최근 허깅페이스(Hugging Face)가 소형 언어 모델(sLM, small Language Model)의 추론 성능을 획기적으로 향상시키는 새로운 기술, **테스트-타임 스케일링(test-time scaling)**을 공개했습니다. 이 기술은 대형 언어 모델(LLM, Large Language Model)을 구동하기 어려운 환경에서 유용하며, 특히 코딩이나 수학처럼 명확한 평가 기준이 있는 문제에서 빛을 발합니다. 이번 블로그에서는 테스트-타임 스케일링의 핵심 개념과 이를 통해 달성한 성과를 살펴보겠습니다.
테스트-타임 스케일링이란?
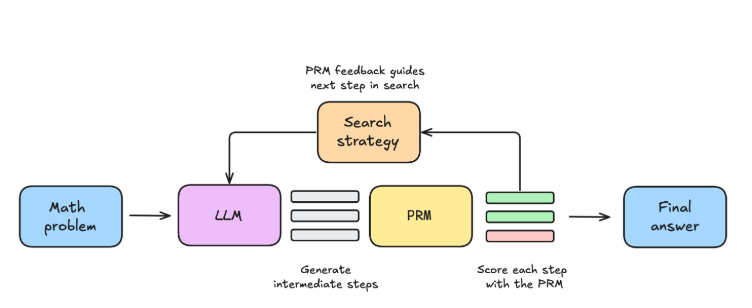
테스트-타임 스케일링은 **테스트-타임 컴퓨트(Test-Time Compute)**라는 접근법을 기반으로, 모델 추론 과정에서 추가적인 컴퓨팅 자원과 시간을 투입하여 응답 품질을 높이는 기술입니다. 허깅페이스는 이 기술을 통해 소형 모델(sLM)이 대형 모델(LLM) 수준의 성능을 낼 수 있도록 돕고, 메모리와 리소스가 제한된 환경에서도 높은 정확도를 유지할 수 있게 했습니다.
허깅페이스가 공개한 테스트-타임 스케일링의 주요 구성 요소는 다음과 같습니다:
- 다수결 투표(Majority Voting): 동일한 질문을 여러 번 모델에 보내 가장 많이 선택된 답을 최종 결과로 선택합니다. 간단한 문제에서 효과적이지만, 복잡한 문제에서는 한계가 있습니다.
- 베스트 오브 N(Best-of-N): 여러 답변을 생성한 뒤 보상 모델(Reward Model)을 사용해 가장 적합한 답변을 선택합니다.
- 가중 베스트 오브 N(Weighted Best-of-N): 답변의 일관성과 자신감을 고려해 더 정확한 결과를 도출하는 방식입니다.
또한, 허깅페이스는 **프로세스 보상 모델(PRM, Process Reward Model)**을 도입하여 최종 답변뿐만 아니라 답변에 도달하는 과정을 평가했습니다. 이를 통해 복잡한 수학 및 코딩 문제에서 높은 정확도를 달성할 수 있었습니다.

라마-3.2: 소형 모델의 가능성을 입증하다
테스트-타임 스케일링은 허깅페이스의 라마(LLaMA)-3.2 모델에서 뛰어난 성과를 보였습니다.
- 라마-3.2 1B 모델은 난이도가 높은 MATH-500 벤치마크에서 라마-3.2 8B 모델에 가까운 성능을 기록했으며, 경우에 따라서는 3B 모델이 70B 모델보다 더 나은 결과를 보여주기도 했습니다.
- 이러한 성과는 특히 가중 베스트 오브 N 방식과 PRM을 결합해 얻은 결과로, 소형 모델이 대형 모델의 성능을 능가할 수 있음을 입증했습니다.
탐색 알고리즘과 최적화 전략
허깅페이스는 테스트-타임 스케일링의 성능을 더욱 향상시키기 위해 여러 탐색 알고리즘과 최적화 전략을 도입했습니다:
- 빔 탐색(Beam Search): 답변을 단계적으로 구분하고 각 단계에서 생성된 답변을 평가하여 최적의 답변을 선택하는 방식입니다. 복잡한 문제에서 유리하지만, 간단한 문제에서는 성능이 다소 저하될 수 있습니다.
- DVTS(Diverse Verifier Tree Search): 다양한 답변 경로를 탐색하며 잘못된 추론 경로를 방지하는 빔 탐색의 변형입니다.
- 연산 최적화 확장 전략(Compute-Optimal Scaling Strategy): 문제의 난이도에 따라 적합한 추론 방식을 동적으로 선택하여 효율성과 정확도를 모두 개선합니다.
오픈 소스화의 의미
허깅페이스는 이번 기술을 오픈 소스로 공개하면서 내부의 추론 프로세스를 단계별로 모두 투명하게 밝혔습니다. 이는 오픈AI의 '생각의 사슬(CoT)'과 같은 기술이 비공개로 운영되는 것과 대조적입니다. 이러한 접근은 기업들이 소형 언어 모델을 활용할 때의 주요 제약 사항인 환각(hallucination), 정확도 부족, 비용 문제를 해결할 수 있는 가능성을 제시합니다.
기업과 개발자에게 주는 혜택
테스트-타임 스케일링은 기업이 오픈 소스 언어 모델을 도입할 때 직면하는 여러 문제를 해결하는 데 도움을 줄 수 있습니다. 특히 메모리 제약이 있거나 LLM을 활용하기 위한 비용이 부담스러운 환경에서 유용하며, 코딩, 수학, 논리적 추론과 같은 명확한 평가 기준이 있는 분야에서 높은 성과를 기대할 수 있습니다.
허깅페이스의 이번 기술 공개는 소형 모델의 한계를 극복하고, 대규모 모델을 활용하기 어려운 환경에서도 강력한 성능을 발휘할 수 있는 새로운 길을 열었습니다. 앞으로의 발전이 더욱 기대되는 기술로, 여러분도 이를 활용한 새로운 가능성을 탐구해보시길 바랍니다.
Scaling test-time compute - a Hugging Face Space by HuggingFaceH4
huggingface.co

'인공지능' 카테고리의 다른 글
| 12 Days of OpenAI 요약 정리 (0) | 2024.12.25 |
|---|---|
| 중국 AI 산업의 전략적 진화: 바이트댄스의 멀티모달 모델 혁신과 가격 경쟁 (0) | 2024.12.24 |
| 작은 거인의 탄생: Microsoft의 복잡한 추론 전문가, Phi-4를 소개합니다! (0) | 2024.12.24 |
| GPT-5, 혁신의 한계인가? 차세대 AI가 넘어야 할 산들 (0) | 2024.12.24 |
| 머신 러닝, 시스템을 혁신하다: ML for Systems (0) | 2024.12.23 |



