기존의 오프라인 번역 기술과 달리, Hibiki는 사용자의 음성을 실시간으로 번역된 음성으로 변환하는 모델입니다. 단순한 텍스트 번역이 아닌, 원본 음성의 스타일을 유지하면서 자연스럽게 변환하는 것이 특징입니다.
특히, Decoder-only 모델 아키텍처를 기반으로 하며, Moshi의 멀티스트림(multistream) 기술을 활용하여 원본 및 번역 음성을 동시에 처리할 수 있습니다. 현재 프랑스어 → 영어(FR → EN) 번역만 지원하지만, 경량 모델인 Hibiki-M은 스마트폰에서도 실행 가능하여 활용성이 높습니다.
2. Hibiki의 주요 기술 및 아키텍처
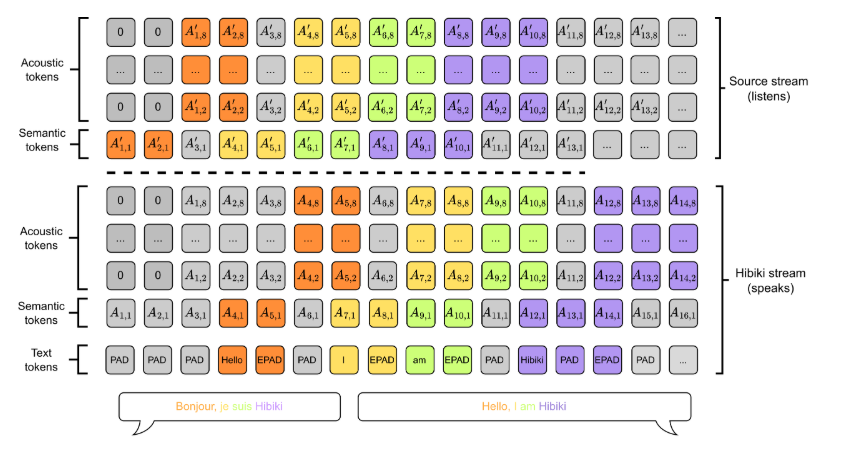
① Decoder-only 모델 기반 실시간 음성 번역
Hibiki는 Decoder-only 구조로 설계되어 실시간 음성 번역을 가능하게 합니다. 일반적인 번역 모델과 달리, 입력된 음성을 실시간으로 분석하고, 즉시 번역된 음성을 생성하는 것이 특징입니다.
- 초당 12.5Hz의 일정한 프레임 속도 유지
- 타임스탬프 포함된 텍스트 번역 제공
- 원본 및 번역 음성을 동시에 모델링 가능
즉, 사용자가 말을 하면 동시에 번역된 음성이 자연스럽게 출력되는 형태입니다.
② Moshi 멀티스트림(multistream) 아키텍처 적용
멀티스트림(multistream) 아키텍처를 통해 Hibiki는 원본 음성과 번역된 음성을 동시에 처리할 수 있습니다. 이를 통해 더욱 자연스러운 대화형 번역이 가능해집니다.
③ 원본 스타일 유지 기능
Hibiki는 번역된 음성을 생성할 때, 원본 음성의 스타일(억양, 속도 등)을 유지하려는 특징이 있습니다. 이를 통해 기계적인 음성 대신, 보다 인간적인 자연스러운 번역 음성이 제공됩니다.
3. 학습 방법 - 합성 데이터(Synthetic Data) 활용

실제 원본 및 번역 음성이 정렬된 데이터는 많지 않기 때문에, Hibiki는 **합성 데이터(synthetic data)**를 생성하여 학습을 진행합니다.
- MADLAD 기계 번역 시스템을 활용하여 원본 및 번역 텍스트를 약한 지도학습 방식으로 정렬
- 번역이 원본에서 예측 가능해지는 시점에만 단어가 나타나도록 정렬 규칙 적용
💡 학습을 위한 정렬 방법
- 침묵 삽입(Silence Insertion): 번역된 음성이 원본 음성 흐름과 자연스럽게 연결되도록 침묵 구간 추가
- 정렬을 반영한 음성 합성(Alignment-aware TTS): 원본 및 번역된 음성 간 타이밍을 맞추기 위해 정렬을 반영하여 합성
이를 통해 실제 대화와 비슷한 흐름을 유지하면서도 정확한 번역이 가능하도록 학습됩니다.
