AI 모델이 더 많은 데이터를 다루고 더 복잡한 문맥을 이해해야 하는 시대가 되면서, 기존 Transformer 구조만으로는 한계가 분명해지고 있다. 특히 긴 문맥을 처리할 때 계산 비용이 급증하고, 실시간으로 새로운 정보를 기억에 반영하지 못한다는 문제가 크다. 이번 글에서는 이러한 한계를 극복하기 위해 제시된 Google의 Titans 아키텍처와 MIRAS 프레임워크를 소개한다. 두 기술은 장기 기억을 효율적으로 형성하고, 실행 중에도 새로운 정보를 자연스럽게 통합하며, 긴 문맥을 빠르고 안정적으로 처리하도록 설계되었다.
이 글을 통해 Titans와 MIRAS가 무엇인지, 기존 모델과 어떤 차이가 있는지, 실제 실험에서 어떤 성능을 보였는지를 쉽게 정리해본다.
Titans와 MIRAS가 필요한 이유: 긴 문맥의 문제
Transformer 기반 모델은 강력한 표현력 덕분에 다양한 분야에서 뛰어난 성능을 보였지만, 시퀀스 길이가 길어질수록 주의(attention) 계산 비용이 급격히 증가하는 구조적 한계를 갖고 있다. 특히 100만 토큰이 넘는 대규모 문맥을 처리할 때는 계산량과 메모리 비용이 폭증해 실사용이 어려워진다.
Titans와 MIRAS는 이러한 문제를 해결하기 위해 등장한 구조로, 긴 문맥을 효율적으로 처리하고 실행 중 기억을 갱신하는 완전히 새로운 방향의 접근법이다.
핵심은 "순환 신경망(RNN)의 효율성"과 "Transformer의 표현력"을 동시에 활용해 장기 문맥 AI 모델의 새로운 기반을 마련하는 것이다.
Titans 아키텍처: 실시간 장기 기억 학습
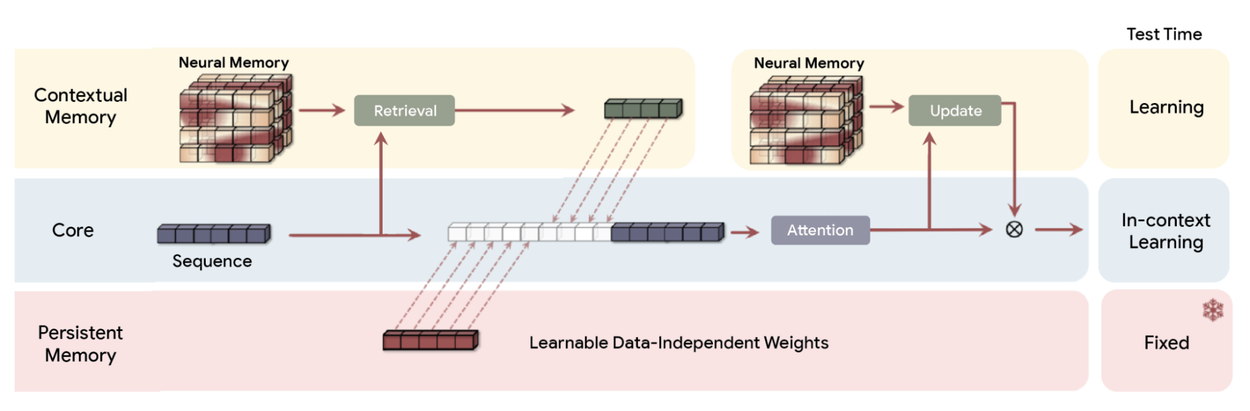
Titans는 단기 기억과 장기 기억을 분리하는 방식을 사용한다. 단기 기억은 기존 Transformer의 주의 메커니즘처럼 현재 입력을 빠르게 처리하고, 장기 기억은 신경망 기반 모듈을 통해 중요한 정보만 선택적으로 저장한다.
장기 기억 구조의 핵심 포인트
- 장기 기억 모듈은 단순 벡터가 아닌 다층 퍼셉트론(MLP) 구조를 사용한다.
- 이 구조 덕분에 훨씬 풍부한 정보 요약이 가능하며, 고정된 벡터 메모리보다 표현력이 크다.
놀라움 지표(surprise metric)
Titans의 핵심 개념은 입력이 기존 기억에서 얼마나 벗어나는지를 측정하는 놀라움 지표다.
- 예측 가능한 입력은 놀라움이 낮아 저장하지 않는다.
- 예상 밖의 입력은 놀라움이 높아 장기 기억에 통합된다.
예를 들어 일반적인 문맥에서 cat이라는 단어가 등장하면 놀라움은 낮다. 반면 갑작스러운 banana peel 같은 비정형 입력은 놀라움이 높아 장기 기억에 기록된다.
모멘텀과 망각
Titans는 장기 기억을 효과적으로 유지하기 위해 모멘텀과 망각을 함께 사용한다.
- 모멘텀은 연속된 문맥 내에서 관련된 정보가 함께 저장되도록 도와준다.
- 망각은 오래된 정보 혹은 비필요한 정보를 자연스럽게 제거해 메모리를 효율적으로 유지한다.
이를 통해 Titans는 실행 중 새로운 지식을 자연스럽게 축적하면서도 불필요한 정보를 최소화하는 구조를 갖는다.
MIRAS 프레임워크: 시퀀스 모델을 통합적으로 보는 새로운 관점
Titans가 구체적인 모델 구조라면, MIRAS는 이를 포함한 다양한 시퀀스 모델을 하나의 틀에서 해석할 수 있도록 만든 이론적 설계도다.
