언어 모델(LLM)의 성능이 급속히 발전하면서 이를 정확하게 평가하는 방법론의 필요성이 대두되었습니다. 기존의 벤치마크는 언어 모델의 능력을 충분히 반영하지 못하고 있으며, 실전 문제를 다룰 수 있는 보다 도전적인 평가 기준이 요구됩니다. 이러한 요구에 부응하기 위해 등장한 SWE-Bench는 실전 소프트웨어 엔지니어링을 위한 현실적이고 지속 가능한 테스트 환경을 제공하여 언어 모델의 한계를 평가하고 향후 발전 방향을 제시합니다.
SWE-Bench의 개요
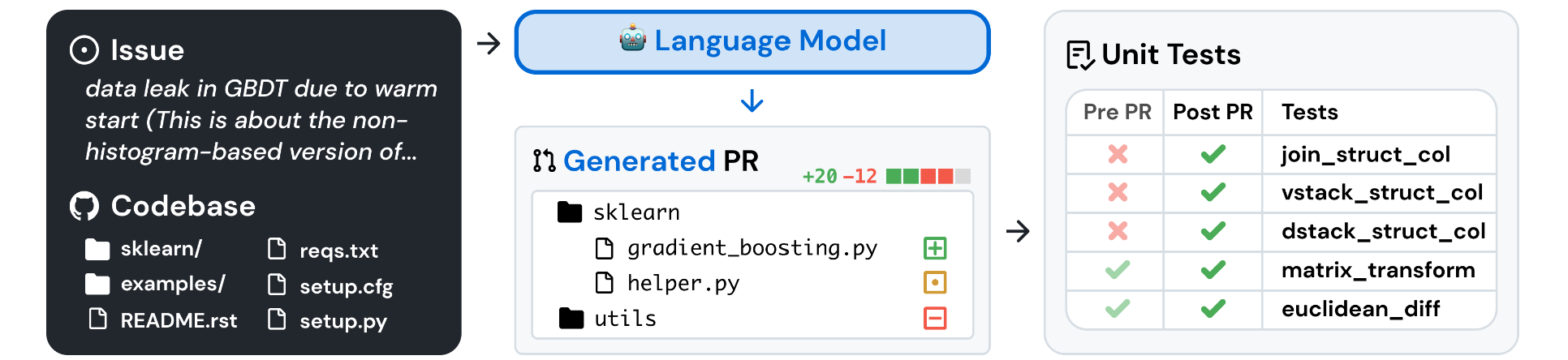
SWE-Bench는 실제 소프트웨어 엔지니어링 문제를 다루는 언어 모델 평가 프레임워크로, GitHub의 12개 인기 Python 오픈소스 저장소에서 가져온 2,294개의 실제 문제로 구성됩니다. 이 문제들은 주로 버그 보고나 새로운 기능 요청과 관련된 GitHub 이슈와 해당 이슈를 해결한 풀 리퀘스트(PR)로 이루어져 있습니다. 모델은 주어진 코드베이스와 문제 설명을 바탕으로 코드베이스를 수정하여 문제를 해결해야 합니다.
SWE-Bench의 목표는 언어 모델이 주어진 문제를 얼마나 효과적으로 이해하고 코드베이스를 수정하여 문제를 해결할 수 있는지를 평가하는 것입니다. 이를 통해 SWE-Bench는 기존의 코드 생성 문제와는 달리, 실제 소프트웨어 엔지니어링 환경에서 요구되는 복잡한 기술적 능력을 테스트합니다.
SWE-Bench의 테스트 방법론
SWE-Bench의 각 샘플은 GitHub의 오픈소스 Python 저장소에서 가져온 문제와 이를 해결한 PR을 바탕으로 구성됩니다. 모델은 **GitHub 이슈의 원본 텍스트(문제 진술)**와 코드베이스에 대한 접근 권한을 제공합니다. 이 정보를 바탕으로 모델은 코드베이스의 파일을 편집하여 문제를 해결해야 합니다. 중요한 것은, 모델이 문제를 해결하기 위해 생성한 코드는 해당 문제와 관련된 단위 테스트를 통해 검증된다는 점입니다.
