
오픈소스 AI의 새로운 진화, ‘안전성(reasoning)’까지 오픈되다
AI 기술이 빠르게 발전하면서, 안전성(safety)은 단순한 기능이 아니라 필수 요건이 되었습니다. AI가 생성하는 콘텐츠가 사회적, 윤리적 기준을 벗어나지 않도록 관리하는 것은 이제 모든 플랫폼과 개발자에게 중요한 과제입니다.
하지만 기존의 안전성 관리 방식은 여러 한계를 가지고 있었습니다. 대부분의 안전 분류기(classifier)는 대규모의 학습 데이터를 기반으로 사전에 정의된 정책에 맞춰 ‘안전/비안전’을 분류합니다. 이런 방식은 빠르지만, 정책을 수정하거나 새로운 리스크가 등장할 때마다 모델을 다시 학습시켜야 하는 비효율이 존재합니다.
이 문제를 해결하기 위해 오픈AI가 새로운 접근 방식을 제시했습니다. 바로 gpt-oss-safeguard입니다. 이 모델은 오픈소스 기반으로, 개발자가 직접 작성한 안전 정책을 모델이 ‘이해하고(reason)’ 적용할 수 있도록 설계되었습니다.
gpt-oss-safeguard란 무엇인가?
gpt-oss-safeguard는 오픈AI가 공개한 안전성 분류용 오픈웨이트(reasoning 기반) 모델입니다.
두 가지 버전으로 제공됩니다.
- gpt-oss-safeguard-120b
- gpt-oss-safeguard-20b
두 모델 모두 오픈AI의 gpt-oss 모델을 기반으로 미세 조정(fine-tuning)된 버전이며, Apache 2.0 라이선스로 공개되어 누구나 자유롭게 사용, 수정, 배포할 수 있습니다.
이 모델의 핵심은 ‘정책(Policy)’을 학습 데이터가 아닌 추론 시점(inference time) 에서 직접 입력받는다는 점입니다. 즉, 모델이 정책을 스스로 해석하고 그에 따라 콘텐츠를 분류합니다.
개발자는 정책을 실시간으로 수정할 수 있고, 모델은 그 변화를 즉시 반영합니다.
이 방식은 기존의 ‘고정된 학습 데이터 기반 분류기’와 달리 훨씬 유연하고 투명한 접근을 가능하게 합니다.
기존 안전 분류기(Classifier)와의 차별점
기존의 안전 분류기들은 수천, 수만 개의 라벨링된 데이터셋을 이용해 학습됩니다.
이 모델들은 ‘정책’을 직접 인식하지 않고, 단지 안전한 콘텐츠와 그렇지 않은 콘텐츠의 예시를 통해 간접적으로 규칙을 학습합니다.
따라서 정책이 바뀌면 다시 데이터를 모으고 재학습해야 했습니다.
반면, gpt-oss-safeguard는 정책 자체를 입력값으로 받습니다.
모델은 정책의 문장을 해석하고, 콘텐츠가 그 정책에 얼마나 부합하는지를 추론(reasoning)을 통해 판단합니다.
이로써 다음과 같은 차별점이 생깁니다.
- 정책 수정 즉시 반영
모델 재학습이 필요 없으며, 정책 문장을 바꾸는 것만으로 안전 기준을 바꿀 수 있습니다. - 추론 기반의 판단 근거 제공
모델은 단순히 “안전/비안전”이라고 답하지 않고, 그 결론에 이르는 추론 과정을 제공합니다.
개발자는 이 reasoning 결과를 검토해 모델의 판단 근거를 이해할 수 있습니다. - 다양한 도메인에 유연하게 대응
예를 들어, 게임 커뮤니티에서는 ‘치팅 관련 게시물’을 분류하고, 리뷰 사이트에서는 ‘가짜 리뷰’를 탐지하는 등, 서로 다른 정책을 적용할 수 있습니다.
작동 원리: 정책 기반 Reasoning 구조
gpt-oss-safeguard의 구조는 간단하지만 강력합니다.
모델은 두 개의 입력을 동시에 받습니다.
- 정책(Policy) – 개발자가 작성한 규칙이나 기준
- 콘텐츠(Content) – 분류 대상이 되는 텍스트
모델은 이 두 정보를 함께 해석한 뒤, 다음과 같은 출력을 제공합니다.
