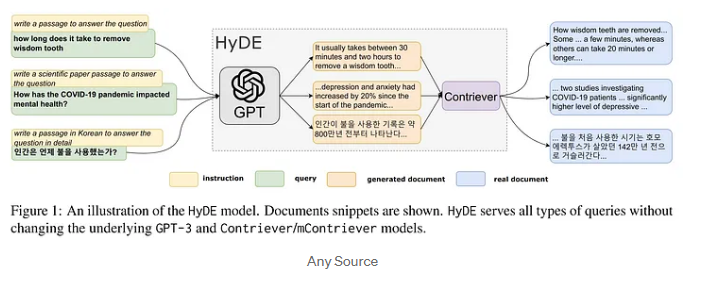
기존 검색의 한계와 HyDE의 탄생 배경
기존의 Embedding 기반 검색 시스템, 특히 RAG(Retrieval-Augmented Generation) 파이프라인에서 활용되는 유사도 검색은 대부분 학습된 데이터 세트를 바탕으로 이루어집니다. 하지만 데이터의 도메인이 기존 학습 데이터와 다를 경우, 검색 성능이 저하되는 문제가 발생할 수 있습니다. 특히 새로운 도메인에 대한 검색에서는 사용자의 질문이 기존 데이터와 연결되지 않아 검색 결과가 부정확해지거나 적합한 맥락을 제공하지 못할 수 있습니다.
이러한 문제를 해결하기 위해 등장한 것이 **HyDE(Hypothetical Document Embeddings)**입니다. HyDE는 사용자의 질문을 토대로 가상의 문서를 생성하여, 이를 검색의 입력으로 사용함으로써 유사도 검색의 정확도를 높이는 방법입니다.
HyDE란 무엇인가요?
HyDE는 Query Expansion 방법의 하나로, 사용자 질문에 대해 가상의 문서를 생성하여 검색의 질을 높이는 접근 방식입니다. LLM(Large Language Model)을 통해 생성된 가상 문서는 사용자의 질문과 유사한 내용을 담고 있으며, 이 문서를 벡터 공간에서 유사도 검색하여 필요한 정보를 제공합니다. HyDE의 핵심 아이디어는, 실제 질문보다 가상의 문서가 검색 성능 면에서 더 효과적일 수 있다는 점에 있습니다. 이를 통해 새로운 도메인의 데이터에서도 검색 성능을 개선할 수 있습니다.
HyDE의 주요 흐름과 Standard 방식과의 차이점
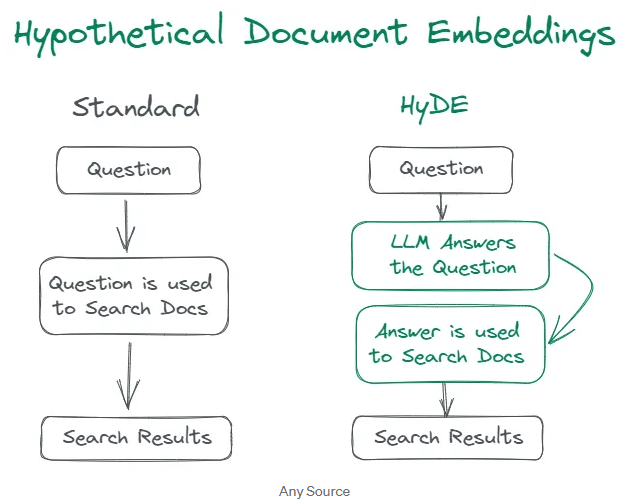
기존 Standard 검색 방식에서는 사용자의 질문을 직접 벡터화하여 검색 엔진에 전달하고, 이에 따른 유사도 검색 결과를 제공합니다. 하지만 HyDE 방식에서는 사용자 질문을 곧바로 검색에 사용하지 않습니다. 대신 사용자의 질문을 LLM을 활용해 가상의 문서로 변환합니다. 이 가상의 문서를 기반으로 벡터 공간에서 유사도 검색을 수행하고, 그 결과를 RAG 파이프라인의 맥락 정보로 활용하게 됩니다.
이로 인해 검색 정확도가 올라가는 이유는 다음과 같습니다.
- 가상의 문서는 질문의 의도를 명확히 반영하고 있어, 단순한 질문보다 더 많은 정보와 패턴을 제공합니다.
- 생성된 가상 문서들이 특정 주제와 관련된 다양한 표현과 키워드를 포함하고 있어, 벡터 유사도 검색 시 더 높은 유사도를 가진 결과를 반환할 확률이 높습니다.
- 여러 개의 가상 문서를 생성한 뒤, 이를 평균화하여 검색에 활용하기 때문에 편향이나 오류를 줄이고 정확성을 높일 수 있습니다.
HyDE가 특히 유용한 경우
HyDE는 아래와 같은 상황에서 효과적인 방법이 될 수 있습니다.
- RAG 파이프라인의 검색 성능이 충분하지 않은 경우: 특히 낮은 Recall Metric을 보이는 상황에서 HyDE는 쿼리 확장(Query Expansion) 효과를 통해 검색 성능을 보완할 수 있습니다.
- 데이터가 새로운 도메인인 경우: 예를 들어 기존 학습된 데이터와 매우 다른 전문 분야의 데이터(의료, 법률, 특수 기술 분야 등)를 검색해야 할 때, 기존 검색 시스템으로는 원하는 결과를 얻기 어려울 수 있습니다. 이때 HyDE는 가상의 문서를 생성하여 기존 모델이 학습하지 못한 패턴과 표현을 보완하여, 더 정확한 검색 결과를 제공합니다.
HyDE는 새로운 도메인의 데이터에서 검색을 개선하고, 기존 검색 시스템의 한계를 보완할 수 있는 강력한 도구입니다. RAG 파이프라인의 성능을 높이고자 한다면, HyDE 방식이 매우 효과적인 선택이 될 수 있습니다.

'인공지능' 카테고리의 다른 글
| 새로운 시대의 검색: ChatGPT Search로 심화된 지식 탐구 (0) | 2024.11.01 |
|---|---|
| 모듈형 RAG의 첫걸음, Linear Pattern으로 쉽게 이해하는 고도화된 검색 기반 AI 모델 (0) | 2024.10.31 |
| 왜 우리는 다른 사람이 만든 앱에 맞춰야 할까요? GitHub Spark로 맞춤형 애플리케이션 시대를 열다 (3) | 2024.10.31 |
| Self-RAG란? 전통적인 RAG 한계를 넘어서는 새로운 검색 방식 (0) | 2024.10.30 |
| AI 생성 콘텐츠 탐지: 구글 'SynthID'와 워터마킹 기술의 중요성 (0) | 2024.10.29 |



