🚀 왜 LLM 스케일링이 중요한가?
오늘날 대규모 언어 모델(LLM) 학습은 마치 연금술처럼 느껴질 때가 많습니다. 그러나 성능 최적화는 결코 신비로운 영역이 아닙니다. 특히 TPU(텐서 처리 장치)를 활용한 모델 스케일링은 체계적인 접근만으로도 효율을 극대화할 수 있습니다.
이 블로그에서는 TPU가 어떻게 작동하는지, LLM이 실제 하드웨어에서 어떻게 실행되는지, 그리고 모델 학습과 추론 시 효율적인 병렬 처리 방법에 대해 다룹니다.
- "이 모델을 학습시키는 데 얼마나 비용이 들까?"
- "이 모델을 서비스하기 위해 필요한 메모리 용량은?"
- "AllGather란 무엇인가?"
이러한 질문에 대한 해답을 찾고 있다면, 이 글이 유용할 것입니다.
🧠 본론: LLM 스케일링의 핵심 개념들
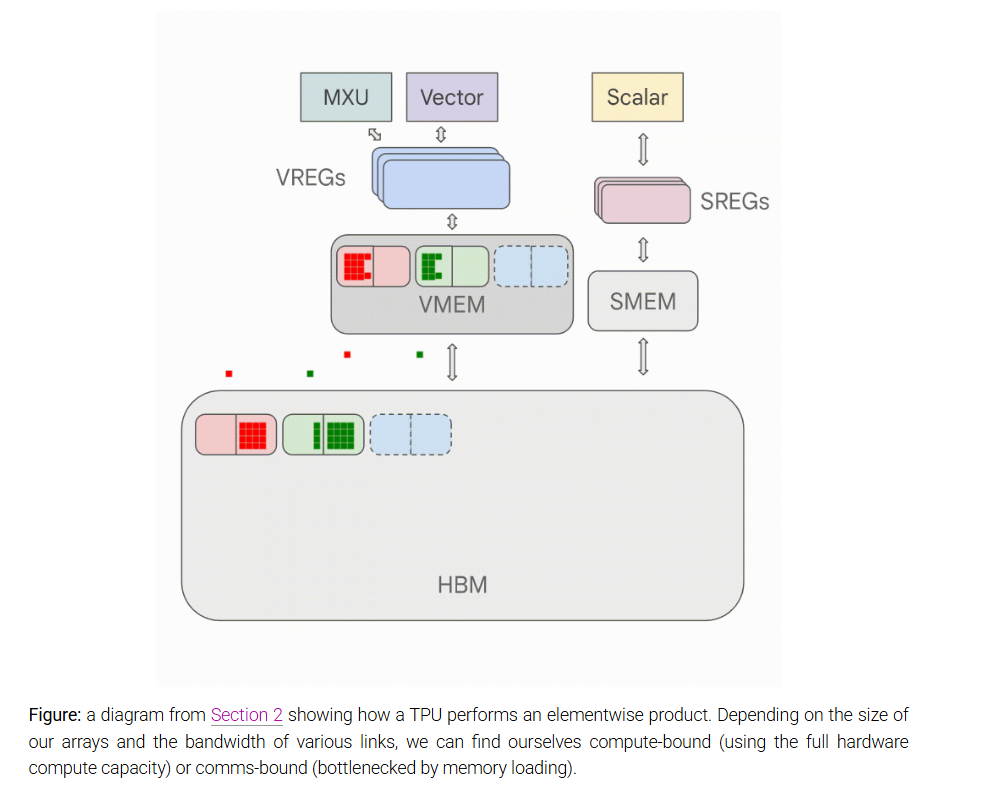
1️⃣ 모델 스케일링이란 무엇인가?
모델 스케일링의 목표는 더 많은 하드웨어 자원을 투입했을 때, 그만큼의 성능 향상이 비례적으로 이루어지는 것(Strong Scaling) 입니다.
하지만 병렬화(Parallelism)를 통한 성능 향상에는 통신 지연이라는 장애물이 존재합니다.
- 컴퓨팅이 빠르더라도
- 노드 간 데이터 전송이 느리면
- 성능 병목 현상이 발생하게 됩니다.
