
이 글은 LangChain이 실제로 여러 Deep Agent 기반 애플리케이션을 개발하고 운영하면서 얻은 Deep Agent 평가(Evaluation) 방법에 대한 경험과 학습 내용을 정리한 기술 블로그입니다.
단순한 LLM 평가와 달리, Deep Agent는 상태를 가지며 여러 단계의 의사결정을 수행하기 때문에 평가 방식 역시 훨씬 정교해야 합니다. 이 글에서는 LangChain이 DeepAgents CLI, LangSmith Assist, 개인 이메일 어시스턴트, Agent Builder를 만들며 정립한 Deep Agent 평가의 핵심 패턴과 실무적인 접근 방식을 중심으로 설명합니다.
Deep Agent와 평가 방식의 기본 개념
Deep Agent란 무엇인가
Deep Agent는 단순히 질문에 답변하는 LLM과 달리, 다음과 같은 특징을 가집니다.
- 여러 단계의 의사결정을 수행
- 도구 호출(tool calling)을 포함한 실행 경로를 가짐
- 파일, 메모리, 외부 상태 등 다양한 상태(state)를 생성 및 변경
- 단일 입력이 아닌 다중 턴 대화를 처리
이러한 특성 때문에 평가 역시 단순한 “정답 비교” 방식으로는 충분하지 않습니다.
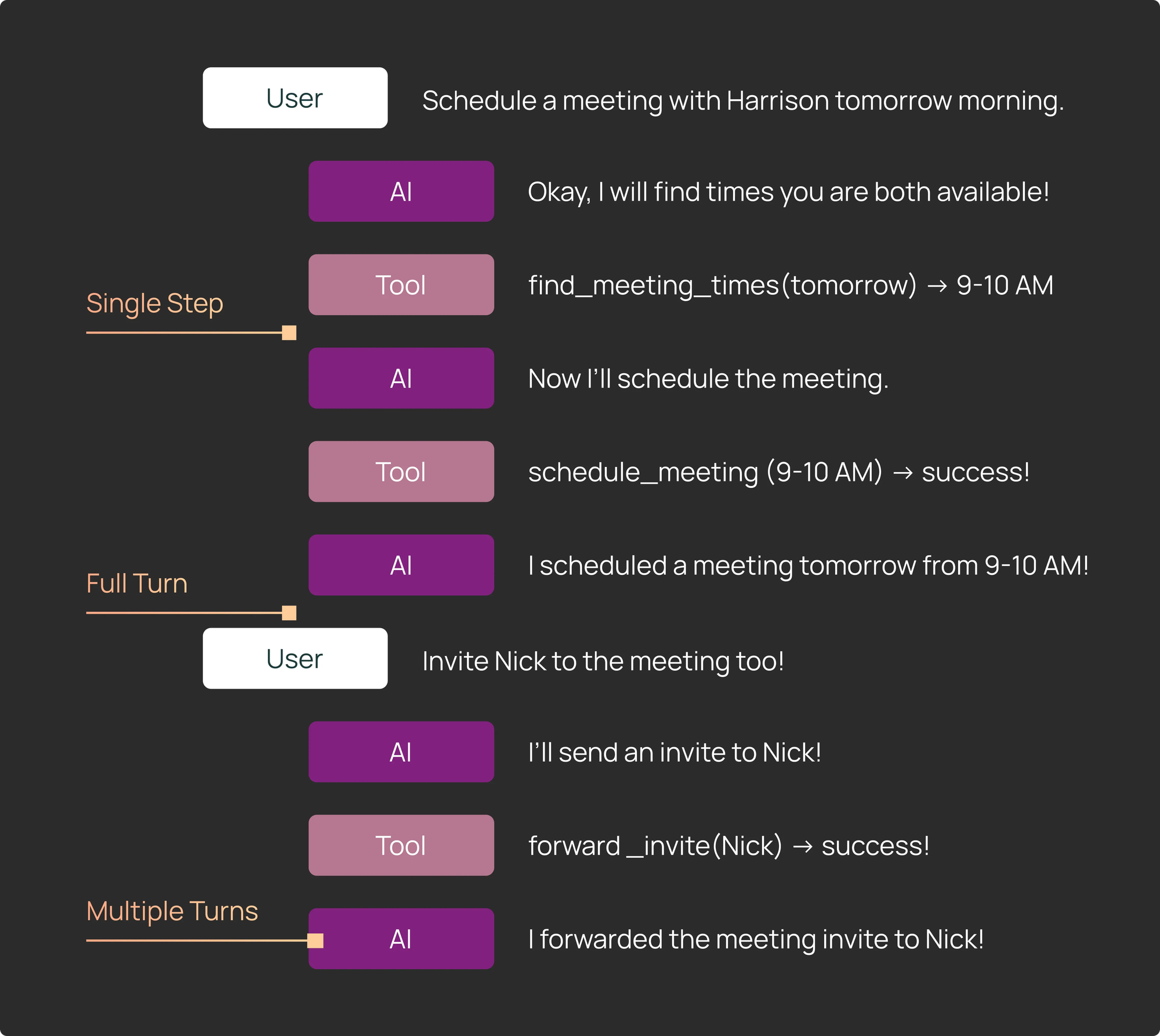
Agent 실행 방식 정의
LangChain에서는 Agent 실행을 다음 세 가지 방식으로 구분합니다.
