이 글은 LLM 학습 과정에서 **에이전트가 스스로 실험·분석·개선까지 수행하는 자동 리서치(autoresearch)**가 실제로 어떤 성과를 냈는지에 대한 사례를 다룹니다.
약 2일간의 자동 실험을 통해 nanochat 모델의 학습 효율이 약 11% 개선되었고, 이 변화가 단순한 실험이 아니라 실제로 의미 있는 결과라는 점이 검증되었습니다.
전통적으로 사람이 직접 해오던 모델 튜닝 작업을 에이전트가 어떻게 대체하고 있는지, 그리고 이것이 앞으로의 LLM 개발에 어떤 시사점을 주는지 정리해보겠습니다.
nanochat과 자동 리서치 실험의 배경
nanochat은 경량 LLM 학습을 실험하기 위한 프로젝트로, 비교적 단순한 구조 덕분에 **학습 속도와 효율을 평가하는 지표(Time to GPT-2)**로 자주 활용됩니다.
이번 실험은 nanochat에 autoresearch 튜닝 에이전트를 붙여, 사람이 개입하지 않고도 모델 학습 설정을 자동으로 개선할 수 있는지 확인하는 목적에서 시작됐습니다.
실험을 진행한 사람은 Andrej Karpathy로, 그는 오랜 기간 수작업으로 신경망 학습을 최적화해 온 연구자입니다. 그렇기에 이번 결과는 더욱 인상적입니다.
자동 리서치의 핵심 성과: 숫자로 본 개선 효과
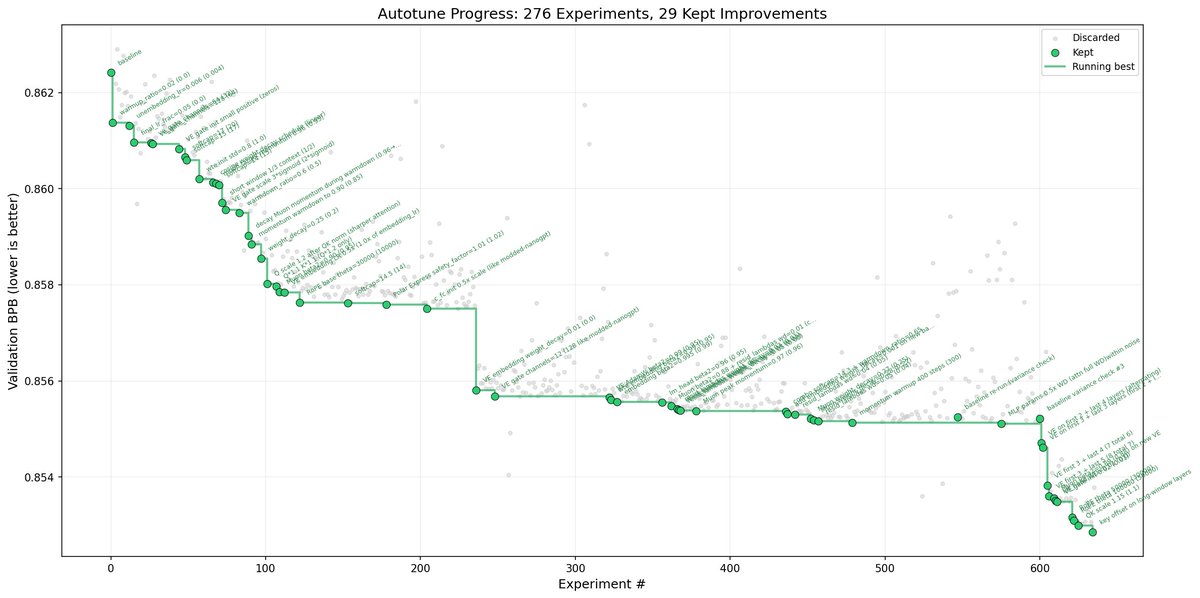
자동 리서치 에이전트는 약 700여 개의 변경 실험을 순차적으로 수행하며, 그중 검증 손실(validation loss)을 실제로 개선한 약 20개의 변경 사항을 선별했습니다.
그 결과는 명확했습니다.
