1. Qwen2.5-1M이란?
AI 모델이 점점 더 방대하고 정교해지는 시대에, Qwen2.5-1M은 새로운 기준을 제시합니다. 불과 두 달 전, Qwen2.5-Turbo가 100만 토큰의 컨텍스트 길이를 지원하도록 업그레이드된 이후, 이번에는 Qwen2.5-1M 시리즈가 완전한 오픈소스로 공개되었습니다. 이로써 개발자와 연구자들은 보다 효율적으로 모델을 활용할 수 있는 길이 열렸습니다.
🔹 핵심 특징
- 1M 토큰 컨텍스트 지원
- 기존 Qwen 모델(128K 토큰 지원) 대비 8배 이상의 긴 문맥을 처리할 수 있습니다.
- 새로운 모델 체크포인트 공개
- Qwen2.5-7B-Instruct-1M
- Qwen2.5-14B-Instruct-1M
이 두 모델은 대규모 데이터를 빠르고 정확하게 처리할 수 있도록 설계되었습니다.
- 추론 프레임워크(vLLM 기반) 오픈소스화
- Sparse Attention 및 Dual Chunk Attention 기술을 통해 최대 7배 빠른 속도로 1M 토큰 입력을 처리할 수 있습니다.
2. Qwen2.5-1M의 기술적 특징