- Single step
에이전트 루프를 한 단계만 실행하여, 다음에 어떤 행동을 선택하는지 확인 - Full turn
하나의 입력에 대해 에이전트를 끝까지 실행 (여러 도구 호출 포함 가능) - Multiple turns
여러 번의 full turn을 실행하여 실제 사용자와의 다중 턴 상호작용을 시뮬레이션
평가 대상 요소
Deep Agent 평가 시 확인할 수 있는 요소는 다음과 같습니다.
- Trajectory: 어떤 도구를 어떤 인자로 호출했는지의 전체 흐름
- Final response: 사용자에게 반환된 최종 응답
- Other state: 파일, 아티팩트 등 실행 중 생성된 기타 상태 정보
1. Deep Agent는 데이터 포인트별 맞춤형 테스트 로직이 필요하다
기존 LLM 평가는 모든 데이터 포인트를 동일한 방식으로 처리합니다.
하지만 Deep Agent는 이 접근이 통하지 않습니다.
이유
- 각 테스트 케이스마다 성공 조건이 다름
- 최종 응답뿐 아니라 도구 호출, 파일 변경, 메모리 업데이트까지 확인해야 함
- 단일 평가 기준으로는 에이전트의 동작을 충분히 검증할 수 없음
실제 예시: 일정 관리 에이전트
사용자가 “오전 9시 이전에는 회의를 잡지 말아달라”고 요청했을 때, 다음을 검증해야 합니다.
- 에이전트가 memories.md 파일에 대해 edit_file 도구를 호출했는지
- 최종 메시지에서 해당 설정이 저장되었음을 사용자에게 알렸는지
- 실제 파일 내용에 9시 이전 회의를 피한다는 정보가 포함되었는지
이를 위해 LangSmith는 Pytest 및 Vitest 기반의 테스트에서 각 테스트마다 서로 다른 assertion과 LLM-as-judge 평가를 지원합니다.
2. Single Step 평가는 빠르고 효율적인 검증 수단이다
LangChain의 경험상, 전체 테스트의 약 절반은 Single Step 평가였습니다.
Single Step 평가가 유용한 이유
- 에이전트의 특정 의사결정 지점을 정확히 검증 가능
- 불필요한 전체 실행을 피하여 토큰 비용 절감
- 문제 발생 지점을 빠르게 발견 가능
대표적인 검증 사례
- 올바른 검색 도구를 호출했는가
- 올바른 디렉터리를 탐색했는가
- 메모리를 업데이트해야 하는 상황을 정확히 인식했는가
LangGraph의 스트리밍 및 인터럽트 기능을 활용하면, 도구 실행 직전 상태에서 에이전트를 중단하고 결과를 점검할 수 있습니다.
3. Full Agent Turn 평가는 전체 흐름을 검증한다
Single Step이 유닛 테스트라면, Full Turn 평가는 통합 테스트에 가깝습니다.
