
이 글에서는 NVIDIA가 공개한 Nemotron-Cascade-14B-Thinking 모델에 대해 정리합니다. 해당 모델이 어떤 배경에서 만들어졌는지, 학습 파이프라인은 어떻게 구성돼 있는지, 그리고 실제 벤치마크 결과를 통해 어떤 성능을 보이는지를 중심으로 설명합니다. 또한 기존 대형 추론 모델들과 비교했을 때의 특징과, 실제 사용 시 알아두어야 할 채팅 템플릿 구조까지 함께 살펴봅니다.
Nemotron-Cascade-14B-Thinking 모델 개요
Nemotron-Cascade-14B-Thinking은 범용 추론 성능을 목표로 설계된 대규모 언어 모델입니다.
Qwen3-14B Base 모델을 기반으로 후처리 학습(post-training) 되었으며, 순차적이고 도메인별 강화학습을 적용한 것이 핵심 특징입니다.
특히 이 모델은 thinking 모드 전용으로 설계되어, 복잡한 문제 해결과 고급 추론 작업에 최적화돼 있습니다. 같은 계열의 Nemotron-Cascade-8B와 달리, 단순 응답보다는 내부 추론 과정이 중요한 작업을 중심으로 활용됩니다.
학습 파이프라인과 강화학습 구조
Nemotron-Cascade의 학습 과정은 단계적으로 구성돼 있습니다.
1. 다단계 SFT(Supervised Fine-Tuning)
초기 단계에서는 다단계 SFT를 통해 모델이 기본적인 언어 이해와 문제 해결 능력을 갖추도록 합니다.
2. Cascade RL 적용
이후 여러 도메인에 걸쳐 Cascade RL이 적용됩니다. 이 방식은 도메인별로 순차적인 강화학습을 수행해, 특정 영역의 성능을 높이면서도 이전에 학습한 영역의 성능 저하를 최소화하는 것이 목적입니다.
3. RLHF의 역할
정렬(alignment)을 위한 RLHF가 사전 단계로 사용되며, 단순한 선호 최적화를 넘어 복잡한 추론 능력을 크게 향상시키는 데 기여합니다. 이후 도메인별 RLVR 단계에서도 기존 벤치마크 성능이 유지되거나 오히려 개선되는 특징을 보입니다.
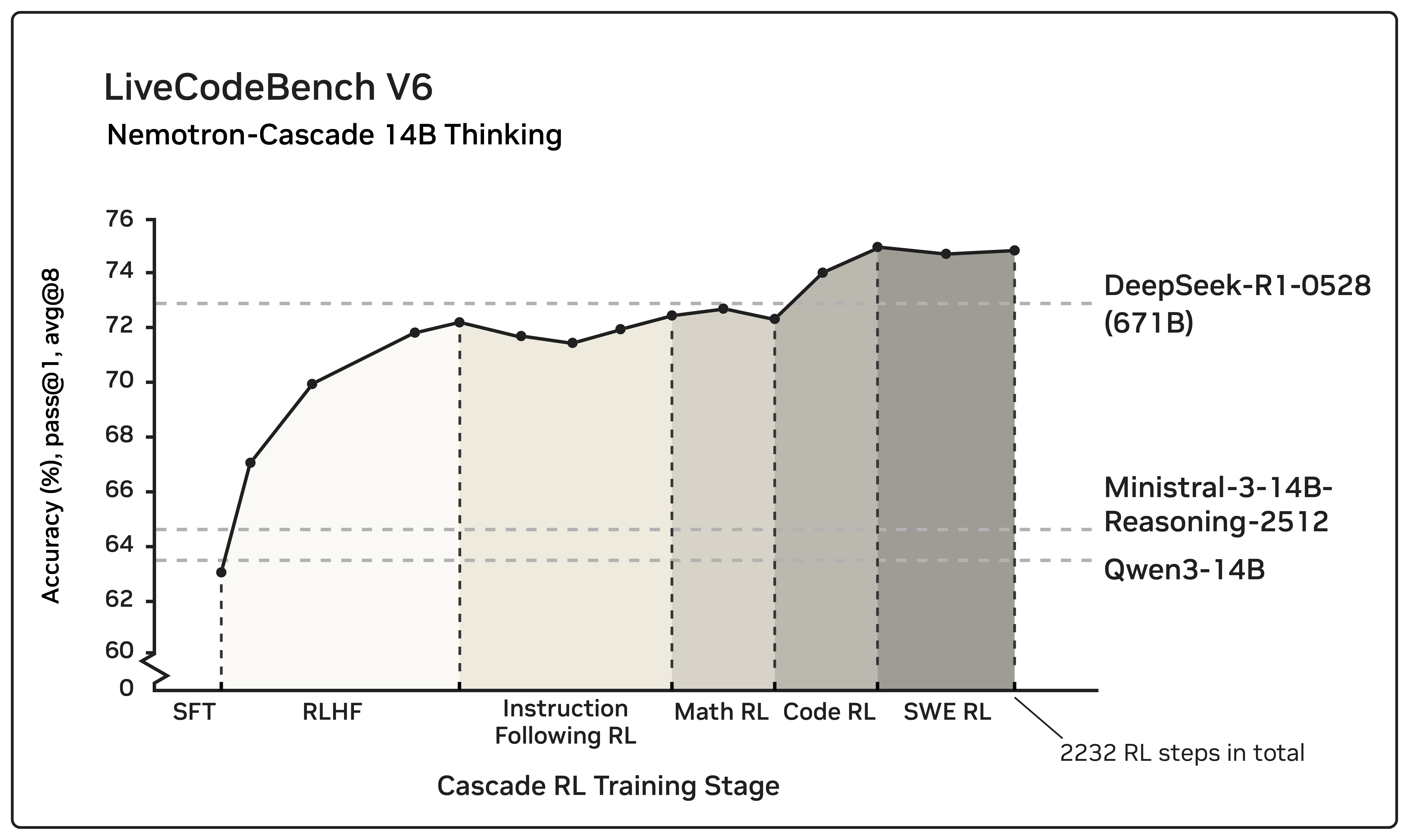
벤치마크 성능 결과 분석
Nemotron-Cascade-14B-Thinking은 다양한 영역의 벤치마크에서 평가됐습니다.
