최근 추천 시스템 분야에서는 기존의 임베딩 기반 최근접 탐색(Nearest Neighbor Search) 방식에서 벗어나 생성형 검색(Generative Retrieval) 방식이 빠르게 확산되고 있습니다. 이 방식은 대규모 언어 모델(LLM)이 추천 아이템을 직접 생성하는 구조로 동작하며, 아이템을 **Semantic ID(SID)**라는 토큰 시퀀스로 표현합니다. 하지만 실제 서비스 환경에서는 재고 상태, 콘텐츠 최신성, 정책 조건 등 다양한 비즈니스 로직을 반드시 충족해야 합니다. 기존의 LLM 디코딩 방식은 이러한 제약 조건을 직접 처리하기 어려워 잘못된 아이템을 생성하는 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위해 Google DeepMind와 YouTube 연구팀은 **STATIC(Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding)**이라는 새로운 프레임워크를 제안했습니다. STATIC은 기존의 트라이(trie) 기반 제약 디코딩 구조를 희소 행렬 기반 구조로 변환하여 GPU 및 TPU 환경에서 효율적으로 동작하도록 설계되었습니다. 이를 통해 기존 방식 대비 최대 948배 빠른 디코딩 성능을 달성하며, 대규모 추천 시스템 환경에서도 안정적인 제약 조건 처리를 가능하게 합니다.
이 글에서는 생성형 검색의 개념부터 기존 방식의 한계, STATIC 프레임워크의 구조와 동작 방식, 성능 개선 결과, 실제 서비스 적용 사례까지 핵심 내용을 정리합니다.
생성형 검색(Generative Retrieval)의 개념
추천 시스템은 전통적으로 다음과 같은 방식으로 동작했습니다.
- 사용자와 아이템을 벡터로 임베딩
- 유사도 기반 최근접 탐색(Nearest Neighbor Search)
- 가장 유사한 아이템을 추천
하지만 최근에는 대규모 언어 모델(LLM)을 활용한 생성형 검색 방식이 등장하면서 새로운 접근 방식이 활용되고 있습니다.
생성형 검색의 특징은 다음과 같습니다.
- 아이템을 **Semantic ID(SID)**라는 토큰 시퀀스로 표현
- 추천 과정을 Autoregressive Decoding(자기회귀 디코딩) 방식으로 수행
- 모델이 직접 추천 아이템을 생성
이 방식은 기존 검색 기반 추천보다 더 유연한 추천이 가능하지만, 현실적인 서비스 환경에서는 중요한 문제가 발생합니다.
생성형 검색의 문제: 제약 조건 처리
실제 서비스 환경에서는 추천 결과가 다음과 같은 조건을 반드시 만족해야 합니다.
- 재고가 있는 상품만 추천
- 최신 콘텐츠만 노출
- 정책 위반 콘텐츠 제외
- 특정 기간 내 콘텐츠만 허용
하지만 일반적인 LLM 디코딩은 이러한 비즈니스 제약 조건을 직접 반영하지 못합니다.
그 결과 다음과 같은 문제가 발생합니다.
- 존재하지 않는 아이템 ID 생성
- 재고가 없는 상품 추천
- 정책 위반 콘텐츠 노출
이 문제를 해결하기 위해 일반적으로 Trie(프리픽스 트리) 구조를 사용해 유효한 토큰만 선택하도록 제한합니다.
기존 Trie 기반 접근 방식의 한계
Trie 기반 제약 디코딩은 개념적으로는 단순하지만 GPU나 TPU 같은 가속기 환경에서는 큰 성능 문제를 발생시킵니다.
1. 메모리 접근 비효율
Trie 구조는 포인터 기반 구조입니다.
이 구조는 다음과 같은 특징을 갖습니다.
- 비연속 메모리 접근
- 랜덤 메모리 패턴
- Pointer chasing 발생
GPU와 TPU는 연속적인 메모리 접근을 기반으로 성능을 최적화하기 때문에 이러한 구조는 성능을 크게 저하시킵니다.
