최근 초거대 언어 모델(LLM)과 멀티모달 언어 모델(VLM)의 발전이 빠르게 이루어지고 있습니다. 하지만 기존 모델의 한계는 분명했습니다. 특히 긴 문맥을 처리하는 능력, 연산 비용, 메모리 효율성에서 많은 도전이 따랐죠. 이런 상황에서 MiniMax-01 시리즈는 독보적인 솔루션으로 주목받고 있습니다.
MiniMax-01은 중국의 MiniMax사가 개발한 최신 LLM/VLM으로, Lightning Attention이라는 새로운 연산 방식을 도입해 성능과 효율성을 대폭 개선했습니다. 이 블로그에서는 MiniMax-Text-01과 MiniMax-VL-01 모델의 혁신적인 특징, 성능, 그리고 실질적인 활용 가능성을 심도 있게 알아보겠습니다.
1. MiniMax-01 시리즈란?
MiniMax-01 시리즈는 MiniMax-Text-01(텍스트 중심)과 MiniMax-VL-01(비전-언어 통합) 모델로 구성되어 있습니다. 두 모델 모두 GPT-4o, Claude-3.5 Sonnet, LLaMA 3.1 같은 최신 상위 모델들과 성능 면에서 비등하거나 우수한 결과를 보여주며, 특히 긴 문맥을 처리할 수 있는 능력에서 독보적인 강점을 가집니다.
주요 개발 목표
- 긴 문맥 처리 능력: 기존 모델이 32K~256K 토큰 처리에 그쳤던 것과 달리, MiniMax-Text-01은 최대 400만 토큰까지 처리할 수 있습니다.
- 효율적 연산: Lightning Attention과 MoE(Mixture of Experts)를 활용하여 연산량과 메모리 사용량을 획기적으로 줄였습니다.
- 멀티모달 통합: MiniMax-VL-01은 512억 개의 비전-언어 데이터로 훈련되어 이미지와 텍스트를 통합적으로 이해합니다.
2. Lightning Attention의 혁신
Lightning Attention은 기존 Transformer의 Self-Attention 메커니즘을 대체한 연산 방식으로, 연산량을 줄이고 긴 문맥 처리에서 효율성을 극대화합니다.
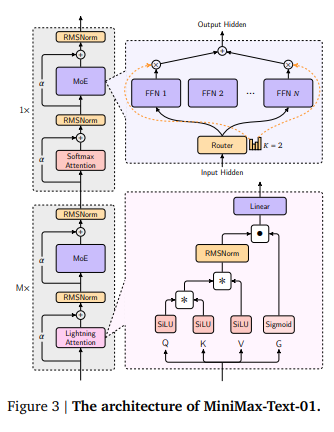
Lightning Attention의 주요 이점
- 연산 효율성: Self-Attention의 복잡도가 문맥 길이에 따라 제곱으로 증가하는 반면, Lightning Attention은 이를 선형으로 줄입니다.
- 메모리 최적화: 긴 문맥에서도 메모리 사용량이 낮아 대규모 모델 훈련과 추론이 가능해졌습니다.
- 하이브리드 구조: Lightning Attention과 Softmax Attention을 혼합하여 성능과 효율성의 균형을 유지했습니다.
3. MiniMax-01의 주요 특징
1) 32개의 전문가 구조(MoE)
MiniMax-01은 **Mixture of Experts(MoE)**를 활용하여 4560억 개의 파라미터 중 459억 개만 활성화합니다. 이를 통해 모델은 연산 자원을 효율적으로 활용하며, 높은 성능을 유지합니다.
2) 긴 문맥 처리
- 훈련 중: 최대 100만 토큰
- 추론 중: 최대 400만 토큰
이는 책, 프로젝트 코드 전체를 문맥으로 활용하거나 복잡한 학습 예제를 다루는 데 적합합니다.
3) 멀티모달 처리 능력
MiniMax-VL-01은 512억 개의 비전-언어 데이터로 훈련되어 이미지와 텍스트 간의 상호작용을 효과적으로 처리합니다.
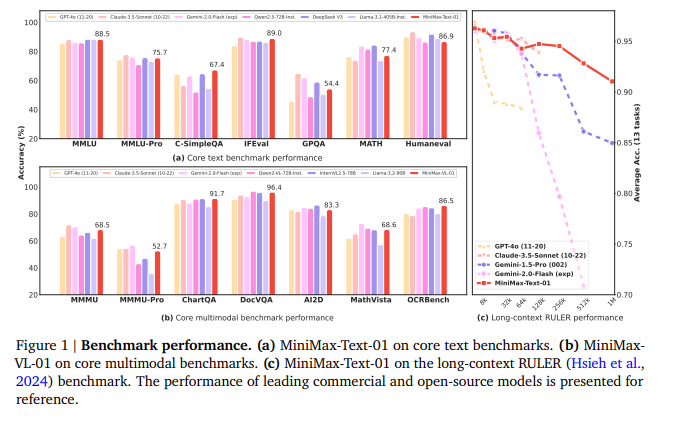
4. 주요 벤치마크 결과: 경쟁 모델 대비 우위
MiniMax-01은 다양한 벤치마크에서 상위권 성적을 기록하며 경쟁 모델을 능가했습니다.
