
대규모 언어 모델(LLM)을 실제 서비스 환경에 배치하려면 단순히 모델을 학습하는 것 이상이 필요합니다. 특히 추론 속도와 처리량(throughput)은 사용자 경험과 직결되며, 비용 절감과도 연결됩니다. 최근 주목받고 있는 vLLM은 이러한 문제를 해결하기 위해 설계된 고성능 LLM 추론 엔진으로, 최신 아키텍처와 최적화 기법을 통해 효율적인 서빙을 가능하게 합니다.
이번 글에서는 vLLM의 내부 동작 원리를 단계별로 살펴보며, 어떤 요소들이 성능을 극대화하는지 이해할 수 있도록 정리합니다.
1. vLLM 엔진과 엔진 코어
vLLM의 핵심은 LLM 엔진입니다. 엔진은 모델 실행을 담당하며, 스케줄링·메모리 관리·KV 캐시 운영 등 추론 성능을 결정짓는 주요 요소를 포함합니다.
엔진의 주요 구성 요소
- vLLM Config: 모델, 캐시, 병렬화 방식 등 엔진 동작을 설정하는 핵심 구성
- Processor: 입력을 검증하고 토크나이징하여 요청을 엔진이 이해할 수 있는 형식으로 변환
- Engine Core Client: 엔진과 사용자 요청을 연결하는 인터페이스
- Output Processor: 엔진이 생성한 결과를 최종 출력 형식으로 변환
엔진 코어 내부 구조
- 모델 실행기(Model Executor): 실제 모델의 forward pass를 실행
- 스케줄러(Scheduler): 어떤 요청을 먼저 처리할지 결정 (선입선출 또는 우선순위 기반)
- KV 캐시 관리자: 토큰별 Key/Value 캐시를 효율적으로 관리해 속도를 높임
- 출력 관리자: 가이드된 디코딩(guided decoding) 등을 지원
이러한 구조 덕분에 vLLM은 단순한 PyTorch 추론보다 훨씬 높은 처리량을 제공합니다.
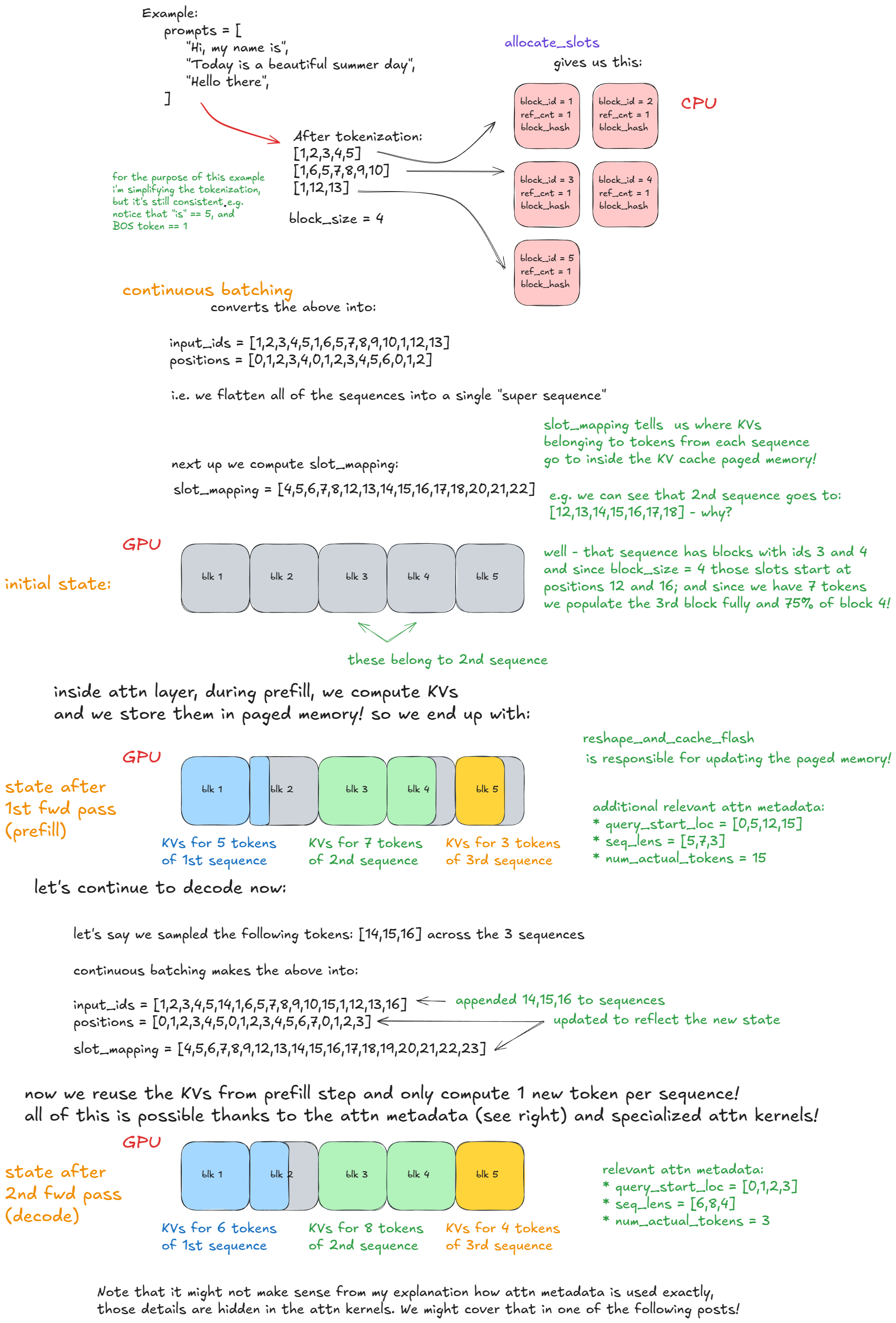
2. generate 함수: 요청 처리 흐름
vLLM의 대표적인 동작 예시는 generate 함수입니다.