특히 High-Bandwidth Memory(HBM)의 burst 기능을 제대로 활용하지 못하게 됩니다.
2. 컴파일 구조와의 비호환성
TPU와 GPU는 정적 계산 그래프(static computation graph) 기반으로 동작합니다.
대표적인 예가 Google의 XLA 컴파일러입니다.
하지만 Trie 기반 알고리즘은 다음과 같은 특징을 가집니다.
- 데이터 의존적 분기
- 재귀적 탐색
- 동적 제어 흐름
이러한 구조는 정적 그래프와 맞지 않아 다음과 같은 문제가 발생합니다.
- CPU와 GPU 간 데이터 왕복
- 성능 저하
- 추론 지연 증가
STATIC 프레임워크 개요
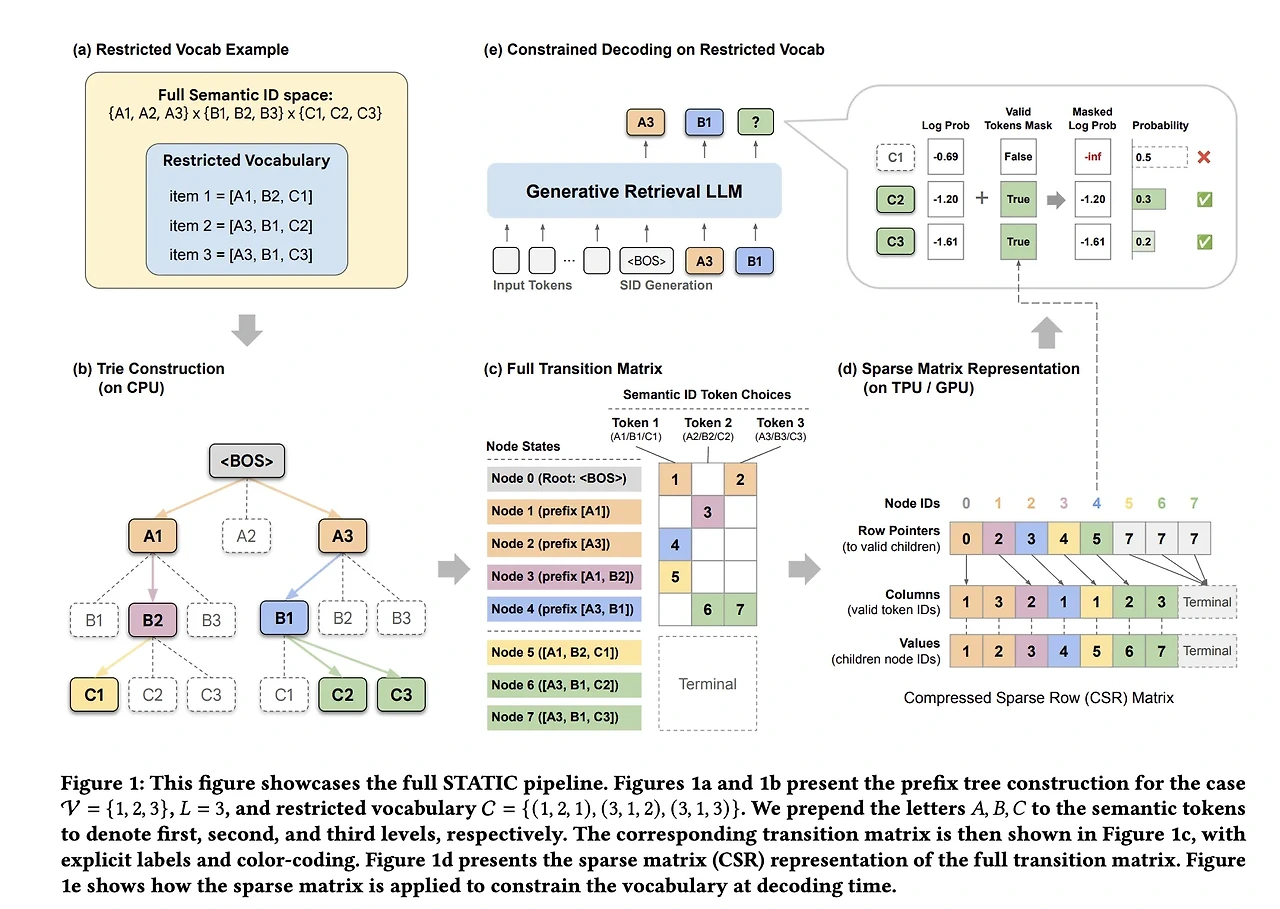
STATIC은 이러한 문제를 해결하기 위해 Trie 구조를 Sparse Matrix 구조로 변환합니다.
