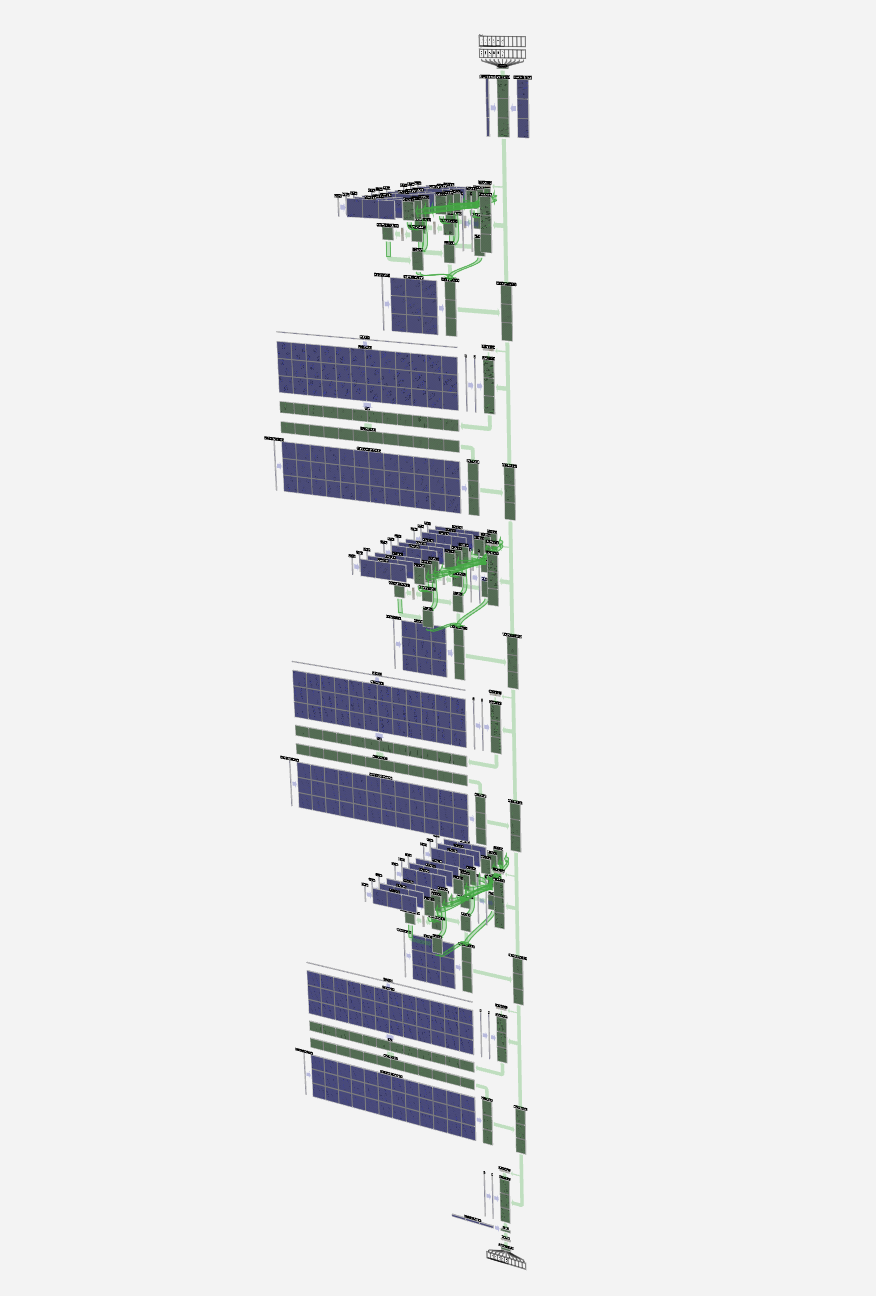
GPT 같은 대형 언어 모델(LLM)은 이미 다양한 분야에서 활용되고 있지만, 그 작동 원리를 직관적으로 이해하기란 쉽지 않습니다. 이번 글에서는 Nano-GPT라는 초소형 모델을 예시로, 토큰화부터 임베딩, 트랜스포머 레이어를 거쳐 최종 출력이 생성되는 과정을 시각적으로 풀어보겠습니다. 이 모델의 목표는 단순히 6개의 문자 시퀀스를 입력받아 알파벳 순으로 정렬하는 것인데, 그 과정을 통해 LLM의 핵심 메커니즘을 직관적으로 이해할 수 있습니다.
GPT 언어 모델이란?