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
이 코드가 하는 일은 단순합니다.
- 엔진 초기화
- 입력 프롬프트 전달
- 샘플링 파라미터에 따라 결과 생성
하지만 내부적으로는 요청을 대기열에 넣고, 스케줄링 후, KV 캐시를 활용하여 효율적으로 forward pass를 실행하는 복잡한 과정이 진행됩니다.
3. 스케줄러와 KV 캐시
엔진의 성능을 좌우하는 핵심은 스케줄러와 KV 캐시입니다.
스케줄러의 역할
- 프리필(prefill) 요청: 전체 프롬프트를 처리하는 단계, 연산량이 많음
- 디코딩(decode) 요청: 직전 토큰만 처리하는 단계, 메모리 대역폭이 중요
vLLM V1 스케줄러는 두 요청을 동시에 처리할 수 있어 V0보다 효율적입니다.
KV 캐시 관리
- 각 요청마다 KV 캐시 블록을 할당
- 요청 종료 시 블록을 반환하여 재활용
- GPU 메모리 사용량을 효율적으로 줄이고 속도를 높임
4. 고급 기능 (Advanced Features)
vLLM은 단순한 추론 엔진을 넘어, 실제 서비스에서 필요한 다양한 기능을 제공합니다.
- Continuous Batching: 새로운 요청을 실행 중에도 합류시켜 GPU 활용도를 극대화
- Prefix Caching: 여러 요청이 동일한 시작 프롬프트를 가질 경우 중복 계산을 줄임
- Speculative Decoding: 보조 모델을 활용해 더 빠르게 토큰을 예측한 뒤 검증
- Disaggregated P/D: 프리필과 디코딩을 분리해 더 유연한 리소스 활용 가능
5. 확장성: 멀티 GPU와 멀티 노드
단일 GPU 환경에서는 UniProcExecutor가 동작하지만, 실제 서비스에서는 멀티 GPU·멀티 노드 환경으로 확장해야 합니다.
- MultiProcExecutor: 여러 GPU에서 병렬 추론
- 노드 간 분산 처리: 대규모 트래픽을 처리할 수 있도록 서버 간 동적 로드 밸런싱 지원
이 과정을 통해 vLLM은 개인 환경부터 대규모 서비스까지 유연하게 확장할 수 있습니다.
6. 서빙 레이어
엔진만으로는 충분하지 않습니다. 실제 서비스에 적용하려면 동시성, 분산 처리, 웹 API가 필요합니다.
vLLM의 서빙 레이어는 다음을 제공합니다.
- 여러 요청 동시 처리
- 비동기 요청 처리
- 웹 서버와 직접 연결할 수 있는 분산 서빙 구조
이를 통해 단순한 오프라인 추론 엔진이 아닌, 실제 제품 환경에서 사용할 수 있는 서빙 플랫폼으로 발전합니다.
7. 벤치마크와 성능 최적화
vLLM은 성능 측정을 위해 **레이턴시(latency)**와 **처리량(throughput)**을 중심으로 평가합니다.
- Prefill vs Decode 성능 분석: GPU 연산/메모리 병목 파악
- 자동 튜닝: GPU 메모리 활용도와 배치 크기를 조정해 최적화
이러한 벤치마크는 단순 성능 비교를 넘어, 시스템 자원을 최대한 활용하는 기준점이 됩니다.
vLLM은 단순한 추론 엔진을 넘어, 고성능·고확장성 LLM 서빙 시스템을 위한 핵심 솔루션입니다.
- 엔진 코어와 스케줄러, KV 캐시 최적화로 오프라인 추론에서도 높은 성능 제공
- Continuous Batching, Prefix Caching, Speculative Decoding 같은 고급 기능으로 실제 서비스 환경에 최적화
- 멀티 GPU·멀티 노드 확장성과 서빙 레이어 지원으로 대규모 시스템 운영 가능
앞으로 LLM을 서비스에 적용하려는 모든 팀은 단순히 모델 정확도뿐 아니라 추론 효율성을 고려해야 합니다. vLLM은 이러한 요구를 충족시키며, 차세대 AI 서빙의 중요한 기반이 될 것입니다.
Inside vLLM: Anatomy of a High-Throughput LLM Inference System
[!NOTE] Originally posted on Aleksa Gordic’s website.
blog.vllm.ai

'인공지능' 카테고리의 다른 글
| vLLM 확장 아키텍처: UniProcExecutor에서 MultiProcExecutor까지 - 3편 (0) | 2025.09.10 |
|---|---|
| vLLM 고급 기능 완벽 정리: Chunked Prefill부터 Speculative Decoding까지 - 2편 (0) | 2025.09.10 |
| 바이트댄스 Seedream 4.0 프리뷰: 구글 나노바나나를 넘어설 수 있을까 (0) | 2025.09.10 |
| Claude, 이제 파일 생성과 편집까지 지원한다 (0) | 2025.09.10 |
| 코드보다 스펙이 먼저: Spec-Driven Development가 바꿀 개발 흐름 (0) | 2025.09.10 |



