AI 에이전트는 이제 단순히 대화를 잘하는 것을 넘어서, 실제 세계의 다양한 도구와 상호작용하며 복잡한 문제를 해결하는 단계에 들어섰습니다. 이를 가능하게 하는 핵심 기술이 바로 MCP(Model Context Protocol) 입니다. MCP는 표준화된 방식으로 다양한 도구를 연결하고, 에이전트가 이를 활용해 작업을 수행하도록 돕습니다.
하지만 지금까지의 평가 방식에는 뚜렷한 한계가 있었습니다. 대부분 단일 호출이나 합성된 환경(mock DB)에 치우쳐 있어 현실 세계의 복잡성과 변동성을 충분히 반영하지 못한 것입니다. 이 때문에 연구자와 개발자들은 “에이전트가 실제 환경에서 제대로 작동하는지”를 검증할 수 있는 표준화된 벤치마크의 필요성을 꾸준히 제기해왔습니다.
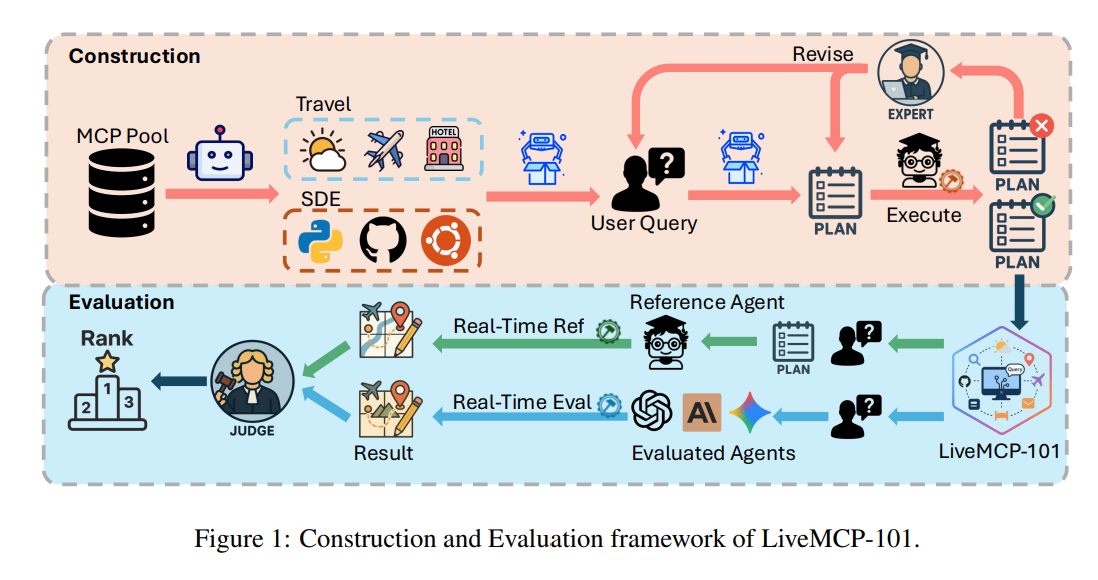
이러한 문제의식 속에서 등장한 것이 바로 LiveMCP-101입니다. LiveMCP-101은 총 101개의 실제 환경 기반 쿼리를 활용해, AI 에이전트가 얼마나 신뢰성 있게 도구를 조합하고 실행할 수 있는지를 평가합니다.
MCP와 기존 평가 방식의 한계
MCP는 다양한 도구를 AI 에이전트와 연결할 수 있도록 설계된 강력한 프레임워크입니다. 그러나 이를 활용한 기존 평가 방식에는 세 가지 뚜렷한 한계가 있었습니다.
첫째, 단일 호출 중심 평가에 머물렀습니다. 현실의 문제는 단 한 번의 호출로 해결되지 않으며, 여러 도구를 연속적으로 사용해야 하는 경우가 많습니다.
둘째, 제한된 도구만 사용하도록 설계되어 있었습니다. 실제 환경에서는 웹 검색, 파일 조작, 데이터 분석 등 다양한 작업이 동시에 요구되지만 기존 테스트는 이런 다양성을 반영하지 못했습니다.
셋째, 합성된 환경(mock DB)에 의존했습니다. 이 때문에 평가가 실제 세계의 변화를 반영하지 못했고, 결과적으로 에이전트가 실제 환경에서 겪을 수 있는 난관을 드러내지 못했습니다.
LiveMCP-101의 제안 배경과 목표
LiveMCP-101은 위와 같은 한계를 극복하고자 설계된 벤치마크입니다. 연구진은 다음과 같은 목표를 세웠습니다.
- 현실성 반영: 단순한 합성 환경이 아니라 실제 환경에서 발생할 수 있는 쿼리를 기반으로 테스트.
- 다단계 문제 해결 능력 평가: 여러 MCP 도구를 순차적으로 조합해야만 풀 수 있는 문제 설계.
- 실행 과정 중심 검증: 결과값만 보는 것이 아니라, 에이전트가 문제를 풀어가는 과정 자체를 평가.