4. 실시간 추론(Inference) 방식
Hibiki는 온디바이스(on-device) 실행이 가능한 경량 모델을 제공하면서도, 고품질의 음성 번역을 제공합니다.
✅ 온디바이스 실행 가능
- Hibiki-M(경량 모델)은 스마트폰에서도 실행 가능
- PyTorch, Rust, MLX(macOS), MLX-Swift(iOS)에서 실행 가능
✅ Classifier-Free Guidance 활용
- 음성 유사도를 조절하는 Classifier-Free Guidance 계수 조정 가능
- 계수가 높을수록 원본과 비슷한 음성 생성, 하지만 번역 품질이 저하될 수 있음
✅ 온도 샘플링(Temperature Sampling) 방식
- Hibiki는 복잡한 추론 방식을 배제하고, 온도 샘플링을 적용하여 배치 처리와 호환됨
5. Hibiki 모델 종류
현재 Hibiki는 프랑스어 → 영어(FR → EN) 번역을 지원하는 두 가지 모델을 제공합니다.
모델 특징
| Hibiki 2B | 더 깊은 Transformer 구조, 스트림당 16 RVQ |
| Hibiki 1B (Hibiki-M) | 경량 버전, 스트림당 8 RVQ, 스마트폰에서도 실행 가능 |
💡 Hibiki-M은 온디바이스 실행이 가능하여, 모바일 환경에서도 실시간 번역을 사용할 수 있습니다.
6. Hibiki 실행 방법
Hibiki는 다음과 같은 환경에서 실행할 수 있습니다.
- PyTorch
- Rust
- MLX(macOS)
- MLX-Swift(iOS)
또한, Hibiki의 코드는 kyutai-labs/moshi 저장소에서 확인할 수 있으며, 실제 구현은 Moshi 프로젝트와 거의 동일합니다.
Hibiki는 기존의 오프라인 번역과 달리, 실시간으로 음성을 번역하고 자연스럽게 전달하는 기술을 제공합니다.
🔹 실시간 음성 번역 가능 – 지연 없이 바로 대화 가능
🔹 멀티스트림 기술로 원본 및 번역 음성을 동시에 모델링
🔹 온디바이스(on-device) 실행 가능 – 스마트폰에서도 사용 가능
🔹 원본 음성 스타일 유지 – 자연스러운 음성 번역 제공
현재는 프랑스어 → 영어(FR → EN) 번역만 지원하지만, 향후 다양한 언어로 확장될 경우 글로벌 커뮤니케이션의 새로운 패러다임을 제시할 가능성이 높습니다.
💡 Hibiki가 상용화되면 어떤 변화가 기대될까요?
- 국제 회의, 여행, 다국적 협업에서 실시간 번역이 더욱 원활해질 것
- 실시간 통역 기술이 더욱 발전하여 인공지능 기반 커뮤니케이션이 활성화될 것
- 경량 모델을 활용하여 스마트폰, 웨어러블 기기에서도 쉽게 사용할 수 있을 것
https://github.com/kyutai-labs/hibiki
GitHub - kyutai-labs/hibiki: Hibiki is a model for streaming speech translation (also known as simultaneous translation). Unlike
Hibiki is a model for streaming speech translation (also known as simultaneous translation). Unlike offline translation—where one waits for the end of the source utterance to start translating--- H...
github.com

'인공지능' 카테고리의 다른 글
| AI가 바꾸는 UX/UI 디자인: 혁신적인 인터페이스 패턴 8가지 (0) | 2025.02.12 |
|---|---|
| AI 경제성 논란, 샘 올트먼의 세 가지 관찰 (0) | 2025.02.12 |
| n8n과 LangChain을 활용한 AI 자동화: 쉽게 시작하는 방법 (0) | 2025.02.11 |
| 🦢 Goose: 개발자를 위한 강력한 오픈소스 AI 에이전트 (0) | 2025.02.11 |
| AI 정책, 공상과학이 아닌 현실을 반영해야 한다 (0) | 2025.02.11 |



