AI 시대의 새로운 과제, 잊는다는 능력
AI 기술이 급속도로 발전하면서 머신러닝(Machine Learning)은 일상 곳곳에서 활용되고 있습니다. 추천 시스템, 자율주행차, 의료 진단까지... 하지만 점점 더 많은 데이터를 학습하면서, 머신러닝 모델이 ‘잊지 못하는 존재’가 되는 문제가 생기고 있습니다.
만약 당신의 정보가 잘못 학습되었거나, 더 이상 시스템에 남아 있지 않기를 원한다면 어떻게 해야 할까요? 여기서 등장하는 개념이 바로 ‘머신 언러닝(Machine Unlearning)’입니다.
이 글에서는 머신 언러닝의 개념부터 작동 원리, 실질적인 적용 사례, 기술적 도전 과제, 그리고 향후 전망까지 깊이 있게 다룹니다. 데이터 프라이버시와 윤리적 AI에 관심 있는 분이라면 반드시 알아야 할 중요한 주제입니다.
머신 언러닝이란? – 모델이 특정 데이터를 ‘잊게’ 만드는 기술
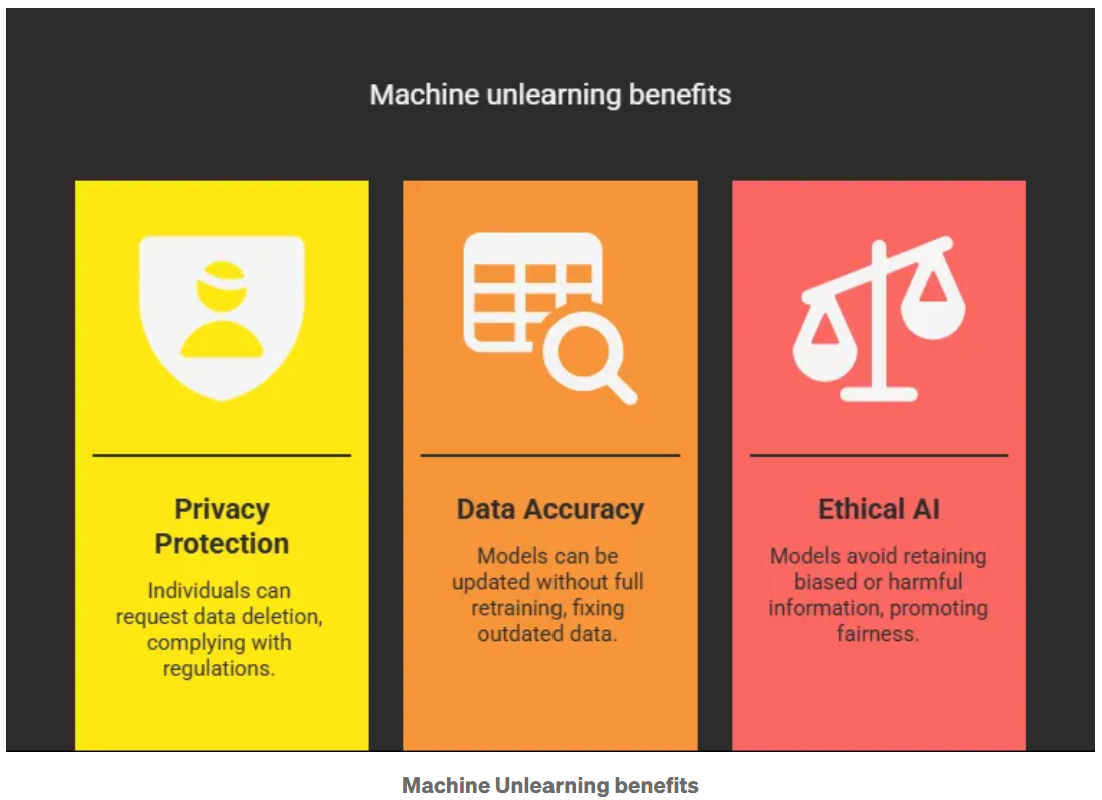
머신 언러닝은 한 번 학습된 머신러닝 모델에서 특정 데이터를 선택적으로 제거하는 기술입니다. 단순히 데이터를 지우는 것을 넘어서, 모델이 마치 해당 데이터를 학습하지 않았던 것처럼 만드는 것을 목표로 합니다.
이 기술은 다음과 같은 배경에서 등장하게 되었습니다:
- 프라이버시 보호: GDPR, CCPA 등 개인 정보 보호법에 따라 사용자는 자신의 데이터를 삭제해달라고 요청할 권리를 가지고 있습니다.
- 데이터 정확성 유지: 오래되거나 오류가 있는 데이터를 모델이 계속 기억하면 잘못된 예측을 하게 될 수 있습니다.
- 윤리적 AI 실현: 편향되거나 유해한 데이터를 제거해 더 공정한 모델을 만들 수 있습니다.
왜 머신 언러닝이 필요한가?
오늘날 머신러닝 모델은 민감하고 고위험군의 정보를 다루는 사례가 많아졌습니다. 예를 들어, 병원에서 환자의 정보를 바탕으로 재입원 가능성을 예측하는 모델을 운영할 경우, 환자가 데이터를 삭제하길 요청하면 이를 반영해야 합니다.
머신 언러닝이 필요한 주요 이유는 다음과 같습니다:
- 법적 요구사항 준수: GDPR 제17조의 “잊혀질 권리”는 시스템뿐만 아니라 AI 모델에서도 데이터를 제거할 수 있어야 한다는 것을 의미합니다.
