LLM(대규모 언어 모델)을 활용한 서비스에서 가장 큰 과제 중 하나는 신뢰할 수 있는 실시간 웹 데이터 수집과 정제입니다.
단순한 HTML 스크래핑으로는 자바스크립트 렌더링, 봇 차단, 불필요한 콘텐츠 제거 같은 문제를 해결하기 어렵습니다.
이 글에서는 LLM에 최적화된 웹 크롤러 & 스크래퍼 API인 Teracrawl이 무엇인지, 어떤 배경에서 등장했으며, 어떤 특징과 장점을 가지는지, 그리고 실제로 어떻게 사용할 수 있는지까지 정리해봅니다.
Teracrawl의 등장 배경과 필요성
기존의 웹 스크래핑 방식은 다음과 같은 한계를 가지고 있습니다.
- JavaScript 기반 SPA 사이트에서 콘텐츠 추출이 어려움
- 봇 차단, 광고, 트래커로 인해 크롤링 성공률 저하
- HTML 그대로 수집되어 LLM이 바로 활용하기 어려움
- 대량 요청 시 성능과 안정성 문제 발생
Teracrawl은 이러한 문제를 해결하기 위해 실제 관리형 Chrome 브라우저 기반으로 동작하며, 결과물을 LLM이 바로 사용할 수 있는 Markdown 형태로 변환하는 것을 목표로 설계된 API입니다.
Teracrawl이란 무엇인가?
Teracrawl은 프로덕션 환경에서 바로 사용할 수 있는 웹 크롤링 & 스크래핑 API입니다.
웹사이트를 입력하면 내부적으로 자바스크립트 렌더링, 콘텐츠 추출, 불필요한 요소 제거 과정을 거쳐 깨끗한 Markdown 결과물을 반환합니다.
특히 Browser.cash의 원격 브라우저 인프라를 기반으로 동작하여, 단순 HTTP 요청 방식과 달리 보호된 사이트에서도 높은 성공률을 보입니다.
Teracrawl의 핵심 특징
1. LLM에 최적화된 출력 결과
Teracrawl의 가장 큰 강점은 출력 포맷입니다.
- 복잡한 HTML → 의미 구조가 살아있는 Markdown으로 변환
- RAG, 프롬프트 컨텍스트 윈도우에 바로 사용 가능
- 불필요한 태그와 노이즈 제거로 토큰 사용량 절감
LLM이 “이해하기 쉬운 데이터” 형태로 제공된다는 점이 핵심입니다.
2. 스마트한 2단계 크롤링 방식
Teracrawl은 페이지 특성에 따라 자동으로 크롤링 전략을 선택합니다.
- Fast Mode
- 정적 페이지 또는 SSR 페이지에 최적화
- 리소스 재사용, 무거운 자산 차단
- 빠른 응답 속도
- Dynamic Mode
- 복잡한 SPA 사이트 대응
- hydration 및 렌더링 완료까지 대기
- Fast Mode 실패 시 자동 전환
이 구조 덕분에 다양한 웹 환경에서도 안정적인 결과를 제공합니다.
3. Search + Scrape를 하나의 API로
Teracrawl은 단순히 URL을 긁는 도구가 아닙니다.
- Google 검색 쿼리 실행
- 상위 N개 결과를 병렬로 스크래핑
- 검색 + 콘텐츠 수집을 단일 API 호출로 처리
LLM 에이전트나 자동화 파이프라인에서 특히 유용한 구조입니다.