SWE-Bench는 다음 두 가지 테스트 세트를 사용하여 모델을 평가합니다:
- FAIL_TO_PASS 테스트: PR 적용 전에는 실패하지만 적용 후 통과하는 테스트로, 모델이 문제를 해결했는지를 검증합니다.
- PASS_TO_PASS 테스트: PR 적용 전후 모두 통과하는 테스트로, 코드베이스의 기존 기능이 손상되지 않았음을 확인합니다.
모델이 생성한 코드가 두 테스트 세트를 모두 통과해야 해당 GitHub 문제를 완전히 해결했다고 평가됩니다. 이는 모델이 문제를 해결함과 동시에 코드베이스의 안정성을 유지할 수 있는지를 확인하는 중요한 과정입니다.
SWE-Bench의 주요 특징
- 실전 소프트웨어 엔지니어링 문제: SWE-Bench의 각 문제는 복잡하고 대규모 코드베이스와 연관되어 있으며, 모델이 실제 소프트웨어 엔지니어링 작업에서 요구되는 높은 수준의 기술과 지식을 보여줄 것을 요구합니다.
- 지속 가능하고 확장 가능한 벤치마크: SWE-Bench는 GitHub의 Python 저장소에서 지속적으로 새로운 문제를 수집할 수 있기 때문에, 새로운 테스트 사례를 추가하여 언어 모델의 최신 성능을 지속적으로 평가할 수 있습니다.
- 다양하고 복잡한 입력: SWE-Bench의 문제 설명은 평균 195단어로 비교적 길고, 코드베이스는 수천 개의 파일로 구성됩니다. 이를 해결하기 위해 모델은 코드베이스 내에서 수정해야 할 특정 부분을 식별하고 이를 효과적으로 편집하는 능력을 필요로 합니다.
- 견고한 평가 방식: SWE-Bench의 각 문제에는 최소 하나의 FAIL_TO_PASS 테스트가 포함되어 있으며, 모델이 문제를 해결하는지 여부뿐만 아니라 기존 기능이 손상되지 않는지도 평가합니다.
- 크로스 컨텍스트 코드 편집: SWE-Bench는 단일 함수나 클래스가 아닌, 코드베이스의 여러 위치에 걸쳐 수정이 이루어지도록 요구합니다. 이는 기존의 코드 생성 벤치마크와 달리, 모델이 더 넓은 범위에서 코드 이해와 편집 능력을 갖추었는지를 평가하는 중요한 요소입니다.
기대 효과
SWE-Bench는 기존의 단순한 코드 생성 문제를 넘어, 실제 소프트웨어 개발 환경에서 발생하는 다양한 문제를 해결할 수 있는 언어 모델 개발에 기여할 것입니다. 이를 통해 향후 언어 모델이 더욱 실용적이고, 지능적이며 자율적으로 발전할 수 있는 기반을 마련하게 될 것입니다. 현재 최고 성능의 모델인 Claude 2조차도 SWE-Bench에서 1.96%의 문제만 해결할 수 있었으므로, SWE-Bench는 언어 모델의 성능을 한층 더 높일 수 있는 도전적인 과제를 제공합니다.
SWE-Bench를 통해 언어 모델이 실제 소프트웨어 엔지니어링 문제를 해결하는 능력을 지속적으로 개선해 나갈 수 있기를 기대합니다.

'인공지능' 카테고리의 다른 글
| NVIDIA의 새로운 도전: 700억 개의 매개변수로 GPT-4o와 Claude 3.5를 능가하다 (0) | 2024.10.23 |
|---|---|
| Devin AI: 소프트웨어 개발의 미래를 열다 (0) | 2024.10.23 |
| Langchain으로 LLM 효율 높이기: 비용 절감과 응답 속도 향상을 위한 캐시 활용법 (0) | 2024.10.22 |
| 적은 자원으로도 모델의 재학습이 가능하다? Unsloth로 효율적인 CPT 구현하기 (0) | 2024.10.21 |
| CPU에서도 거대한 언어 모델을 가볍게! Microsoft의 혁신적 오픈소스 프레임워크, bitnet.cpp (0) | 2024.10.21 |



