사내 문서와 FAQ를 AI 챗봇에 넣었는데, 자꾸 엉뚱한 답변이 돌아오나요?
최신 자료를 반영했는데도 여전히 오래된 정보를 기반으로 틀린 답을 내놓나요?
이런 문제는 대부분 ‘데이터 분할 방식’, 즉 ‘청킹(chunking)’ 설정에서 시작됩니다.
AI가 문서를 잘 활용하게 만들려면, 지식베이스와 청킹 과정을 제대로 이해하는 게 핵심입니다.
이 글에서는 Dify의 지식베이스 시스템과 청킹 설정법을 알기 쉽게 설명합니다.
읽고 나면, 당신의 AI 챗봇이 더 정확하게 문서를 이해하고, 믿을 만한 답변을 하도록 설정할 수 있을 겁니다.
RAG와 지식베이스: AI가 문서를 활용하는 방식
요즘 AI 챗봇은 GPT 같은 대규모 언어 모델(LLM)을 활용합니다.
그런데 이런 모델은 사전에 학습한 데이터에 기반해 답변합니다.
그래서 회사 내부의 최신 자료나 특정 매뉴얼 같은 걸 알지 못하는 경우가 많습니다.
이 문제를 해결하려고 등장한 게 바로 RAG(Retrieval-Augmented Generation) 방식입니다.
쉽게 말해, AI가 질문을 받으면 먼저 사내 문서나 FAQ 등 지식베이스에서 관련 내용을 찾아보고,
그걸 바탕으로 더 정확한 답변을 만들어내는 방식입니다.
Dify는 이 RAG 시스템을 쉽게 구축할 수 있도록 돕는 플랫폼입니다.
Dify의 ‘지식베이스’ 기능은 문서를 올리고, 그 내용을 청킹해 AI가 빠르게 찾아쓰게 만드는 역할을 합니다.
청킹(chunking)이 중요한 이유
문서를 한 번에 통째로 AI에게 보여주면 좋지 않을까 생각할 수 있습니다.
하지만 그렇게 하면 오히려 AI가 필요한 정보를 찾기 어려워집니다.
예를 들어, 100페이지짜리 매뉴얼에서 2~3줄짜리 답을 찾는다고 해보죠.
AI가 매번 100페이지 전체를 읽고 분석해야 한다면 비효율적이고, 실수할 가능성도 큽니다.
그래서 문서를 잘게 나누는 ‘청킹(chunking)’이 필요합니다.
문서를 적당한 크기로 쪼개두면, AI가 질문을 받았을 때 그중 필요한 부분만 빨리 찾아서 답변에 활용할 수 있습니다.
청킹이 잘 되어 있으면 다음과 같은 장점이 있습니다:
- 검색 속도 증가
- AI가 헷갈리지 않고 정확한 정보를 찾을 확률 상승
- 최신 업데이트된 자료도 빠르게 반영 가능

Dify의 청킹 모드: 일반 모드 vs. 부모-자식 모드 비교
Dify에서는 문서를 청킹할 때 두 가지 모드를 제공합니다:
(1) 일반 모드
문서를 일정한 규칙에 따라 독립적인 덩어리(chunk)로 나누는 방식입니다.
문단 단위로 나누거나, 특정 구분자를 설정해서 끊을 수도 있습니다.
장점: 설정이 간단하고, 작은 규모의 문서에 적합
단점: 중요한 내용이 앞뒤 문맥과 분리돼 의미 전달이 부족할 수 있음
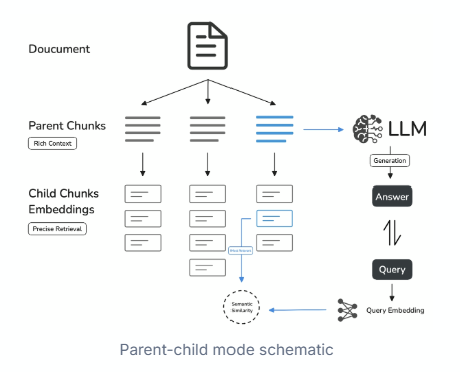
(2) 부모-자식 모드
문서를 ‘부모 청크(큰 문단)’와 ‘자식 청크(작은 문장)’로 이중 분할하는 방식입니다.
AI가 질문을 받으면 먼저 자식 청크(작은 조각)에서 관련 문장을 찾고,
그걸 포함한 부모 청크(문단 전체)를 함께 제공해 문맥까지 전달합니다.
장점:
- 정확도와 맥락 유지가 뛰어남
- 긴 문서나 매뉴얼처럼 흐름이 중요한 자료에 적합
단점: 설정이 다소 복잡할 수 있음