4. 높은 동시성과 안정성
- 세션 풀 기반 구조로 다중 페이지 동시 처리
- 타임아웃 자동 처리 및 에러 복구
- 광고, 트래커, 애널리틱스 차단으로 성능 개선
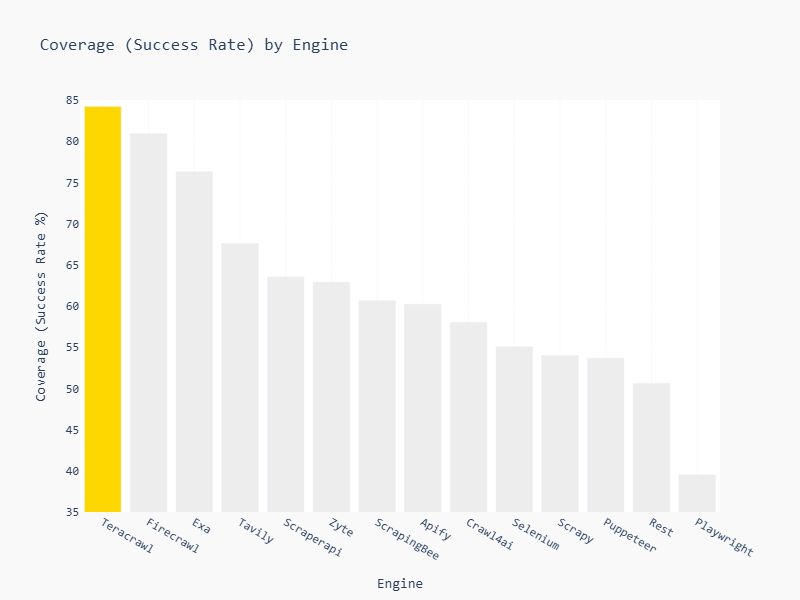
실제 벤치마크에서도 Teracrawl은 **1,000개 URL 평가 기준 최고 커버리지(82~84%)**를 기록했습니다.
주요 기능 정리
- Search + Scrape: 검색과 스크래핑을 한 번에
- Direct Scraping: 특정 URL을 Markdown으로 변환
- 스마트 콘텐츠 추출: article, main 영역 자동 감지
- 노이즈 제거: 스크립트, 네비게이션, base64 이미지 제거
- Docker 지원: 어디서든 손쉽게 배포 가능
Teracrawl 빠른 시작 방법
사전 준비
- Node.js 18 이상
- Browser.cash API Key
- /crawl 기능 사용 시 SERP 서비스(browser-serp) 실행 필요
API 사용 예시로 이해하기
1. 검색 + 크롤링 API (/crawl)
Google 검색 후 상위 결과를 동시에 스크래핑합니다.
curl -X POST http://localhost:8085/crawl \
-H "Content-Type: application/json" \
-d '{
"q": "What is the capital of France?",
"count": 3
}'
응답에는 각 URL의 Markdown 콘텐츠와 성공 여부가 포함됩니다.
2. 단일 페이지 스크래핑 (/scrape)
특정 URL을 바로 Markdown으로 변환합니다.
curl -X POST http://localhost:8085/scrape \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com/blog/post-1"
}'
3. SERP 검색만 사용 (/serp/search)
콘텐츠 스크래핑 없이 검색 결과만 필요할 때 활용합니다.
설정을 통해 조절 가능한 요소들
- 브라우저 세션 수(POOL_SIZE)
- 탭 동시 처리 수
- Fast / Slow 모드 타임아웃
- 최소 콘텐츠 길이 기준
- 디버그 로그 활성화 여부
이를 통해 서비스 환경과 트래픽 규모에 맞게 튜닝할 수 있습니다.
Teracrawl이 가지는 의미와 기대점
Teracrawl은 단순한 웹 크롤러가 아니라,
LLM이 바로 활용할 수 있는 데이터 파이프라인의 핵심 구성 요소에 가깝습니다.
- LLM 친화적인 Markdown 출력
- 보호된 사이트에서도 높은 성공률
- 검색과 스크래핑의 통합
- 프로덕션 환경을 고려한 안정성
RAG, AI 에이전트, 실시간 데이터 수집이 중요한 환경이라면
Teracrawl은 웹 데이터를 LLM의 언어로 바꿔주는 실질적인 해답이 될 수 있습니다.
https://github.com/BrowserCash/teracrawl/
GitHub - BrowserCash/teracrawl: High-performance web crawler API optimized for LLMs. Turn any search or website into clean Markd
High-performance web crawler API optimized for LLMs. Turn any search or website into clean Markdown using remote browsers. - BrowserCash/teracrawl
github.com