STATIC의 핵심 아이디어는 다음과 같습니다.
트리를 탐색하는 방식 대신, 트리를 행렬 연산으로 변환한다.
구체적으로는 다음과 같은 구조를 사용합니다.
- Prefix Trie → Compressed Sparse Row(CSR) Matrix
- 그래프 탐색 → Vectorized Sparse Matrix Operation
이를 통해 불규칙적인 트리 탐색을 GPU 친화적인 벡터 연산으로 변환합니다.
STATIC의 하이브리드 디코딩 구조
STATIC은 성능과 메모리 효율을 동시에 확보하기 위해 2단계 디코딩 전략을 사용합니다.
1단계: Dense Masking
초기 디코딩 단계에서는 분기 수가 매우 많습니다.
이를 해결하기 위해 STATIC은 다음 방식을 사용합니다.
- 비트 패킹된 boolean tensor 사용
- Dense masking 적용
- O(1) 시간 복잡도 lookup
이 단계는 **처음 2개 레이어(d=2)**에서 사용됩니다.
이 구간이 계산 비용이 가장 높은 구간이기 때문입니다.
2단계: Vectorized Node Transition Kernel (VNTK)
깊은 레벨에서는 STATIC이 **VNTK(Vectorized Node Transition Kernel)**을 사용합니다.
이 방식의 특징은 다음과 같습니다.
- branch-free 커널
- speculative slice 방식
- 고정 크기 slice 사용
실제 자식 노드 수와 관계없이 **고정 크기의 slice(Bt)**를 사용하기 때문에 전체 연산이 하나의 정적 계산 그래프로 유지됩니다.
시간 복잡도 개선
STATIC의 중요한 특징 중 하나는 I/O 복잡도 감소입니다.
기존 방식
O(log |C|)
STATIC
O(1)
여기서 |C|는 제약 조건 집합의 크기입니다.
즉, 제약 조건 수가 증가해도 성능이 거의 영향을 받지 않습니다.
성능 평가 결과
Google TPU v6e 환경에서 다음 조건으로 성능 테스트가 수행되었습니다.
- 모델 크기: 3B parameters
- Batch size: 2
- Beam size: 70
결과는 다음과 같습니다.
| 방법 | 단계당 지연 시간(ms) | 전체 추론 시간 비율 |
| STATIC | +0.033 | 0.25% |
| PPV Approximate | +1.56 | 11.9% |
| Hash Bitmap | +12.3 | 94.0% |
| CPU Trie | +31.3 | 239% |
| PPV Exact | +34.1 | 260% |
주요 성능 결과는 다음과 같습니다.
- CPU Trie 대비 948배 속도 향상
- Binary search 방식 대비 최대 1033배 향상
- Semantic ID vocabulary 증가에도 지연 시간 거의 일정
메모리 사용량
STATIC은 대규모 추천 시스템에서도 사용할 수 있도록 메모리 사용량을 최적화했습니다.
예시 기준
- 2천만 아이템 vocabulary
- 최대 HBM 사용량: 약 1.5GB
실제 환경에서는 다음과 같은 특성 때문에 사용량이 더 낮습니다.
