대형 언어 모델(LLM)은 자연어 이해, 논리적 추론, 창작 등의 영역에서 놀라운 성과를 보이고 있습니다. 그러나 여전히 해결해야 할 중요한 문제가 있습니다. 바로 외부 지식을 효율적으로 통합하는 방법입니다.
기존의 방법들, 예를 들어 **파인 튜닝(fine-tuning)**과 **검색 증강 생성(RAG, Retrieval-Augmented Generation)**은 각각의 한계를 가지고 있습니다. 파인 튜닝은 모델을 다시 학습해야 하므로 비용이 많이 들고, RAG는 별도의 검색 모듈이 필요해 시스템이 복잡해집니다.
이러한 문제를 해결하기 위해 **KBLaM(Knowledge Base-Augmented Language Model)**이 등장했습니다. KBLaM은 기존 방법들과는 다른 **"지식 베이스 기반 LLM"**이라는 새로운 패러다임을 제시하며, 지식을 효율적으로 저장하고 검색할 수 있는 독창적인 접근 방식을 제공합니다.
이 블로그에서는 KBLaM이 어떤 방식으로 외부 지식을 통합하는지, 기존 방법들과 어떤 차별점을 가지는지, 그리고 이 기술이 AI 분야에서 어떤 가능성을 열어주는지 살펴보겠습니다.
1. 기존 방법들의 한계
외부 지식을 LLM에 통합하기 위한 기존 접근법에는 대표적으로 다음과 같은 방법이 있습니다.
✅ 1) 파인 튜닝(Fine-tuning)
- 사전에 훈련된 모델을 특정 도메인의 데이터로 추가 학습하는 방법
- 단점: 학습 비용이 많이 들고, 새로운 정보를 추가하려면 다시 학습해야 함
✅ 2) 검색 증강 생성(RAG, Retrieval-Augmented Generation)
- 모델이 외부 문서를 검색한 후, 해당 내용을 컨텍스트로 추가하여 답변 생성
- 단점: 검색 모듈과 LLM이 분리되어 있어 시스템이 복잡하고, 최적의 검색 결과를 찾는 과정에서 오류 가능성 존재
✅ 3) 인-컨텍스트 학습(In-context Learning)
- 필요한 정보를 직접 프롬프트에 포함하는 방식
- 단점: 지식이 많아질수록 연산 비용이 기하급수적으로 증가(메모리 사용량이 너무 많아짐)

2. KBLaM: 새로운 지식 통합 방식
KBLaM은 기존 방식의 단점을 극복하기 위해 **새로운 개념의 "지식 베이스 기반 언어 모델"**을 도입했습니다.
🔹 KBLaM의 핵심 개념
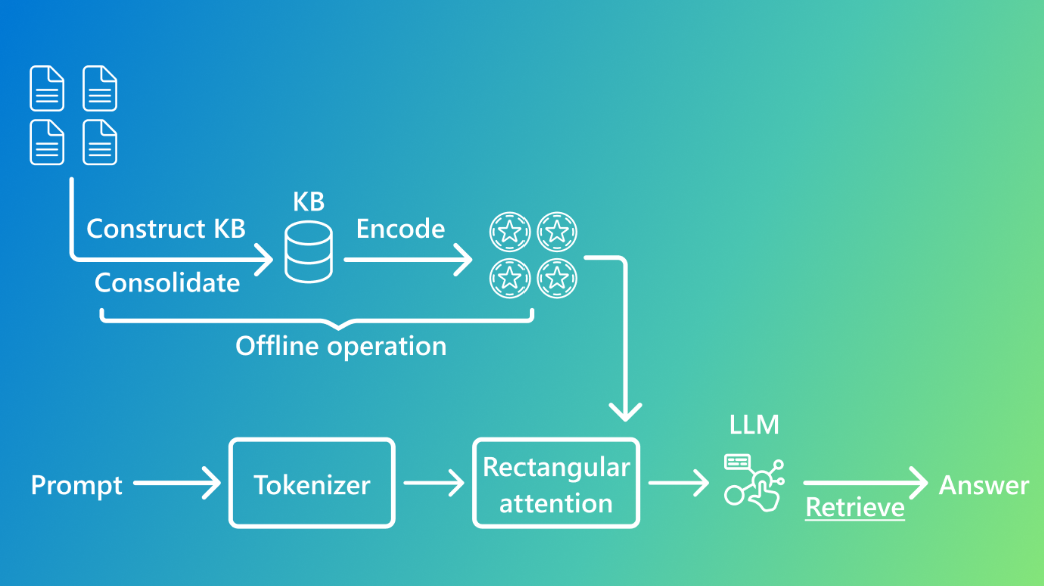
- **지식 베이스(Structured Knowledge Base)**를 활용하여 정보를 정리
- 정리된 정보를 키-값 벡터(key-value vector) 쌍으로 변환하여 LLM에 직접 통합
- **"직사각형 어텐션(Rectangular Attention)"**을 적용해 효율적인 검색 수행
즉, KBLaM은 검색 과정 없이 외부 지식을 모델 내부에 효율적으로 통합하여, 빠르고 정확한 답변을 생성할 수 있도록 설계되었습니다.