- 모델 업데이트 비용 절감: 기존에는 데이터를 지우기 위해 모델 전체를 재학습시켜야 했지만, 머신 언러닝을 통해 더 효율적인 업데이트가 가능합니다.
- 비윤리적 학습 방지: 악의적이거나 편향된 데이터를 모델이 지속적으로 기억하지 않도록 막을 수 있습니다.
머신 언러닝은 어떻게 작동하는가?
머신 언러닝의 핵심은 ‘데이터가 모델에 미친 영향’을 제거하는 것입니다. 이를 위한 주요 방법들은 아래와 같습니다:
1. 모델 재학습(Retraining)
- 가장 직관적인 방법은 해당 데이터를 빼고 처음부터 모델을 다시 학습시키는 것입니다.
- 단점: 매우 많은 시간과 비용이 필요하며, 대규모 모델에서는 비현실적입니다.
2. 영향 함수(Influence Functions)
- 특정 데이터가 모델에 끼친 영향을 수학적으로 계산해 제거하는 방식입니다.
- 기존 모델을 완전히 버리지 않고도 수정 가능하다는 장점이 있습니다.
3. 파인 튜닝(Fine-Tuning)
- 삭제 요청된 데이터를 제거한 새 데이터로 모델을 추가 학습해 영향을 완화하는 방식입니다.
- 상대적으로 빠르지만 정확도 저하 가능성이 존재합니다.
4. 모델 파라미터 직접 편집(Model Editing)
- 특정 데이터의 영향을 반영한 파라미터를 수동으로 수정하는 방식입니다.
- 현재 활발히 연구 중인 기술로, 실용화까지는 시간이 더 필요합니다.
머신 언러닝의 도전 과제
기술적으로나 윤리적으로 중요한 머신 언러닝이지만, 해결해야 할 문제들도 많습니다:
- 완전한 삭제 검증의 어려움: 모델이 데이터를 정말 잊었는지 확신하기 어렵습니다.
- 정확도 저하 위험: 특정 데이터를 삭제하면 전체 모델 성능이 떨어질 수 있습니다.
- 확장성 문제: 특히 대형 언어 모델(LLM)에서는 처리 비용이 급격히 증가합니다.
- ‘잊었다’는 것의 정의가 모호: 데이터가 완전히 지워졌다는 판단 기준이 명확하지 않습니다.
실제 적용 사례로 보는 머신 언러닝
머신 언러닝은 다양한 산업에서 실제로 적용되거나 연구되고 있습니다:
- 의료: 환자의 정보 삭제 요청 시, 모델을 다시 학습하지 않고도 해당 환자의 데이터를 반영하지 않도록 할 수 있습니다.
- 금융: 오래되거나 사기 패턴이 아닌 데이터를 모델에서 제거해 정확도 유지
- 소셜 미디어: 사용자가 계정을 삭제하면, 추천 시스템에서도 해당 사용자의 취향 정보를 제거
- 자율주행: 민감한 정보를 학습한 경우, 법적 요건에 맞춰 해당 데이터를 삭제
머신 언러닝의 미래: 어디로 가는가?
머신 언러닝은 아직 발전 중인 분야이며, 아래와 같은 방향으로 진화하고 있습니다:
- 차등 프라이버시(Differential Privacy)와의 결합: 학습 단계에서부터 잊기 쉬운 구조 설계
- 표준화된 벤치마크 개발: 다양한 방법 간 성능 비교를 위한 공통 기준 마련
- 실시간 처리 알고리즘 개발: 스트리밍 데이터에서 실시간으로 데이터 삭제 대응 가능성
- 법·윤리 기준 정립: 언제, 어떤 방식으로 데이터를 삭제해야 하는지에 대한 명확한 가이드 마련
AI의 미래는 ‘기억’보다 ‘망각’에 달려있다
머신 언러닝은 단순한 기술이 아니라, 데이터 중심 사회에서 신뢰할 수 있는 AI를 만들기 위한 필수 요소입니다. AI가 더 넓은 분야에 적용될수록, 개인의 권리와 윤리를 고려한 ‘잊을 수 있는 능력’이 중요해질 것입니다.
앞으로 머신 언러닝은 개인정보 보호뿐 아니라, 윤리적 AI 구현을 위한 핵심 기술로 자리매김할 것입니다. 지금은 초기 단계지만, 더 나은 알고리즘, 더 정교한 평가 방법이 등장하면 본격적인 상용화도 머지않았습니다.
Machine Unlearning: Protecting Privacy in ML Models
In the fast-changing era of artificial intelligence, machine learning (ML) models are growing more and more advanced, driving everything…
medium.com

'인공지능' 카테고리의 다른 글
| "SQL 분석 자동화, 이제는 개발하듯 한다" – Rust 기반 에이전트 분석 프레임워크 소개 (0) | 2025.05.19 |
|---|---|
| Qwen3의 MoE 모델, 효율과 성능을 동시에 잡는 업스케일링 전략 (0) | 2025.05.18 |
| AI 기억의 판도를 바꾸다: OpenMemory MCP 서버로 로컬에서 모든 것을 기억하라 (0) | 2025.05.18 |
| AI Agent와 Agentic AI, 무엇이 다를까? — 개념, 아키텍처, 활용 사례, 그리고 과제까지 완벽 정리 (0) | 2025.05.18 |
| 구글 Flow, 영상 콘텐츠 제작의 판을 바꿀 새로운 AI 툴 (0) | 2025.05.18 |



