최근 인공지능의 진화 방향은 단순히 텍스트나 이미지를 처리하는 것을 넘어, 세상을 통합적으로 이해하고 예측하는 모델로 나아가고 있습니다.
중국의 BAAI(Beijing Academy of Artificial Intelligence)가 공개한 Emu3.5는 이 흐름을 대표하는 모델입니다.
이 모델은 단순한 ‘멀티모달 AI’가 아니라, 시각과 언어를 함께 학습해 세계 자체를 모델링(World Modeling) 하는 새로운 접근 방식을 제시합니다.
이 글에서는 Emu3.5의 핵심 기술 구조, 주요 특징, 그리고 왜 이 모델이 기존의 GPT나 Gemini를 능가하는지 살펴봅니다.

1. Emu3.5란 무엇인가?
Emu3.5는 BAAI가 개발한 “Native Multimodal” AI 모델로, 텍스트와 이미지를 동시에 이해하고 생성할 수 있는 차세대 멀티모달 아키텍처입니다.
‘Native’라는 표현이 붙은 이유는, 이 모델이 언어와 비전을 별도의 어댑터 없이 하나의 통합 모델로 처리하기 때문입니다.
기존의 멀티모달 모델들은 보통 시각적 입력과 언어적 입력을 각각 다른 모듈에서 처리한 뒤 결합하는 구조를 가졌습니다.
반면 Emu3.5는 이 둘을 하나의 연속된 시퀀스로 다루며, 마치 인간이 장면을 보면서 동시에 언어로 이해하는 방식처럼 작동합니다.
이러한 구조 덕분에 Emu3.5는 단순히 이미지에 대한 설명을 생성하는 수준을 넘어, 세계의 상태 변화와 상호작용을 예측할 수 있습니다.
2. Emu3.5의 핵심 기술 구조
2.1 Unified World Modeling
Emu3.5의 중심 개념은 Unified World Modeling입니다.
이 기술은 모델이 단일한 세계 표현을 바탕으로 다음 상태를 예측하도록 설계되어 있습니다.
즉, 텍스트와 비주얼 정보를 분리하지 않고, 하나의 세계 상태(State) 로 통합하여 다음 프레임, 다음 문장, 다음 행동을 동시에 예측합니다.
이 접근은 단순히 ‘멀티모달 이해’를 넘어서, 세계의 일관성(spatiotemporal consistency) 을 유지하는 데 강점을 보입니다.
예를 들어, 어떤 영상을 학습할 때 모델은 ‘시간적 변화’를 인식하고, 언어 설명과 시각적 움직임을 연결해 더 정교한 세계 예측이 가능합니다.
2.2 End-to-End Pretraining
Emu3.5는 End-to-End 학습 구조를 채택합니다.
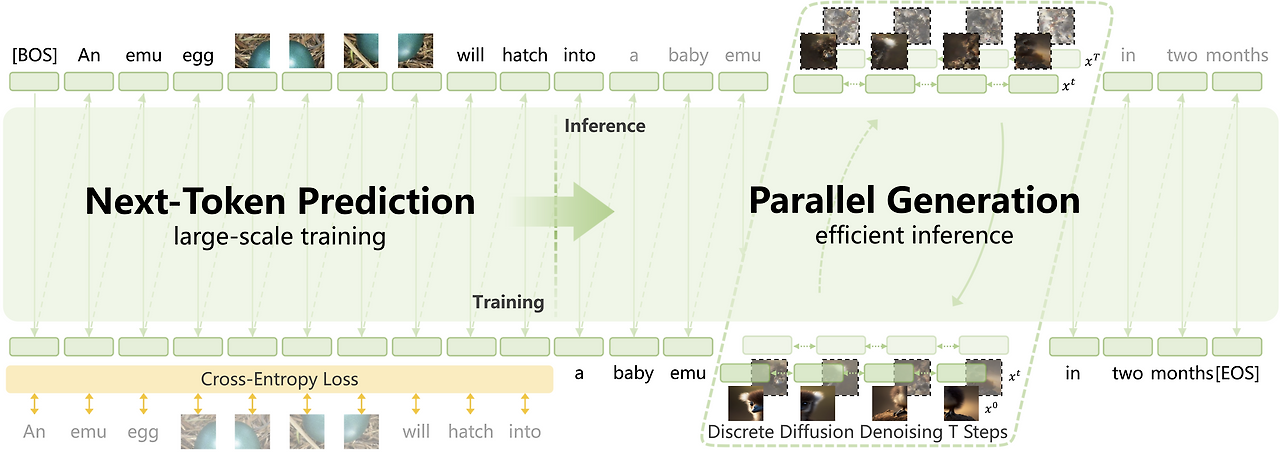
즉, 시각과 언어 데이터를 별도로 처리하지 않고, 하나의 통합된 토큰 시퀀스(interleaved sequence) 로 입력받아 Next Token Prediction 방식으로 학습합니다.
이 학습 과정에서 사용된 데이터 규모는 10조 개 이상의 멀티모달 토큰입니다.
영상 프레임, 자막, 텍스트, 시각적 묘사 등이 함께 포함되어 있으며, 이를 통해 Emu3.5는 언어와 비전의 시간적 구조를 깊이 이해합니다.
이 방식은 언어 모델이 문맥을 이해하듯, Emu3.5가 시각적 문맥과 언어적 의미를 동시에 파악하게 만듭니다.