- 콘텐츠가 해당 정책에 위배되는지 여부
- 판단의 근거(reasoning trace)
또한, 모델은 반복적 정책 개선을 지원합니다.
‘policy iteration’ 구조를 통해, 개발자가 모델의 reasoning 출력을 검토하고 정책 문장을 수정하며 성능을 점진적으로 높일 수 있습니다.
이러한 구조는 빠르게 변화하는 리스크 환경(예: 새로운 악용 패턴 등장)에 특히 유리합니다.
실제 활용 예시
- 게임 커뮤니티
특정 키워드나 행동(예: 게임 치트 공유, 부정 행위 토론 등)을 탐지하는 정책을 직접 설정할 수 있습니다.
gpt-oss-safeguard는 해당 정책을 해석하고, 관련 게시물을 자동 분류합니다. - 리뷰 플랫폼
‘가짜 리뷰’나 ‘비속어 포함 리뷰’를 탐지하는 자체 기준을 만들어 적용할 수 있습니다.
새로운 규칙이 필요할 때마다 모델을 재학습할 필요 없이, 정책 문장만 수정하면 됩니다. - AI 윤리 필터링 시스템
도메인별 민감도(예: 생명공학, 자해, 폭력 등)에 맞게 맞춤형 정책을 적용할 수 있습니다.
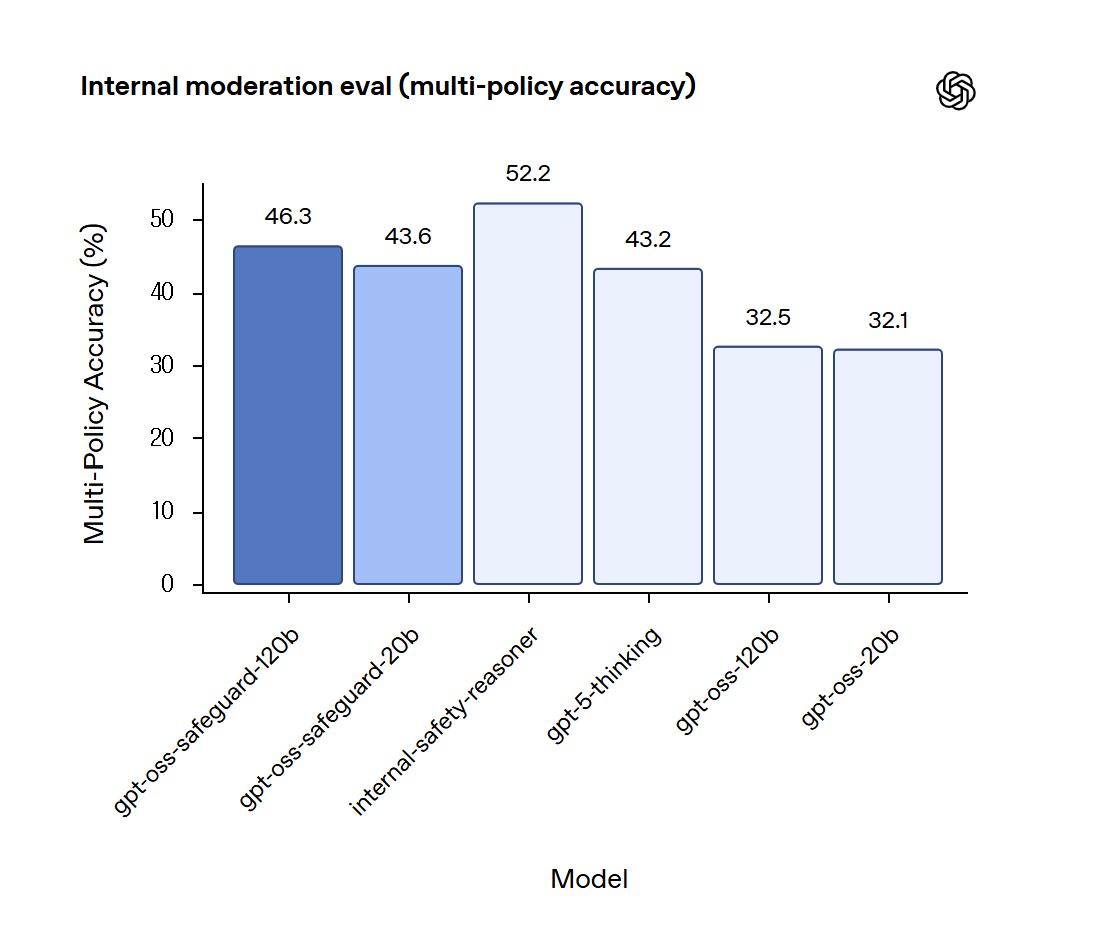
성능 평가: 내부 테스트 결과
오픈AI는 내부 및 외부 벤치마크를 통해 gpt-oss-safeguard의 성능을 검증했습니다.