- Time to GPT-2
- 기존: 2.02시간
- 개선 후: 1.80시간
- 약 11% 학습 효율 향상
- depth=12 모델에서 찾은 개선 사항이 **더 큰 모델(depth=24)**에도 그대로 전이됨
- 모든 변경 사항이 서로 충돌 없이 누적(additive) 적용 가능
즉, 단발성 트릭이 아니라 구조적으로 의미 있는 개선이었습니다.
에이전트가 찾아낸 주요 튜닝 포인트들
이번 자동 리서치에서 발견된 개선 사항들은 대부분 “사람이 놓치기 쉬운 설정들”이었습니다.
1. QKnorm 스케일러 누락 문제
- 파라미터 없는 QKnorm에 스케일러 배수가 빠져 있었음
- 그 결과 attention이 지나치게 퍼져 있었고,
- 에이전트가 적절한 multiplier를 찾아 attention을 더 날카롭게(sharpen) 조정
2. Value Embedding 정규화 부족
- Value Embedding에 정규화(regularization)가 전혀 적용되지 않음
- 에이전트가 이를 감지하고 정규화 적용 → 성능 개선
3. Banded Attention 설정 미튜닝
- banded attention이 지나치게 보수적으로 설정돼 있었음
- 튜닝을 통해 attention 범위를 더 효율적으로 조정
4. AdamW 베타 값 오류
- AdamW 옵티마이저의 betas 값이 비정상적으로 설정돼 있었음
- 에이전트가 이를 수정
5. Weight Decay 스케줄 조정
- weight decay 스케줄을 재조정하여 학습 안정성 향상
6. 네트워크 초기화 튜닝
- 초기화 방식 자체를 개선하여 수렴 속도 개선
이 모든 작업은 사람의 직접 개입 없이, 실험 결과를 바탕으로 다음 실험을 계획하며 진행됐습니다.
“사람의 일”을 대신한 에이전트의 의미
흥미로운 점은, 이 과정이 전통적인 연구 흐름과 매우 닮아 있다는 점입니다.
- 가설 수립
- 구현
- 실험
- 결과 분석
- 다음 실험 설계
이 전 과정을 에이전트가 스스로 수행했습니다.
새로운 이론을 만들어낸 것은 아니지만, 실제로 효과 있는 개선을 찾아내고 누적 적용했다는 점에서 충분히 “실용적인 연구”였습니다.
확장 가능성: 에이전트 스웜과 병렬 자동 튜닝
이 실험은 단일 에이전트, 단일 코드베이스(nanochat)에서 이뤄졌습니다.
하지만 여기서 제시된 방향은 훨씬 큽니다.
- 여러 에이전트를 동시에 띄워 병렬 실험
- 작은 모델에서 검증된 아이디어를
→ 점점 더 큰 모델로 승격 - 인간은 가장자리에서만 개입
이는 모든 LLM 프론티어 연구소가 결국 도달하게 될 구조라는 전망도 함께 제시됩니다.
이번 사례가 주는 메시지는 분명합니다.
- 자동 리서치는 이미 실용 단계에 들어왔다
- 사람이 수년간 해오던 튜닝 작업을 에이전트가 재현하고, 일부는 능가한다
- 평가 가능한 지표가 있다면, 그 문제는 자동 리서치의 대상이 될 수 있다
앞으로 모델 성능 경쟁의 “최종 보스전”은
더 좋은 아이디어가 아니라,
더 잘 자동화된 실험 시스템이 될 가능성이 큽니다.
지금 다루고 있는 문제에도
“이걸 에이전트에게 맡길 수는 없을까?”
한 번쯤 고민해볼 시점입니다.
https://x.com/karpathy/status/2031135152349524125
X의 Andrej Karpathy님(@karpathy)
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking u
x.com

'인공지능' 카테고리의 다른 글
| Popover API란 무엇인가? 브라우저 네이티브 툴팁이 바꾸는 웹 접근성의 기준 (0) | 2026.03.11 |
|---|---|
| 잇따른 장애 이후, Amazon이 AI 지원 코드 변경에 ‘시니어 승인’을 의무화한 이유 (0) | 2026.03.11 |
| 스크립트 한 줄로 웹페이지를 AI 에이전트로 만드는 방법: page-agent 상세 분석 (0) | 2026.03.11 |
| 에이전트 시대, 문학적 프로그래밍을 다시 바라봐야 하는 이유 (0) | 2026.03.11 |
| Gemini Embedding 2: 네이티브 멀티모달 임베딩의 새로운 기준 (0) | 2026.03.11 |