3. KBLaM의 주요 기술 요소
✅ 1) 지식 인코딩(Knowledge Encoding)
- 외부 지식을 키(key)-값(value) 벡터 쌍으로 변환
- 키(Key): 엔터티(예: "마이크로소프트")와 속성(예: "설립 연도")
- 값(Value): 해당 속성의 실제 값(예: "1975년")
- 이러한 벡터 쌍을 모델 내부에 저장하여 빠른 검색 및 추론 가능
✅ 2) 직사각형 어텐션(Rectangular Attention) 적용
- 기존 Transformer 모델의 쿼드러틱(quadratic) 어텐션 비용 문제를 해결
- 기존에는 모든 토큰이 서로 상호작용했지만, KBLaM은 사용자의 질문이 지식 베이스의 정보에만 주목하도록 설계
- 덕분에 메모리 사용량이 선형(linear) 증가하여 대량의 지식을 효율적으로 처리 가능
✅ 3) 효율적인 지식 검색(Efficient Knowledge Retrieval)
- KBLaM은 검색 모듈 없이도 LLM 내부에서 필요한 지식을 자동으로 검색
- 동적으로 지식을 가져오기 때문에 지식을 업데이트할 때 재학습이 필요 없음
4. KBLaM vs. 기존 접근법 비교
방법 지식 업데이트 용이성 검색 속도 학습 비용 메모리 효율성
| 파인 튜닝(Fine-tuning) | ❌ 재학습 필요 | ✅ 빠름 | ❌ 매우 높음 | ✅ 상대적으로 효율적 |
| 검색 증강 생성(RAG) | ✅ 즉시 업데이트 가능 | ❌ 검색 단계 필요 | ✅ 낮음 | ❌ 검색 과정에서 추가 메모리 필요 |
| 인-컨텍스트 학습 | ✅ 즉시 업데이트 가능 | ✅ 빠름 | ❌ 비용 증가(지식량이 많아질수록 비효율적) | ❌ 메모리 사용량 급증 |
| KBLaM | ✅ 즉시 업데이트 가능 | ✅ 검색 단계 없음 (LLM 내부에서 바로 검색) | ✅ 낮음 (추가 학습 불필요) | ✅ 선형 메모리 사용량 |
KBLaM은 기존 방법들과 비교했을 때 지식 업데이트가 쉽고, 검색 과정이 없으며, 메모리 효율이 뛰어나다는 점에서 차별화됩니다.
5. KBLaM의 기대 효과 및 활용 분야
🚀 1) LLM의 신뢰성과 정확성 향상
- KBLaM은 LLM이 **잘못된 정보를 생성하는 문제(할루시네이션, Hallucination)**를 줄이는 데 도움을 줌
- 필요한 정보가 지식 베이스에 없을 경우, "모르겠다"는 답변을 하도록 학습 가능
🏥 2) 의료, 금융, 법률 등 전문 분야 적용 가능
- 전문적인 정보가 필요한 분야에서도 신뢰성 높은 답변 제공 가능
- 예: 최신 법률 정보를 자동으로 업데이트하여 변호사 지원 AI 개발
📚 3) 기업 내부 데이터 활용 AI 시스템 구축
- 기업 내부 문서, 매뉴얼 등을 기반으로 AI 챗봇을 구축하여 고객 지원 자동화
6. KBLaM이 가져올 AI의 미래
KBLaM은 외부 지식을 LLM에 통합하는 새로운 접근법으로, 기존의 파인 튜닝, RAG, 인-컨텍스트 학습 방식이 가지는 한계를 극복했습니다.
이 기술을 통해 LLM은 더 많은 정보를 효율적으로 저장하고 활용할 수 있으며, 신뢰성 높은 답변을 제공할 수 있는 AI 시스템으로 발전할 것입니다.
향후 KBLaM이 더 발전하면, 더욱 정확하고 실시간으로 업데이트되는 AI 비서, 전문가용 AI, 기업 맞춤형 AI 솔루션이 등장할 가능성이 높습니다.
A more efficient path to add knowledge to LLMs
Introducing KBLaM, an approach that encodes and stores structured knowledge within an LLM itself. By integrating knowledge without retraining, it offers a scalable alternative to traditional methods.
www.microsoft.com

'인공지능' 카테고리의 다른 글
| AI가 코드 리뷰를 대신해준다고? CodeRabbit이 코드 품질을 혁신하는 방법! (0) | 2025.03.28 |
|---|---|
| Playwright 기반 MCP 서버: 웹 자동화의 새로운 가능성 (0) | 2025.03.28 |
| 새로운 AGI 테스트 ARC-AGI-2, 대부분의 AI 모델을 좌절시키다 (0) | 2025.03.27 |
| Zapier MCP: AI와 8,000개 앱을 연결하는 새로운 자동화 솔루션 (0) | 2025.03.27 |
| OpenAI Agents SDK, MCP 공식 지원! AI 모델과 도구 연결이 더 쉬워진다 (0) | 2025.03.27 |



