📌 DeepSeek-R1, 그 이상의 이야기
AI 모델의 진화는 끝이 없습니다. DeepSeek-R1의 등장 이후, AI 커뮤니티는 그 성능과 잠재력에 깊은 관심을 보이고 있습니다. 하지만 단순히 모델을 출시하는 것만으로 끝나지 않았습니다. Open-R1 프로젝트는 DeepSeek-R1의 핵심 요소인 학습 파이프라인과 합성 데이터를 복제하기 위해 시작된 오픈소스 프로젝트로, 단 1주일 만에 괄목할 만한 진전을 이루었습니다.
이 블로그에서는:
- Open-R1 프로젝트의 진행 상황
- DeepSeek-R1에서 얻은 주요 인사이트
- 커뮤니티가 DeepSeek-R1을 활용해 만든 흥미로운 프로젝트들
까지 모두 다루며, 단순한 업데이트를 넘어 AI 분야에서 일어나고 있는 중요한 움직임들을 한눈에 살펴볼 수 있습니다. AI 연구자, 개발자, 그리고 기술 트렌드에 관심 있는 독자라면 끝까지 놓치지 마세요!
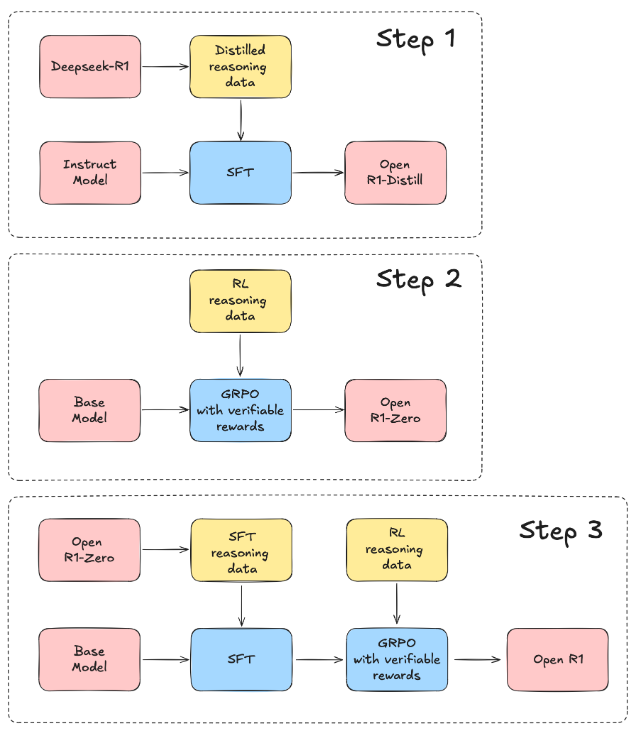
📊 1. Open-R1 프로젝트의 1주일간의 성과
✅ 복제 진행 상황
Open-R1 프로젝트는 DeepSeek-R1의 성능을 재현하기 위해 평가 지표부터 학습 파이프라인, 합성 데이터 생성까지 다양한 영역에서 빠르게 성과를 내고 있습니다.
📈 성능 평가 결과 (MATH-500 벤치마크 기준):
모델 Open-R1 결과 DeepSeek-R1 공식 결과
| 모델 | Open-R1 결과 | DeepSeek-R1 공식 결과 |
| Distill-Qwen-1.5B | 81.6 | 83.9 |
| Distill-Qwen-7B | 91.8 | 92.8 |
| Distill-Qwen-14B | 94.2 | 93.9 |
| Distill-Qwen-32B | 95.0 | 94.3 |
| Distill-Llama-8B | 85.8 | 89.1 |
| Distill-Llama-70B | 93.4 | 94.5 |
이러한 결과는 DeepSeek-R1의 성능을 상당 부분 재현하는 데 성공했다는 것을 보여줍니다.
⚠️ 주요 관찰 사항: 매우 긴 응답 길이
DeepSeek-R1의 독특한 점 중 하나는 평균 6,000 토큰, 최대 20,000 토큰에 달하는 긴 응답입니다. 이는 일반적인 AI 모델의 출력보다 훨씬 길며, GPU 메모리 사용량 증가로 인해 모델 학습과 평가에 상당한 부담을 주고 있습니다.
💡 참고: 평균적인 페이지는 약 500단어로 구성됩니다. DeepSeek-R1의 응답은 평균적으로 10페이지 이상의 분량입니다.