🔹 장문 처리 능력 강화
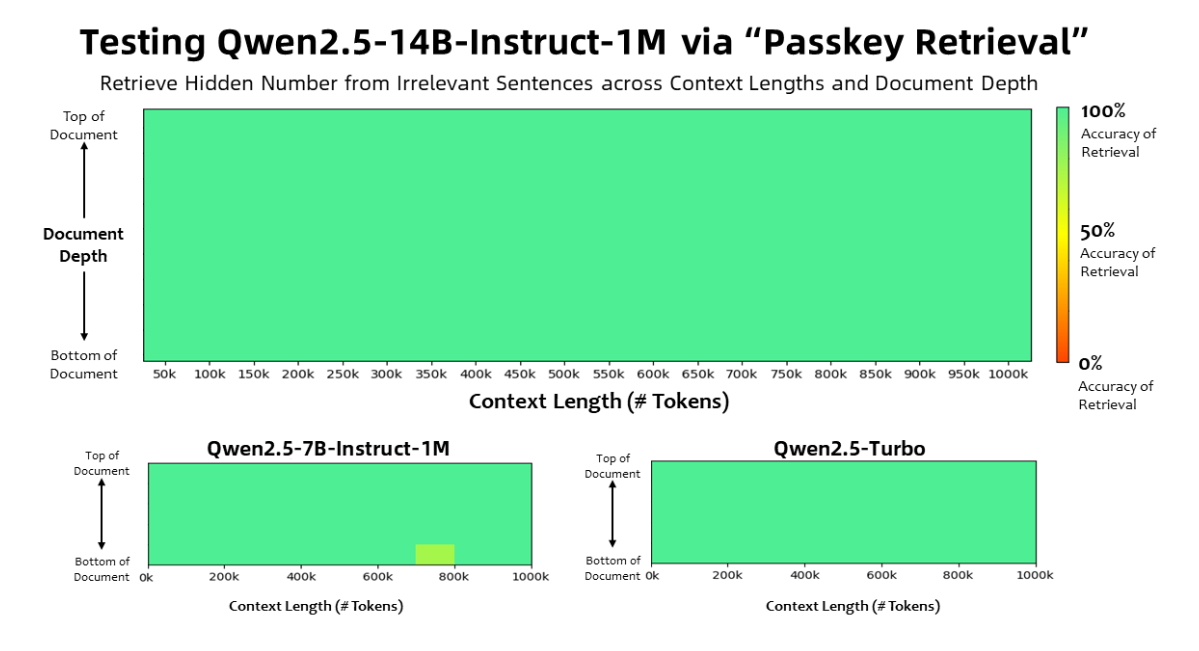
Qwen2.5-1M 모델은 100만 토큰에 달하는 문서에서도 정확하게 정보를 찾아낼 수 있습니다. Passkey Retrieval 테스트에서 7B 모델은 소수의 오류만 보였으며, 14B 모델은 거의 완벽한 정확도를 기록했습니다.
성능 테스트 결과 요약:
- 128K 모델 대비 압도적 우위
64K 이상의 긴 시퀀스에서 Qwen2.5-1M 모델이 128K 버전을 크게 앞섰습니다. - 경쟁 모델 대비 성능 비교
Qwen2.5-14B-Instruct-1M은 Qwen2.5-Turbo는 물론, GPT-4o-mini보다도 더 나은 성능을 보여줬습니다. 이는 오픈소스 모델로서의 강력한 대안임을 입증합니다.
🔹 짧은 문맥 처리 성능 유지
긴 문장을 잘 처리하는 만큼 짧은 문장에서는 성능이 떨어질 것이라고 생각할 수 있지만, Qwen2.5-1M은 짧은 문장 처리에서도 기존 128K 버전과 동일한 성능을 유지했습니다.
- GPT-4o-mini 대비
짧은 텍스트 작업에서 유사한 성능을 보이면서도, 8배 더 긴 문맥을 지원하는 강점을 가집니다.
3. Qwen2.5-1M의 핵심 기술
🔹 Long-Context Training
- 점진적 컨텍스트 길이 확장
- 4K 토큰에서 시작해 256K 토큰까지 점진적으로 확장.
- RoPE 기반 주파수 조정을 통해 안정성을 강화했습니다.
- 지도 학습(Supervised Fine-tuning)
- 짧은 지시문(32K 토큰)과 긴 지시문(256K 토큰)을 혼합하여 긴 문맥 처리 능력을 높이면서도 짧은 문장 처리 성능을 유지했습니다.
- 강화 학습(Reinforcement Learning)
- 8K 토큰까지의 짧은 텍스트로 모델을 훈련해 인간의 선호도에 맞춘 응답을 생성합니다.
🔹 Length Extrapolation (길이 외삽법)
긴 문맥 처리는 모델 훈련 과정에서 상대적 위치 정보의 한계로 인해 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해 Dual Chunk Attention (DCA) 기법을 도입했습니다.
- DCA의 효과
- 32K 토큰으로 훈련된 모델조차 1M 토큰 컨텍스트에서도 거의 완벽한 정확도를 보입니다.
- 추가 훈련 없이도 긴 문맥 처리가 가능하게 됩니다.
🔹 Sparse Attention
긴 문맥 처리를 위해서는 빠른 추론 속도가 필수입니다. Qwen2.5-1M은 Sparse Attention 메커니즘을 적용하여, 최대 7배 빠른 처리 속도를 자랑합니다.
- Chunked Prefill 통합
- 1M 토큰 시퀀스를 직접 처리하는 대신, 32,768 토큰 단위로 나누어 메모리 사용량을 96.7% 감소시켰습니다.
- 추론 최적화
- MInference와 DCA를 결합하여, 긴 문맥에서도 정확성과 속도를 동시에 잡았습니다.
- VRAM 최적화
- Qwen2.5-7B 모델의 경우, 1M 토큰 처리 시 71GB VRAM이 필요했지만, 최적화 후 소비 메모리 대폭 감소.
4. Qwen2.5-1M 설치 및 배포 가이드
🔹 시스템 요구사항
- GPU 권장 사양: Ampere 또는 Hopper 아키텍처 지원 GPU
- CUDA 버전: 12.1 또는 12.3
- Python 버전: 3.9 이상 3.12 이하
VRAM 요구사항 (1M 토큰 처리 기준)
- Qwen2.5-7B-Instruct-1M: 최소 120GB VRAM
- Qwen2.5-14B-Instruct-1M: 최소 320GB VRAM
💡 VRAM이 부족할 경우, 더 짧은 작업에 모델을 활용할 수 있습니다.
🔹 설치 및 실행 방법
- vLLM 저장소 클론 및 설치
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git
cd vllm
pip install -e . -v- API 서비스 시작 (OpenAI 호환)
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill --max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1- 모델과 상호작용 (Python 예제)
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
prompt = "The pass key is 28884. Remember it."
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[{"role": "user", "content": prompt}],
temperature=0,
)
print("Chat response:", chat_response.choices[0].message.content)Qwen2.5-1M은 단순한 업그레이드가 아닌, 대규모 언어 모델의 새로운 기준을 제시하는 모델입니다. 1M 토큰에 달하는 긴 문맥을 빠르고 정확하게 처리할 수 있는 이 모델은, 연구자와 개발자 모두에게 강력한 도구가 될 것입니다.
🔮 앞으로 기대할 점
- 오픈소스 생태계 확장: 누구나 자유롭게 활용할 수 있는 이 모델은 다양한 분야의 AI 개발을 가속화할 것입니다.
- 긴 문맥 활용 분야의 혁신: 법률, 의료, 연구 등 방대한 문서를 다루는 분야에서 혁신적인 성능을 발휘할 것입니다.

https://qwenlm.github.io/blog/qwen2.5-1m/
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens
Tech Report HuggingFace ModelScope Qwen Chat HuggingFace Demo ModelScope Demo DISCORD Introduction Two months after upgrading Qwen2.5-Turbo to support context length up to one million tokens, we are back with the open-source Qwen2.5-1M models and the corre
qwenlm.github.io


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'인공지능' 카테고리의 다른 글
| DeepSeek의 R1-Zero와 R1: 인간의 한계를 넘는 AI 시스템의 미래 (0) | 2025.02.01 |
|---|---|
| OpenAI o3-mini: 빠르고 강력한 소형 AI 모델의 새로운 표준 (0) | 2025.02.01 |
| DeepSeek-R1 1.58비트 동적 양자화 모델 실행 가이드 (0) | 2025.01.31 |
| 🔥 초거대 AI 모델 Qwen2.5-Max 공개! – GPT-4o와 경쟁할 수 있을까? (0) | 2025.01.31 |
| DeepSeek 서비스 이용 전 꼭 알아야 할 개인정보 보호 정책 (0) | 2025.01.28 |