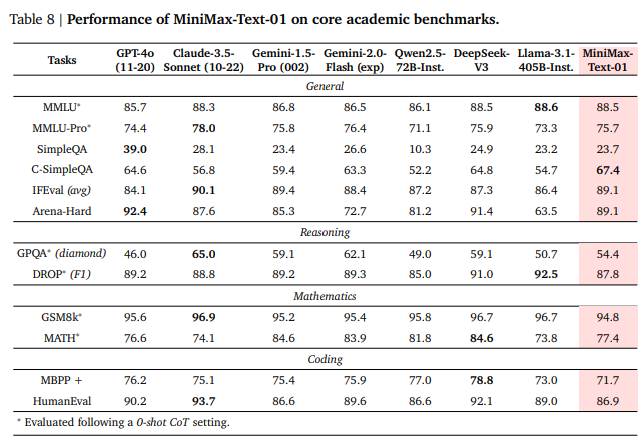
(1) 텍스트 기반 성능
- GPT-4o, Claude-3.5 Sonnet 대비 높은 수치
- 수학 문제 해결(MATH)에서 GPT-4o보다 우수한 결과
- HumanEval 코딩 테스트에서 최상위 성능
(2) 멀티모달 성능
- 이미지 기반 질문-응답(OCRBench)에서 최상위 점수 기록
- AI2D, ChartQA 같은 비전-언어 태스크에서도 뛰어난 성능
(3) 긴 문맥 처리
RULER 벤치마크에서 200K 이상의 문맥 길이에서 독보적인 점수를 기록했습니다.
5. 실용적 장점 및 한계
장점
- 공개 모델: MiniMax-01은 오픈소스로 제공되어 누구나 활용 가능합니다.
- 비용 효율성: 긴 문맥 처리 능력을 감안할 때 비용 대비 성능이 우수합니다.
- 실용성: 실제 사용자 시나리오에서 우수한 성능 검증.
한계
- MoE 기반 복잡성: 파인튜닝 및 배포 시 더 높은 기술적 난이도가 요구됩니다.
- GPU 자원 요구량: 대규모 GPU 환경에서 최적화된 사용이 필요합니다.
6. MiniMax-01의 활용 가능성
MiniMax-01은 긴 문맥 처리와 뛰어난 멀티모달 이해 능력을 바탕으로 다양한 분야에서 활용될 가능성을 보여줍니다.
- 대규모 문서 분석 및 요약
- 멀티모달 데이터 처리(예: 이미지 + 텍스트 기반 Q&A)
- 전문가 수준의 코드 작성 및 디버깅 지원
MiniMax-01 시리즈는 LLM/VLM의 한계를 극복하며 기술 발전에 새로운 가능성을 제시합니다. Lightning Attention과 MoE 구조는 긴 문맥 처리와 비용 효율성을 동시에 달성했으며, 공개 모델로서 연구와 실무에 기여할 잠재력이 큽니다.
https://arxiv.org/pdf/2501.08313
https://github.com/MiniMax-AI/MiniMax-01
GitHub - MiniMax-AI/MiniMax-01
Contribute to MiniMax-AI/MiniMax-01 development by creating an account on GitHub.
github.com
MiniMaxAI/MiniMax-Text-01 · Hugging Face
MiniMax-Text-01 1. Introduction MiniMax-Text-01 is a powerful language model with 456 billion total parameters, of which 45.9 billion are activated per token. To better unlock the long context capabilities of the model, MiniMax-Text-01 adopts a hybrid arch
huggingface.co

'인공지능' 카테고리의 다른 글
| Firecrawl: AI 애플리케이션을 위한 깨끗한 데이터 크롤링의 완벽 솔루션 (0) | 2025.01.19 |
|---|---|
| Codestral 25.01: 오픈 소스 코딩의 새로운 강자 (0) | 2025.01.17 |
| Kotaemon: 문서 QA를 위한 깨끗하고 커스터마이즈 가능한 오픈소스 RAG UI (0) | 2025.01.16 |
| 재미로 알아보는 AGENT ORCHESTRATION과 APPLICATIONS의 Market 현황 - 2025 (0) | 2025.01.16 |
| AutoGen v0.4: 다중 에이전트 AI의 미래를 열다 (0) | 2025.01.16 |



