1. DeepSeek-VL2란?
비전-언어 모델(VLMs)이란?
비전-언어 모델(Vision-Language Models, VLMs)은 텍스트와 이미지를 동시에 이해할 수 있는 AI 모델입니다. 기존의 대형 언어 모델(LLM)이 텍스트 데이터를 중심으로 학습하는 반면, VLMs는 이미지와 텍스트를 결합하여 보다 풍부한 정보를 분석할 수 있습니다.
이러한 모델들은 시각적 질문 응답(VQA), 광학 문자 인식(OCR), 차트 및 문서 이해, 비주얼 스토리텔링 등의 다양한 분야에서 활용될 수 있습니다. 최근에는 이러한 VLMs가 발전하면서 고해상도 이미지 처리 및 보다 정교한 텍스트 이해가 가능해지고 있습니다.
DeepSeek-VL2 개요
DeepSeek-VL2는 Mixture-of-Experts(MoE) 기반의 최신 비전-언어 모델로, 기존 모델인 DeepSeek-VL보다 크게 향상된 성능을 자랑합니다.
DeepSeek-VL2는 다음과 같은 특징을 갖습니다.
✅ 향상된 이미지 처리 기술: 다양한 해상도의 이미지를 효율적으로 처리하는 Dynamic Tiling Vision Encoding 기법 적용
✅ 강력한 언어 이해력: Multi-head Latent Attention(MLA) 기술을 사용하여 텍스트 처리 속도 및 정확도 개선
✅ 3가지 모델 크기 지원:
- DeepSeek-VL2-Tiny (1.0B 활성화 파라미터)
- DeepSeek-VL2-Small (2.8B 활성화 파라미터)
- DeepSeek-VL2 (4.5B 활성화 파라미터)
이 모델은 오픈소스로 공개되어 있으며, 누구나 GitHub에서 다운로드하여 사용할 수 있습니다.
2. DeepSeek-VL2의 주요 기술 및 특징
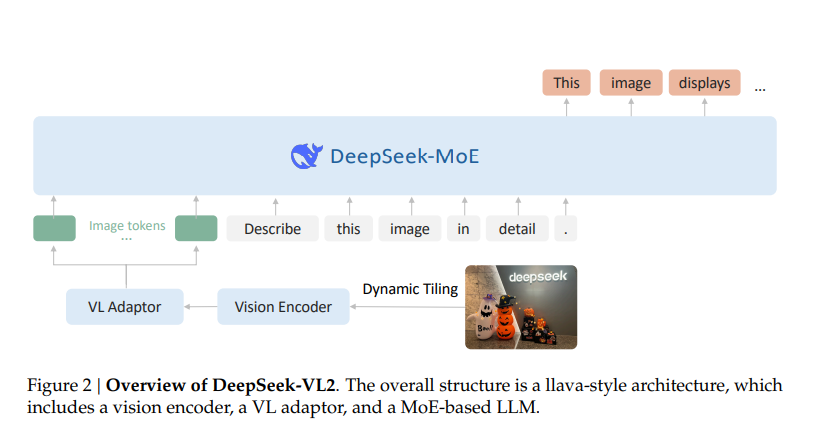
1) Mixture-of-Experts(MoE) 아키텍처
MoE는 AI 모델이 여러 개의 전문가(Expert) 네트워크를 갖고, 입력 데이터에 따라 적절한 전문가를 선택하여 학습하는 방식입니다.
DeepSeek-VL2는 이 MoE 기술을 활용하여 적은 활성화 파라미터로도 높은 성능을 유지할 수 있도록 최적화되었습니다.
🔹 기존 밀집(Dense) 모델보다 적은 연산량으로 높은 성능 유지
🔹 특정 작업에 맞춰 학습된 전문가 네트워크를 선택하여 처리 속도 향상
🔹 대형 모델이면서도 연산 자원이 효율적으로 사용됨

2) Dynamic Tiling Vision Encoding 기술
기존 DeepSeek-VL 모델은 고정 해상도(384×384 또는 1024×1024)에서만 이미지 처리가 가능했으나, DeepSeek-VL2는 새로운 Dynamic Tiling Vision Encoding 기술을 도입하여 다양한 해상도의 이미지를 효율적으로 처리할 수 있습니다.
✅ 고해상도 이미지 지원: 이미지 크기에 따라 자동으로 조각(Tile)으로 나누어 처리
✅ 더 정확한 분석 가능: 문서, 차트, 복잡한 이미지에서도 정교한 정보 추출 가능
✅ 메모리 사용 최적화: 필요한 부분만 처리하여 연산 부담 감소
3) Multi-head Latent Attention(MLA) 기술
MLA는 기존의 Transformer 기반 모델에서 Key-Value Cache를 압축하여 저장하는 새로운 방법입니다.
이를 통해 DeepSeek-VL2는 추론 속도를 향상시키고, 더 긴 문맥을 효율적으로 처리할 수 있습니다.