MIRAS는 기존 RNN, Transformer, Mamba 등 다양한 구조를 모두 “연상 기억 시스템”으로 바라본다.
MIRAS의 네 가지 설계 요소
MIRAS는 모든 시퀀스 모델을 다음 네 가지 구성 요소로 설명한다.
- 메모리 구조
정보가 어떤 형태로 저장되는가
예: 벡터, 행렬, MLP 기반 구조 등 - 주의 편향
어떤 정보를 우선순위로 간주하는가 - 보존 게이트(retention gate)
망각을 어떻게 조절하고 기억을 유지하는가 - 메모리 알고리듬
저장된 메모리를 어떻게 갱신하고 최적화하는가
MIRAS가 제시한 이 관점은 기존 Transformer가 가진 평균제곱오차(MSE) 중심의 설계 한계를 넘어, 비유클리드적 목적함수나 일반화된 정규화 방식 등 새로운 모델 설계 가능성을 열어준다.
MIRAS 기반 파생 모델: YAAD, MONETA, MEMORA
MIRAS는 단순한 이론이 아니라 실제 모델 설계까지 이어졌다.
다음 세 모델은 MIRAS 기반 개념을 확장해 만들어진 구조다.
YAAD
- Huber loss를 사용하여 이상치나 노이즈에 덜 민감하게 동작한다.
MONETA
- 일반화된 노름(generalized norms)을 적용해 장기 기억을 안정적으로 유지한다.
MEMORA
- 메모리를 일종의 확률 지도처럼 취급해 정보 통합이 균형 있게 이뤄지도록 설계됐다.
세 모델 모두 주의(attention) 없이도 강력한 장기 기억 성능을 보인다는 점에서 주목받고 있다.
성능 및 실험 결과 분석
Titans와 MIRAS 기반 모델은 기존 최신 모델들과 다양하게 비교 테스트가 진행되었다.
주요 실험 결과
- Transformer++, Mamba-2, Gated DeltaNet보다 높은 정확도와 낮은 perplexity
- C4, WikiText 같은 대규모 언어 모델링에서 우수한 성능
- HellaSwag, PIQA 같은 제로샷 추론에서도 높은 일반화 성능
- DNA 모델링, 시계열 예측에서도 성능 입증
기억 깊이의 중요성
동일한 메모리 용량이라도 깊은 MLP 구조의 메모리가 더 낮은 perplexity와 확장성을 보여주었다.
즉, 단순한 메모리 크기보다 “메모리의 깊이”가 성능을 좌우한다는 점이 확인되었다.
효율성 측면
- Titans는 병렬 학습과 선형 추론 속도를 유지하면서 기존 Transformer 기반 모델보다 빠른 처리 속도를 보였다.
- BABILong 벤치마크에서는 GPT-4보다 적은 파라미터로도 200만 토큰 이상의 긴 문맥을 효과적으로 처리했다.
이는 Titans와 MIRAS가 실용적 성능과 효율성 측면에서 모두 경쟁력이 있음을 보여준다.
Titans와 MIRAS가 가져올 미래
Titans와 MIRAS는 단순히 새로운 모델 구조를 제시하는 수준이 아니라,
“모델이 실행 중에도 스스로 기억을 갱신하고 장기 문맥을 자연스럽게 유지하는 시대”를 열고 있다.
고정된 크기의 순환 상태라는 기존 RNN 한계를 넘고, 고비용 Transformer 구조의 병목을 해결하며,
실시간 학습이 가능한 새로운 메모리 구조를 제시했다는 점에서 의미가 깊다.
MIRAS는 온라인 최적화, 연상 기억, 모델 아키텍처 설계를 하나의 틀로 통합함으로써 차세대 AI 모델 설계의 기준점이 될 가능성이 크다.
Titans와 MIRAS는 긴 문맥 처리와 실시간 기억 갱신이라는 AI의 근본적인 문제를 해결하기 위해 등장한 새로운 아키텍처다.
RNN의 효율성과 Transformer의 표현력을 결합한 구조로, 기존 모델 대비 메모리 효율성, 추론 속도, 장기 문맥 처리 성능에서 뛰어난 결과를 보여주고 있다.
앞으로 더욱 복잡하고 방대한 데이터를 다루는 시대가 올수록, Titans와 MIRAS 같은 구조는 AI 모델 설계의 중요한 기준점이 될 것으로 기대된다.
이제 AI 모델은 단순히 입력을 처리하는 수준을 넘어, 인간처럼 중요한 정보를 장기적으로 기억하고 필요할 때 꺼내 쓸 수 있는 방향으로 진화하고 있다.
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
Titans + MIRAS: Helping AI have long-term memory
December 4, 2025 Ali Behrouz, Student Researcher, Meisam Razaviyayn, Staff Researcher, and Vahab Mirrokni, VP and Google Fellow, Google Research
research.google

'인공지능' 카테고리의 다른 글
| One MCP: 여러 MCP 서비스를 한곳에서 관리하는 중앙 관리 플랫폼 (0) | 2025.12.09 |
|---|---|
| n8n 자동화를 정확하고 빠르게 만드는 n8n-skills 소개 (0) | 2025.12.09 |
| CLaRa: RAG의 한계를 넘어서는 연속 벡터 기반 지식 구조 (0) | 2025.12.09 |
| 모든 에이전트 아키텍처의 핵심을 한 번에 정리한다: LangGraph 기반 17가지 AI 에이전트 구조 총정리 (0) | 2025.12.09 |
| Slack에서 바로 코드 업무로 이어지는 흐름, Claude Code 연동 완전 정리 (0) | 2025.12.09 |