GPT는 Generative Pre-trained Transformer의 약자로, 주어진 입력에서 다음에 올 단어(토큰)를 예측하는 방식으로 동작합니다.
- 입력: 토큰 시퀀스 (텍스트의 최소 단위)
- 처리: 임베딩 → 트랜스포머 레이어 반복 → 확률 분포 예측
- 출력: 다음에 등장할 토큰 확률
즉, 모델은 항상 **“다음에 어떤 단어가 올지”**를 예측하면서 문장을 이어갑니다.
Nano-GPT의 실험 목표
Nano-GPT는 약 85,000개의 파라미터를 가진 초소형 모델입니다.
실험 목표는 단순합니다:
- 입력: 6개의 문자 시퀀스 (예: “CBAABC”)
- 출력: 알파벳 순서로 정렬된 시퀀스 (예: “AABBCC”)
이 간단한 작업을 통해 LLM의 동작 원리를 직관적으로 확인할 수 있습니다.
토큰과 어휘(Vocabulary)
모델이 문자를 처리하기 위해서는 토큰(token) 개념이 필요합니다.
- 각 문자는 고유의 토큰 인덱스를 가짐
- 이 인덱스는 숫자로 표현되어 모델의 입력값이 됨
- 전체 토큰 집합을 어휘(vocabulary) 라고 부름
예를 들어,
- ‘A’ → 토큰 인덱스 1
- ‘B’ → 토큰 인덱스 2
- ‘C’ → 토큰 인덱스 3
이런 식으로 매핑됩니다.
입력 변환과 임베딩(Embedding)
토큰 인덱스는 단순한 숫자일 뿐이므로, 모델이 학습 가능한 벡터로 변환해야 합니다.
- 각 토큰 인덱스 → 48차원 임베딩 벡터로 변환
- 이 벡터는 문자의 의미적 특징을 담고 있음
- 변환된 벡터는 여러 트랜스포머 레이어를 차례로 통과하면서 점점 더 복잡한 패턴을 학습
여기서 3D 시각화에서 초록색 셀은 입력 숫자를, 파란색 셀은 모델의 가중치를 나타냅니다.
출력과 예측 과정
트랜스포머 레이어를 거친 후, 모델은 각 입력 위치에서 다음에 등장할 토큰의 확률을 예측합니다.
예를 들어, 시퀀스의 6번째 위치에서 모델은 다음과 같이 확률을 계산할 수 있습니다:
- ‘A’일 확률: 60%
- ‘B’일 확률: 30%
- ‘C’일 확률: 10%
가장 확률이 높은 ‘A’를 선택하고, 이 결과를 다시 입력에 넣어 전체 시퀀스를 완성합니다.
Nano-GPT로 배우는 LLM의 핵심
Nano-GPT는 매우 작은 모델이지만, 그 과정을 통해 대형 언어 모델의 작동 원리를 쉽게 이해할 수 있습니다.
핵심은 다음과 같습니다:
- 입력 문자를 토큰으로 변환한다.
- 토큰을 임베딩하여 벡터 공간에 표현한다.
- 트랜스포머 레이어를 통해 패턴을 학습한다.
- 다음 토큰을 확률적으로 예측하고 반복한다.
이번 사례에서는 단순히 문자를 알파벳 순으로 정렬하는 실험이었지만, 같은 원리가 실제 대규모 GPT 모델에서도 적용됩니다. 앞으로 더 복잡한 작업(번역, 요약, 코드 생성 등)도 결국 이 단순한 “다음 토큰 예측”에서 출발한다는 점이 흥미롭습니다.
Nano-GPT 같은 미니 모델은 학습자와 연구자가 LLM의 기본 구조와 동작 원리를 빠르게 이해하는 데 좋은 출발점이 될 수 있습니다.

'인공지능' 카테고리의 다른 글
| AI와 애자일(Agile)의 만남: 개발자가 본질에 집중할 수 있는 방법 (0) | 2025.09.06 |
|---|---|
| AgentScope: LLM 기반 에이전트 애플리케이션 개발을 위한 새로운 패러다임 (0) | 2025.09.06 |
| AI가 거짓말을 하는 이유: 언어 모델 환각(Hallucination)의 비밀 (0) | 2025.09.06 |
| 에이전트 메시(Agent Mesh): 자율형 AI가 만드는 차세대 분산 지능 아키텍처 (0) | 2025.09.06 |
| Claude Code 모니터링: AI 개발자 도구 사용량 추적 가이드 (0) | 2025.09.06 |



