inference System
[!NOTE] Originally posted on Aleksa Gordic’s website.
blog.vllm.ai

'인공지능' 카테고리의 다른 글
| ChatGPT 개발자 모드 공개: MCP 풀 액세스의 가능성과 리스크 (0) | 2025.09.11 |
|---|---|
| 데이터 없이 스스로 똑똑해지는 AI: 메타(Meta)의 '언어 셀프 플레이(LSP)'가 보여준 3가지 놀라운 사실 (0) | 2025.09.11 |
| vLLM 확장 아키텍처: UniProcExecutor에서 MultiProcExecutor까지 - 3편 (0) | 2025.09.10 |
| vLLM 고급 기능 완벽 정리: Chunked Prefill부터 Speculative Decoding까지 - 2편 (0) | 2025.09.10 |
| Inside vLLM: 고성능 LLM 추론 시스템의 구조 해부 - 1편 (0) | 2025.09.10 |