Full Turn에서 검증 가능한 요소
- Trajectory
특정 도구가 실행되었는지 여부만 확인하고, 정확한 실행 순서는 중요하지 않은 경우 - Final Response
코딩, 리서치처럼 결과물의 품질이 중요한 작업에 적합 - Other State
코드 파일, 리서치 결과물, 생성된 아티팩트 등을 직접 검증
LangSmith에서는 Full Turn 실행을 트레이스 형태로 확인할 수 있어, 지연 시간, 토큰 사용량부터 개별 모델 호출까지 상세 분석이 가능합니다.
4. Multiple Turn 평가는 실제 사용자 경험을 시뮬레이션한다
다중 턴 평가는 현실적인 사용자 상호작용을 재현하는 데 필수적입니다.
하지만 단순히 입력을 고정하면 문제가 발생합니다.
문제점
- 에이전트가 예상과 다른 응답을 하면 이후 입력이 의미를 잃음
LangChain의 해결 방법
- 각 턴 이후 결과를 검증
- 결과가 기대한 경우에만 다음 턴 실행
- 기대와 다를 경우 즉시 테스트 실패 처리
이 방식은 모든 분기 케이스를 모델링하지 않고도 안정적인 다중 턴 평가를 가능하게 합니다.
5. 평가 환경 세팅은 Deep Agent 평가의 핵심이다
Deep Agent는 상태를 가지기 때문에 매 테스트마다 깨끗한 환경 초기화가 필수입니다.
이유
- 이전 실행 결과가 남아 있으면 테스트 결과가 불안정해짐
- 재현 가능한 평가가 어려워짐
실제 적용 사례
- 코딩 에이전트: Docker 컨테이너 또는 샌드박스 환경 사용
- DeepAgents CLI: 테스트마다 임시 디렉터리 생성 후 실행
API 요청 모킹의 중요성
LangSmith Assist처럼 외부 API에 의존하는 경우, 실 API 호출은 비용과 속도 문제를 유발합니다.
- Python: vcr로 HTTP 요청 기록 및 재생
- JavaScript: 프록시 서버를 통해 fetch 요청 리플레이
이를 통해 테스트 속도를 높이고 디버깅을 단순화할 수 있습니다.
LangChain의 경험은 한 가지 분명한 메시지를 전달합니다.
- Deep Agent 평가는 단순한 출력 비교가 아니다
- 의사결정 과정, 상태 변화, 환경까지 포함한 종합적인 검증이 필요하다
- Single Step, Full Turn, Multiple Turn 평가를 상황에 맞게 조합해야 한다
- 재현 가능한 환경과 유연한 테스트 프레임워크가 필수다
Deep Agent 기반 애플리케이션이 점점 복잡해지는 만큼, 평가 역시 함께 진화해야 합니다.
이 글에서 소개한 패턴들은 Deep Agent를 실제 서비스 수준으로 운영하려는 개발자와 팀에게 현실적인 기준과 방향성을 제시합니다.
https://blog.langchain.com/evaluating-deep-agents-our-learnings/
Evaluating Deep Agents: Our Learnings
Over the past month at LangChain, we shipped four applications on top of the Deep Agents harness: * DeepAgents CLI: a coding agent * LangSmith Assist: an in-app agent to help with various things in LangSmith * Personal Email Assistant: an email assistant t
blog.langchain.com

'인공지능' 카테고리의 다른 글
| Hunyuan Translation Model 1.5 완전 정리: 1.8B부터 7B까지, 실시간 번역을 위한 차세대 오픈소스 모델 (0) | 2026.01.02 |
|---|---|
| Lightning-Fast RL for LLM Reasoning and Agents - LLM 추론과 에이전트를 위한 초고속 강화학습 프레임워크, AReaL 소개 (0) | 2026.01.02 |
| 자연어로 만드는 AI 미니 앱 빌더, Google Opal 핵심 정리 (0) | 2026.01.02 |
| AI 음악 생성 솔루션 SongGeneration Studio 기술 개요와 활용 방법 정리 (0) | 2026.01.02 |
| 1.96B 파라미터로 128K 컨텍스트를 처리하는 경량 LLM, Youtu-LLM-2B 기술 정리 (0) | 2026.01.02 |