청킹 설정 따라하기: 정확도 높이는 법
Dify에서 지식베이스와 청킹을 설정하는 기본 흐름을 설명드릴게요.
① 지식베이스 생성
- Dify 접속 → 상단 ‘Knowledge’ 클릭 → ‘Create Knowledge’ 선택
- 회사 내부 문서, FAQ, 매뉴얼 파일(PDF, TXT 등) 업로드
② 청킹 모드 선택
- 처음이라면 ‘부모-자식 모드’ 추천
- ‘Parent Chunk’는 문단(\n 기준)으로 설정, 최대 길이는 500~1000자 정도
- ‘Child Chunk’는 문장(.) 기준으로 설정, 최대 길이는 200~300자 추천
③ 데이터 전처리
- 줄바꿈·공백 제거
- URL, 이메일 주소 제거
- ‘Preview Chunk’ 클릭해 분할 결과 확인
④ 최신 문서 업데이트 방법
- 기존 지식베이스에 새 문서 추가
- 변경 사항 있으면 해당 파일만 재업로드하면 자동 반영
효율적인 지식베이스 설정으로 AI 정확도 높이기
Dify의 지식베이스와 청킹 설정은 AI 챗봇 정확도를 좌우하는 핵심 요소입니다.
문서를 그냥 넣는 것보다 적절한 크기로 나누고, 문맥을 유지하도록 설정하는 게 중요합니다.
핵심 요약:
- 최신 정보 반영은 기본, AI가 찾기 쉽게 문서를 ‘청킹’해서 넣어야 한다.
- 간단한 문서는 일반 모드, 복잡한 매뉴얼은 부모-자식 모드가 적합하다.
- 데이터 청킹 설정은 문단 단위(500
1000자), 문장 단위(200300자)가 안정적이다.
이렇게 설정하면, 당신의 AI 챗봇은 최신 문서를 바탕으로 정확하고 신뢰할 수 있는 답변을 내놓을 수 있습니다.
앞으로 AI 기반 고객지원 시스템이나 사내 검색 시스템을 구축할 때, 꼭 한 번 활용해보세요.
당신의 업무 효율이 확실히 달라질 겁니다.

'인공지능' 카테고리의 다른 글
| Grok 3 심층 분석 – GPT-4o를 넘어서? xAI의 차세대 AI 모델, 무엇이 다른가 (0) | 2025.02.19 |
|---|---|
| [Dify RAG #2] LLM 검색 정확도를 좌우하는 인덱싱 설정 – High-Quality와 Economical, 무엇이 다를까? (0) | 2025.02.18 |
| 🔥 Grok-3, AI의 새 지평 열다" – OpenAI·Google 모델을 뛰어넘은 이유와 활용법 (0) | 2025.02.18 |
| GUI 자동화의 판도를 바꾸다 – OmniParser V2, LLM과 함께하는 차세대 화면 인식 솔루션 (0) | 2025.02.17 |
| GPT-4.5와 GPT-5 출시, 무엇이 달라질까? 오픈AI의 새 AI 모델 완전 분석 (0) | 2025.02.17 |