🚩 핵심 포인트:
"컴퓨팅 한계점과 통신 한계점을 명확히 이해하는 것이 최적화의 시작점" 입니다.
2️⃣ Roofline 모델: 성능 한계의 시각화
Roofline 모델은 하드웨어의 성능 한계를 시각화한 분석 도구입니다.
- 계산 성능(Compute) vs 메모리 대역폭(Bandwidth) 간의 균형을 확인할 수 있습니다.
- 이 분석을 통해 병목 구간을 식별하고, 어디서 최적화해야 할지 결정할 수 있습니다.
💡 예시:
- 대규모 행렬 곱셈(Matrix Multiplication)을 수행할 때,
- 계산 속도가 아닌 메모리 읽기/쓰기 속도가 느리다면?
- 이는 전형적인 Memory Bound 상태입니다.
3️⃣ TPU와 GPU의 병렬 처리 구조
TPU 및 현대 GPU는 단순한 하나의 칩이 아닌, 수천 개의 코어로 구성된 복합 네트워크 구조입니다.
- TPU 클러스터 구조:
- 노드 간의 **대역폭(Bandwidth)**과 **지연 시간(Latency)**이 핵심 변수
- AllGather, Scatter, Reduce 같은 데이터 통신 방식이 성능에 영향을 줌
- 병렬 처리 기법:
- 데이터 병렬화(Data Parallelism)
- 모델 병렬화(Model Parallelism)
- 파이프라인 병렬화(Pipeline Parallelism)
- 전문가 병렬화(Expert Parallelism)
각 병렬화 기법은 상황에 따라 다른 효율성을 제공합니다.
📊 Tip:
"작은 모델은 데이터 병렬화로 충분하지만, LLM과 같은 초대형 모델은 모델 병렬화와 파이프라인 병렬화를 병행해야 합니다."
4️⃣ Transformer 수학: 성능 최적화를 위한 모델 분석
Transformer의 핵심은 결국 수학적 연산(Parameters & FLOPs) 입니다.
- 매트릭스 크기(Matrix Size)
- 정규화 위치(Normalization Placement)
- 파라미터 수와 FLOPs 계산
이러한 요소들을 면밀히 분석하면,
- 모델의 메모리 사용량
- 컴퓨팅 시간
- 통신 비용
을 정확하게 예측할 수 있습니다.
⚡ 실전 예제:
- LLaMA-3 모델의 병렬화 적용 방법
- JAX를 활용한 최적화 프로파일링

🔍 모델 스케일링의 시사점
이제 더 이상 "모델이 느린 이유"를 감으로 추측하지 않아도 됩니다.
- Roofline 모델로 성능 병목을 분석하고,
- 병렬화 기법으로 자원 효율성을 극대화하며,
- 하드웨어 특성에 맞게 모델을 설계하는 것이 중요합니다.
🎯 핵심 메시지:
"대규모 언어 모델의 성공은, 단순한 알고리즘이 아닌, 하드웨어 이해와 최적화 전략에 달려 있습니다."
TPU를 활용한 모델 스케일링, 이제 더 이상 어렵지 않습니다.
지금까지의 내용을 바탕으로, 여러분의 LLM이 더 빠르고 효율적으로 작동하도록 최적화해보세요! 🚀
How To Scale Your Model
How to Scale Your Model A Systems View of LLMs on TPUs (Part 0: Intro | Part 1: Rooflines) Training LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of s
jax-ml.github.io

'인공지능' 카테고리의 다른 글
| 🚀 GitHub Copilot, 정말 효과적일까? 개발 생산성을 측정하는 4단계 평가 방법 (0) | 2025.02.06 |
|---|---|
| 🚀 Mistral Small 3: 초고속 AI 모델, Llama 3.3 70B를 능가하다! (0) | 2025.02.06 |
| AI 거장의 예측: 앞으로 5년, 기술의 판이 바뀐다 (0) | 2025.02.05 |
| DeepSeek가 쏘아 올린 2025년 유럽의 AI의 대도약: 기업 경쟁력을 좌우할 6가지 핵심 트렌드 (0) | 2025.02.05 |
| AI 모델의 한계를 시험하다: 인류의 마지막 시험(HLE) 벤치마크의 등장 (0) | 2025.02.04 |