- 멀티 정책 정확도(Multi-Policy Accuracy)
- gpt-oss-safeguard-120b: 46.3%
- gpt-oss-safeguard-20b: 43.6%
- gpt-5-thinking: 43.2%
- 기존 gpt-oss-120b: 32.5%
- F1 Score (OpenAI Moderation Dataset 기준)
- gpt-oss-safeguard-120b: 82.9
- gpt-oss-safeguard-20b: 82.9
- gpt-5-thinking: 79.8
- 기존 gpt-oss-120b: 80.4
이 결과는 reasoning 기반 접근 방식이 단순 분류기를 대체할 수 있음을 보여줍니다.
한계와 고려 사항
gpt-oss-safeguard에도 몇 가지 명확한 한계가 존재합니다.
- 고성능 전용 분류기보다 정확도가 낮을 수 있음
수만 개의 고품질 라벨 데이터를 이용해 학습된 전통적 분류기는 특정 도메인에서는 여전히 더 높은 정확도를 보일 수 있습니다. - 추론 과정의 연산 비용
reasoning 기반 모델은 추론 과정이 복잡하기 때문에, 대규모 콘텐츠를 실시간으로 처리하기에는 부담이 될 수 있습니다.
오픈AI는 내부적으로 이를 해결하기 위해 소형 분류기를 전처리용으로 두고, 주요 콘텐츠만 reasoning 모델로 분석하는 방식을 사용합니다.
오픈 커뮤니티와 협업의 확장
이번 공개는 단순히 모델을 배포하는 데 그치지 않습니다.
오픈AI는 ROOST, SafetyKit, Discord 등 여러 기관과 협력하여, 안전성 모델의 공동 연구와 개발을 위한 ROOST Model Community(RMC) 를 설립했습니다.
이 커뮤니티는 오픈소스 AI 모델의 안전성 평가, 정책 설계, 모범 사례 공유를 위한 장으로 활용될 예정입니다.
개발자와 연구자는 RMC GitHub를 통해 모델을 실험하고, 피드백을 제공하며, 함께 발전시킬 수 있습니다.
정책 중심 AI 안전성의 새로운 시작
gpt-oss-safeguard는 오픈AI의 ‘안전성(reasoning)’ 연구를 오픈소스 영역으로 확장한 첫 시도입니다.
이 모델은 개발자가 직접 정책을 정의하고, 모델의 판단 근거를 이해하며, 즉시 조정 가능한 안전성 관리 체계를 구축할 수 있도록 합니다.
이는 AI 안전성 관리가 더 이상 폐쇄된 시스템의 영역이 아니라, 개발자 중심의 개방적 생태계로 진화하고 있음을 의미합니다.
앞으로 이 모델은 오픈소스 AI 생태계 전반에서 ‘정책 기반 안전성(reasoning-based safety)’이라는 새로운 표준을 만들어갈 것으로 기대됩니다.
https://openai.com/index/introducing-gpt-oss-safeguard/

'인공지능' 카테고리의 다른 글
| 오픈AI의 미래 전략 완전 정리: AI 클라우드, 초지능, 그리고 2028년 완전 자동화 연구원 비전 (0) | 2025.10.30 |
|---|---|
| 코드로 생각하는 AI, Hugging Face의 smolagents 완전 해부 (0) | 2025.10.30 |
| Spring AI Agents: Java 개발자를 위한 실무형 AI 에이전트 통합 프레임워크 (0) | 2025.10.30 |
| Cursor 2.0과 Composer: 개발 효율을 재정의하는 AI 코딩 혁신 (0) | 2025.10.30 |
| $3로 시작하는 인공지능 코딩 혁신 – GLM 4.6 Coding Plan 완전 정복 (0) | 2025.10.29 |