2.3 RL Post-Training (강화학습 기반 후속 학습)
Emu3.5는 대규모 Reinforcement Learning(강화학습) 을 통해 사후 학습(post-training)을 진행합니다.
이를 통해 모델의 추론 능력(reasoning), 구성력(compositionality), 생성 품질(generation quality) 이 향상되었습니다.
즉, 단순히 ‘이미지 생성’이나 ‘텍스트 응답’ 수준을 넘어, 복합적인 시각-언어적 추론을 수행할 수 있습니다.
예를 들어 “이 사진 속 사람은 무엇을 하려는 중인가?”와 같은 문맥적 이해가 가능해집니다.
2.4 Discrete Diffusion Adaptation (DiDA)
Emu3.5의 가장 주목할 만한 기술 중 하나는 DiDA (Discrete Diffusion Adaptation) 입니다.
기존 모델들이 순차적으로 토큰을 생성하는 sequential decoding 방식을 사용한 반면,
Emu3.5는 이를 양방향 병렬 예측(bidirectional parallel prediction) 으로 전환했습니다.
이 결과, 약 20배 빠른 추론 속도를 실현하면서도 성능 저하 없이 결과를 생성할 수 있습니다.
이는 대규모 멀티모달 모델의 병목 문제를 해결한 혁신적 기술로 평가받고 있습니다.
3. Emu3.5의 주요 특징과 장점
- Native Multimodal I/O 구조
Emu3.5는 텍스트와 이미지를 따로 처리하지 않습니다.
하나의 입력 시퀀스로 통합하여 자연스럽게 처리하기 때문에 모달리티 간 경계가 없습니다. - 강력한 세계 모델링 능력
Emu3.5는 단순히 입력을 이해하는 것을 넘어, 세상의 다음 상태를 예측합니다.
이는 로봇 제어나 시뮬레이션 등에서 핵심적인 기능이 될 수 있습니다. - 고속 추론 성능
DiDA 구조 덕분에 기존 모델 대비 최대 20배 빠른 처리 속도를 달성했습니다.
이는 대규모 이미지 생성, 비디오 분석 등에서 실시간 응용 가능성을 높입니다. - 강화학습으로 향상된 추론 품질
RL 기반 학습은 Emu3.5가 더 자연스럽고 논리적인 응답을 생성하도록 돕습니다.
4. Emu3.5 vs Gemini 2.5 / GPT-4o
BAAI는 Emu3.5가 Google의 Gemini 2.5 Flash Image (Nano Banana) 모델과
이미지 생성 및 편집 품질에서 동등한 수준,
그리고 시각-언어 통합 생성(interleaved generation) 에서는 우수한 성능을 보였다고 밝혔습니다.
GPT-4o가 텍스트 중심의 대화형 모델이라면,
Emu3.5는 비주얼과 언어를 동시에 이해하고 생성하는 진정한 멀티모달 통합 모델로 평가됩니다.
5. Emu3.5의 활용 가능성과 응용
Emu3.5는 다음과 같은 분야에 적용 가능성이 높습니다.
- 영상 이해 및 설명 생성:
영상 속 사건을 분석하고, 장면 변화에 따라 텍스트로 설명을 생성할 수 있습니다. - X2I (Any-to-Image) 변환:
텍스트, 음성, 혹은 비디오 등 다양한 입력을 이미지로 변환할 수 있습니다. - 로봇 및 시뮬레이션 제어:
‘세계 모델링’ 기반으로 물리적 환경을 예측하고 조작하는 데 활용될 수 있습니다. - 텍스트 기반 비주얼 스토리텔링:
복잡한 장면이나 스토리를 시각적으로 표현하는 데 최적화되어 있습니다.
이해하는 AI의 시대를 여는 Emu3.5
Emu3.5는 단순히 ‘그림을 그리고 말하는 AI’가 아닙니다.
세상을 이해하고, 그 이해를 바탕으로 새로운 세계를 만들어내는 AI입니다.
‘Unified World Modeling’과 ‘Native Multimodal I/O’를 기반으로,
이 모델은 인공지능이 단편적 인식에서 벗어나 통합적 세계 모델링을 실현한 첫 사례 중 하나로 평가됩니다.
앞으로 Emu3.5와 같은 모델은 영상 이해, 로봇 제어, 실시간 멀티모달 생성 등
AI의 새로운 가능성을 열어갈 핵심 기술로 자리잡을 것입니다.
https://huggingface.co/BAAI/Emu3.5
BAAI/Emu3.5 · Hugging Face
🔹 Core Concept Description 🧠 Unified World Modeling Predicts the next state jointly across vision and language, enabling coherent world modeling and generation. 🧩 End-to-End Pretraining Trained with a unified next-token prediction objective over i
huggingface.co

'인공지능' 카테고리의 다른 글
| Engineering at Anthropic - MCP 코드 실행으로 AI 에이전트의 효율성을 극대화하는 방법 (0) | 2025.11.05 |
|---|---|
| 오픈소스 AI 연구의 새로운 시대: Tongyi DeepResearch 완전 분석 (0) | 2025.11.04 |
| Langrepl: 대화형 LLM 에이전트 개발을 위한 통합 CLI 플랫폼 (0) | 2025.11.04 |
| 복잡한 AI 작업을 단순하게: Sage Multi-Agent Framework로 본 차세대 오케스트레이션의 진화 (0) | 2025.11.04 |
| AI는 왜 여전히 ‘문맥’을 모를까?― Context Engineering 2.0이 여는 에이전트 시대의 문맥 혁명 (0) | 2025.11.04 |