평가 범위는 일반 지식 추론, 정렬 및 지시 따르기, 수학, 경쟁 프로그래밍, 소프트웨어 엔지니어링, 도구 호출 능력까지 포함합니다.
평가 설정
- 최대 생성 길이: 64K 토큰
- Temperature: 0.6
- Top-p: 0.95
- Metric: Pass@1
주요 성능 특징
- 대부분의 벤치마크에서 동급 최고 수준 성능 달성
- 특히 LiveCodeBench v5, v6, Pro 전 구간에서 매우 강력한 성능을 보임
- DeepSeek-R1-0528(671B)와 비교해도 다수의 코드 및 추론 벤치마크에서 우수한 결과 기록
대형 파라미터 모델 대비 상대적으로 작은 규모임에도 불구하고, 코드 생성과 수학적 추론, 경쟁 프로그래밍 영역에서 높은 효율성을 보여주는 점이 특징입니다.
Chat Template 및 사용 방식
Nemotron-Cascade-14B-Thinking은 Qwen3 스타일 ChatML 템플릿을 따릅니다.
thinking 모드 전용 모델이기 때문에 입력 형식이 중요합니다.
기본 사용 규칙
- 사용자 입력 끝에 " /think" 태그를 추가해야 합니다.
- 토큰화 오류를 방지하기 위해 태그 앞에는 공백이 포함됩니다.
- 멀티턴 대화에서는 맥락 길이를 줄이기 위해 모델 출력의 최종 요약만 대화 기록에 포함합니다.
- 이후 사용자 입력에서는 " /no_think" 태그를 사용합니다.
간단한 사용 예시
User: 이 문제를 단계적으로 분석해줘 /think
Assistant: (thinking 모드로 상세 추론 후 결과 요약 출력)
User: 방금 결과를 기반으로 다른 예시도 보여줘 /no_think
이 방식은 긴 추론 과정을 효율적으로 관리하면서도 대화 흐름을 유지하는 데 목적이 있습니다.
Nemotron-Cascade-14B-Thinking은 도메인별 강화학습과 thinking 모드 전용 설계를 통해, 고급 추론과 코드 중심 작업에서 매우 경쟁력 있는 성능을 보여주는 모델입니다.
특히 대형 모델에 비해 상대적으로 효율적인 구조로, 실제 개발 및 연구 환경에서 활용 가치가 높습니다.
앞으로 복잡한 문제 해결, 경쟁 프로그래밍, 소프트웨어 엔지니어링 자동화와 같은 영역에서 이 모델의 활용 가능성은 더욱 확대될 것으로 기대됩니다. 단순 응답을 넘어, 논리적 사고와 단계적 추론이 중요한 작업이라면 주목할 만한 선택지라 할 수 있습니다.
'인공지능' 카테고리의 다른 글
| FunctionGemma: 엣지 환경을 위한 함수 호출 특화 경량 AI 모델 정리 (0) | 2025.12.19 |
|---|---|
| 스마트폰에서 LLM을 직접 실행하는 방법: ExecuTorch 기반 iOS·Android 온디바이스 배포 가이드 (0) | 2025.12.18 |
| Gemini 3 Flash 기술 개념과 특장점 정리: 속도와 지능을 동시에 잡은 차세대 AI 모델 (0) | 2025.12.18 |
| Agentic AI 시대의 핵심 기준, Agent Quality 완전 정리 - 자율형 AI를 신뢰할 수 있는 시스템으로 만드는 방법 (0) | 2025.12.18 |
| AI의 과학적 추론 능력을 평가하는 새로운 기준, FrontierScience 벤치마크 (0) | 2025.12.17 |