🔹 연산량 감소: 필요한 정보만 추출하여 빠르게 처리
🔹 텍스트와 이미지 결합 능력 강화
🔹 대화형 AI 및 실시간 응답 성능 개선
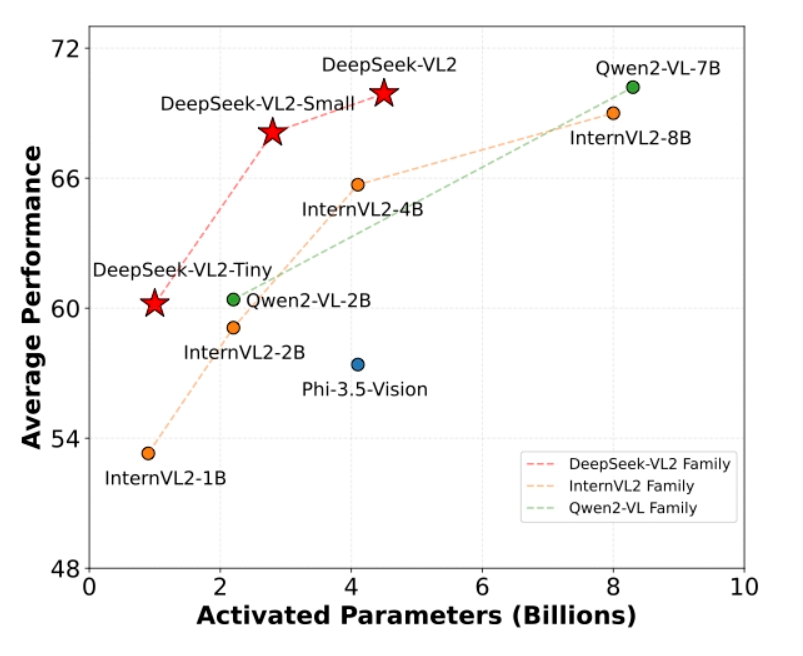
3. DeepSeek-VL2의 성능 및 평가
DeepSeek-VL2는 다양한 벤치마크 테스트에서 최신 오픈소스 모델 대비 최고 수준의 성능을 기록했습니다.
실제 테스트 결과는 다음과 같습니다.
📌 VQA (시각적 질문 응답) 테스트: DeepSeek-VL2는 기존 모델보다 더욱 정확한 이미지 설명 및 응답 제공
📌 OCR (광학 문자 인식) 성능: 문서 내 텍스트를 보다 정확하게 인식
📌 차트 및 테이블 분석: 데이터 분석 및 시각 자료 해석 능력 향상
📌 멀티 이미지 이해: 여러 개의 이미지를 조합하여 관계 분석 가능
벤치마크 결과, DeepSeek-VL2는 기존의 Dense 모델보다 적은 연산량으로도 동급 이상의 성능을 보였으며, 구글 및 오픈AI의 최신 모델들과 비교해도 경쟁력 있는 결과를 보여주었습니다.
4. DeepSeek-VL2의 활용 사례
✅ 1) 시각적 질문 응답 (VQA)
- 예: "이 이미지 속 사람은 무엇을 하고 있나요?"
- DeepSeek-VL2는 이미지 내에서 객체를 인식하고 해당 내용을 설명하는 기능을 제공
✅ 2) OCR 및 문서/차트 이해
- 예: 영수증, 계약서, 표, 그래프 등의 내용을 자동 분석
- 고해상도 문서에서도 높은 인식률을 제공하여 기업 및 연구 분야에서 활용 가능
✅ 3) 멀티 이미지 대화 및 비주얼 스토리텔링
- 여러 개의 이미지를 조합하여 이야기 생성 가능
- 예: "이 사진들을 보고 스토리를 만들어 주세요."
✅ 4) Visual Grounding 및 실시간 객체 인식
- 특정 객체를 찾고, 해당 객체를 설명하는 기능
- 예: "이 사진에서 빨간 신발을 신은 사람을 찾아줘."
DeepSeek-VL2는 비전-언어 모델의 새로운 기준을 제시하는 강력한 AI 모델입니다.
✅ 고해상도 이미지 처리 최적화
✅ 빠른 추론 속도와 높은 정확도
✅ 다양한 활용 가능성 (VQA, OCR, 차트 분석, 스토리텔링 등)
앞으로 DeepSeek-VL2는 컴퓨터 비전과 자연어 처리 기술을 결합한 다양한 AI 서비스에 활용될 것으로 기대됩니다.
오픈소스 모델이기 때문에, 개발자들은 이를 자유롭게 활용하여 혁신적인 AI 응용 프로그램을 개발할 수 있습니다. 🚀
https://arxiv.org/pdf/2412.10302
https://github.com/deepseek-ai/DeepSeek-VL2
GitHub - deepseek-ai/DeepSeek-VL2: DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding - deepseek-ai/DeepSeek-VL2
github.com

'인공지능' 카테고리의 다른 글
| 🦢 Goose: 개발자를 위한 강력한 오픈소스 AI 에이전트 (0) | 2025.02.11 |
|---|---|
| AI 정책, 공상과학이 아닌 현실을 반영해야 한다 (0) | 2025.02.11 |
| AI 환각률 0%대 진입! 인공지능 신뢰성, 어디까지 올라갈까? (0) | 2025.02.10 |
| GitHub Copilot의 혁신: AI 개발 비서에서 자율 코딩 에이전트로! (0) | 2025.02.10 |
| 50달러로 AI 최강자에 도전? 's1' 모델이 보여준 혁신의 가능성 (0) | 2025.02.09 |