이러한 접근은 단순히 성공 여부를 넘어, 에이전트가 왜 실패했는지, 어디에서 비효율이 발생했는지를 진단할 수 있도록 만듭니다.
LiveMCP-101의 구성과 특징
LiveMCP-101은 총 101개의 실세계 기반 쿼리로 구성되어 있으며, 난이도와 다양성을 동시에 고려했습니다.
- 난이도는 쉬움 30개, 보통 30개, 어려움 41개로 분류됩니다.
- 쿼리는 웹 검색, 파일 조작, 수치 계산, 통계 분석 등 다양한 작업을 포함합니다.
- 각 문제는 단일 도구로는 해결할 수 없으며, 평균 5.4단계, 최장 15단계의 도구 호출 체인을 요구합니다.
문제의 설계 과정 또한 주목할 만합니다. LLM을 활용한 반복적 재작성과 전문가의 수기 검토가 결합되어, 난이도와 실용성을 동시에 확보했습니다. 총 41개의 MCP 서버와 260여 개의 도구가 활용되었으며, 이를 통해 다양한 도메인을 반영할 수 있었습니다.
또한 기존 평가 방식처럼 고정된 정답 값을 제공하는 대신, 실행 계획(ground-truth execution plan) 을 제시했습니다. 이는 단순히 결과가 맞는지 틀린지만 보는 것이 아니라, 문제 해결 과정이 합리적이고 타당했는지를 검증할 수 있게 합니다. 실행 계획을 만드는 데만 약 120시간 이상의 박사급 연구 인력이 투입되었다는 점은 이 벤치마크의 신뢰성을 보여줍니다.
실험 결과와 분석
LiveMCP-101을 활용한 실험에서 최신 LLM조차 성공률 60% 미만을 기록했습니다. 이는 현재의 AI 에이전트가 아직 현실적인 문제 해결 능력에서 한계가 있다는 점을 분명히 보여줍니다.
분석 결과 드러난 주요 문제점은 다음과 같습니다.
- 불필요한 도구 호출로 인한 비효율성
- 실행 과정에서 발생하는 오류
- 토큰 사용 과정에서 드러나는 실패 모드
하지만 이러한 결과는 단순히 부정적인 의미만 담고 있지 않습니다. 오히려 어떤 지점에서 모델이 실패하는지 명확히 드러냈다는 점에서 큰 의의가 있습니다. 이는 곧 연구자와 개발자가 모델을 개선하는 데 필요한 구체적 단서를 제공합니다.
LiveMCP-101의 의의와 기대 효과
LiveMCP-101은 단순히 새로운 벤치마크 이상의 의미를 가집니다.
첫째, 현실성 있는 테스트 환경을 제공합니다. API 결과가 시시각각 달라지는 실제 환경을 반영하여, 에이전트의 적응력과 신뢰성을 검증할 수 있습니다.
둘째, 표준화된 비교 기준을 마련합니다. 이제 연구자들은 LiveMCP-101을 기반으로 다양한 에이전트의 성능을 공정하게 비교할 수 있습니다.
셋째, 미래 발전의 이정표를 제시합니다. 자율적으로 도구를 활용하는 AI 시스템은 앞으로 더 많은 분야에서 활용될 것입니다. LiveMCP-101은 이 시스템들이 현실적인 문제를 얼마나 안정적으로 풀 수 있는지를 평가하는 기준이 될 수 있습니다.
LiveMCP-101은 단순한 성능 평가 도구가 아니라, AI 에이전트의 현실 적합성을 검증하는 새로운 표준입니다.
비록 현재 모델들의 성공률은 60% 미만에 불과하지만, 이는 앞으로의 발전 가능성을 보여주는 출발점입니다. LiveMCP-101은 AI 에이전트가 언제 실패하는지, 왜 비효율이 발생하는지를 구체적으로 드러내어 개선 방향을 제시합니다.
앞으로 LiveMCP-101은 자율 AI의 신뢰성과 안정성을 높이는 데 핵심적인 역할을 하게 될 것입니다. 이 벤치마크가 제시하는 새로운 기준은 연구자와 개발자 모두에게 중요한 참고점이 될 것이며, 더 나은 AI 시스템으로 나아가는 과정에서 큰 의미를 가질 것입니다.
LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries
Tool calling has emerged as a critical capability for AI agents to interact with the real world and solve complex tasks. While the Model Context Protocol (MCP) provides a powerful standardized framework for tool integration, there is a significant gap in b
arxiv.org

'인공지능' 카테고리의 다른 글
| 에이전트의 성능을 극대화하는 도구 설계법: MCP 기반 최적화 전략 (0) | 2025.09.14 |
|---|---|
| 구글 AI 엣지 갤러리: 오프라인에서 즐기는 생성형 AI의 새로운 가능성 (0) | 2025.09.13 |
| ART: 에이전트 강화를 위한 새로운 트레이너 – OpenPipe의 혁신적인 RL 프레임워크 (0) | 2025.09.13 |
| 초거대 언어 모델의 새로운 도약: Qwen3-Next 완벽 분석 (0) | 2025.09.12 |
| Replit Agent 3: AI와 함께하는 개발의 새로운 시대 (0) | 2025.09.12 |