- Semantic ID 클러스터링
- 비균일 분포
실제 사용량은 최대치의 약 75% 이하입니다.
용량 계획 기준은 다음과 같습니다.
100만 개 제약 조건당 약 90MB HBM
YouTube 실제 적용 사례
STATIC은 실제로 YouTube 추천 시스템에 적용되었습니다.
적용 목적은 다음과 같습니다.
최근 7일 이내 업로드된 영상만 추천
운영 환경 조건
- 2천만 개 신선 콘텐츠 vocabulary
- 제약 조건 100% 준수
A/B 테스트 결과는 다음과 같습니다.
- 7일 이내 영상 조회수 +5.1% 증가
- 3일 이내 영상 조회수 +2.9% 증가
- 클릭률(CTR) +0.15% 증가
이는 제약 조건 기반 추천이 실제 사용자 경험 개선에도 영향을 준다는 것을 보여줍니다.
Cold Start 문제 해결
생성형 검색의 또 다른 문제는 Cold Start입니다.
즉, 학습 데이터에 없던 새로운 아이템을 추천하기 어렵습니다.
STATIC은 특정 아이템 집합을 제약 조건으로 설정하여 Cold Start 아이템 추천을 가능하게 합니다.
Amazon Reviews 데이터셋 실험 결과
- 기존 모델: Recall@1 = 0.00%
- STATIC 적용: 의미 있는 성능 개선
실험 환경
- 모델: 1B Gemma architecture
- 토큰 길이: L=4
- Vocabulary 크기: 256
STATIC 프레임워크는 생성형 검색 시스템에서 발생하는 제약 조건 디코딩 문제를 근본적으로 해결하는 접근 방식입니다.
핵심 특징은 다음과 같습니다.
첫째, Trie 기반 그래프 탐색을 CSR Sparse Matrix 연산으로 변환하여 GPU/TPU 친화적인 구조를 구현했습니다.
둘째, Dense Masking과 VNTK를 결합한 하이브리드 디코딩 구조를 통해 높은 성능과 메모리 효율을 동시에 확보했습니다.
셋째, 기존 방식 대비 최대 948배 성능 향상을 달성하면서도 제약 조건 수 증가에 영향을 받지 않는 O(1) 복잡도를 구현했습니다.
넷째, YouTube 실제 서비스 환경에서 100% 제약 준수와 추천 성능 개선을 동시에 입증했습니다.
생성형 검색은 향후 추천 시스템의 핵심 기술로 자리 잡을 가능성이 높습니다. STATIC과 같은 프레임워크는 LLM 기반 추천 시스템을 실제 산업 환경에서 안정적으로 운영하기 위한 중요한 기술적 기반이 될 것으로 기대됩니다.
Google AI Introduces STATIC: A Sparse Matrix Framework Delivering 948x Faster Constrained Decoding for LLM Based Generative Retr
Google AI Introduces STATIC: A Sparse Matrix Framework Delivering 948x Faster Constrained Decoding for LLM Based Generative Retrieval
www.marktechpost.com

'인공지능' 카테고리의 다른 글
| GPT-5.4 기반 에이전트 구축을 위한 프롬프트 설계 가이드 (0) | 2026.03.08 |
|---|---|
| AI 에이전트 조직 운영 오케스트레이션 도구 Paperclip: 인간 개입 없이 회사를 운영하는 구조 (0) | 2026.03.06 |
| Fabric: AI 프롬프트를 체계적으로 관리하고 활용하는 오픈소스 프레임워크 (0) | 2026.03.06 |
| Claude Code 메모리 문제 해결 방법: QMD 검색 엔진과 /recall 스킬로 만드는 컨텍스트 중심 AI 워크플로우 (0) | 2026.03.06 |
| GPT-5.4 공개: 차세대 AI 모델의 주요 기능과 기술적 특징 정리 (0) | 2026.03.06 |