⚙️ 2. 학습 파이프라인: GRPO(그룹화 상대 정책 최적화) 통합
Open-R1 프로젝트의 핵심은 **GRPO(Grouped Relative Policy Optimization)**를 활용한 학습입니다. 이 기술은 다음과 같은 장점을 제공합니다:
- 여러 보상 함수를 동시에 적용 가능
- DeepSpeed ZeRO를 통한 효율적인 대규모 병렬 학습
- vLLM으로 빠른 텍스트 생성 지원
🖥️ 간단한 코드 예제: GRPO 기반 학습
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# 20자 길이에 가까운 결과를 선호하는 더미 보상 함수
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()
이 코드는 보상 기반 학습 구조를 간단히 보여주며, 복잡한 최적화 작업을 수월하게 진행할 수 있습니다.
🧪 3. 합성 데이터 생성: 효율적 스케일링의 도전
DeepSeek-R1의 또 다른 혁신은 합성 추론 데이터(synthetic reasoning data) 생성입니다. 이는 대규모 모델이 스스로 학습 데이터를 생성하고, 더 작은 모델이 이를 기반으로 성능을 향상시킬 수 있다는 것을 보여줍니다.
🚀 성능 최적화 방법:
- 초기에는 8x H100 노드로 실험했지만, 캐시 병목 문제로 비효율 발생
- 이후 4x 8x H100 노드 (총 32개 GPU) 구성으로 전환하여 병렬 처리 효율성 개선
- 스트리밍 방식으로 요청 처리 구조 변경 → GPU 활용률 안정화에 기여
⚡ 스트리밍 방식 코드 개선 예시
기존 배치 처리 방식:
for batch in batch_generator(dataset, bs=500):
active_tasks = []
for row in batch:
task = asyncio.create_task(send_requests(row))
active_tasks.add(task)
if active_tasks:
await asyncio.gather(*active_tasks)
개선된 스트리밍 방식:
active_tasks = []
for row in dataset:
while len(active_tasks) >= 500:
done, active_tasks = await asyncio.wait(
active_tasks,
return_when=asyncio.FIRST_COMPLETED
)
task = asyncio.create_task(send_requests(row))
active_tasks.add(task)
if active_tasks:
await asyncio.gather(*active_tasks)
결과: 대기 시간 최소화, GPU 자원 활용 극대화
🌍 4. DeepSeek-R1의 영향력: 커뮤니티와 업계 반응
DeepSeek-R1은 AI 커뮤니티뿐만 아니라 글로벌 IT 기업 및 미디어에서도 큰 주목을 받고 있습니다.
📰 주요 미디어 등장:
- CNN, Bloomberg, NPR 등 주요 언론 인터뷰
- AWS, Dell, Hyperbolic AI 등의 기업이 DeepSeek-R1 지원 선언
🔥 커뮤니티 프로젝트:
- TinyZero: $30 이하로 학습 가능한 경량 모델
- Mini-R1 튜토리얼: 손쉽게 "아하!" 순간을 경험할 수 있는 학습 자료
- 멀티모달 R1: 텍스트 외에도 이미지, 오디오 데이터까지 확장
📢 5. 무엇을 얻었고, 앞으로의 기대는?
DeepSeek-R1과 Open-R1 프로젝트는 단순한 AI 모델 복제를 넘어, 새로운 연구 방향과 실험의 장을 열었습니다.
- 모델 복제의 가능성을 입증하며, 오픈소스 생태계의 힘을 다시 한 번 보여주었고
- 합성 데이터의 잠재력을 통해 AI 학습 방법론에 새로운 지평을 열었습니다.
https://github.com/huggingface/open-r1
GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
https://huggingface.co/open-r1
open-r1 (Open R1)
Welcome to Open-R1 🐳🤗 Open-R1 is an open initiative to replicate and extend the techniques behind DeepSeek-R1, a state-of-the-art reasoning model, in a fully transparent and collaborative way: https://github.com/huggingface/open-r1 This organization
huggingface.co

'인공지능' 카테고리의 다른 글
| AI 모델의 한계를 시험하다: 인류의 마지막 시험(HLE) 벤치마크의 등장 (0) | 2025.02.04 |
|---|---|
| 🚀 오픈AI의 신작, ‘딥 리서치(Deep Research)’: AI 연구의 새로운 패러다임 (0) | 2025.02.03 |
| Spring AI로 구현하는 효과적인 LLM 에이전트 패턴: Anthropic 연구 기반 실전 가이드 (0) | 2025.02.02 |
| 툴루3(Tülu 3): 인공지능 오픈소스 모델의 새로운 지평을 여는 혁신" (0) | 2025.02.02 |
| DeepSeek의 R1-Zero와 R1: 인간의 한계를 넘는 AI 시스템의 미래 (0) | 2025.02.01 |



