
dbt(Data Build Tool)는 데이터 트랜스포메이션을 관리하고 자동화하는 오픈 소스 툴입니다. dbt는 데이터 팀이 SQL로 데이터를 변환, 모델링, 테스트 및 문서화할 수 있도록 도와줍니다. 주로 ELT(Extract, Load, Transform) 방식에서 트랜스포메이션(T) 부분을 담당합니다.
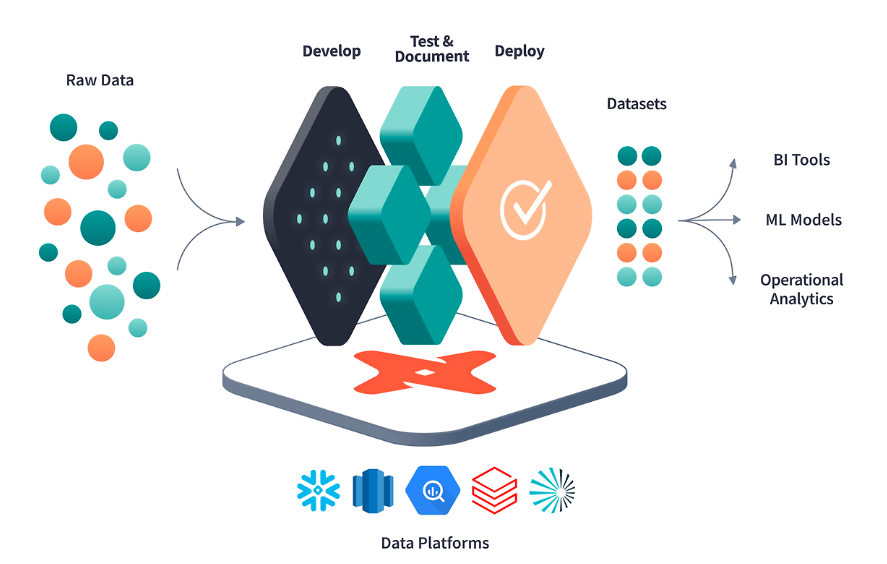
dbt의 주요 특징
- SQL 중심의 트랜스포메이션:
- dbt는 SQL을 사용하여 데이터 트랜스포메이션을 수행합니다. 이는 SQL을 이미 알고 있는 데이터 분석가와 엔지니어에게 매우 친숙한 환경을 제공합니다.
- 버전 관리 및 협업:
- dbt프로젝트는 Git과 같은 버전 관리 시스템과 통합되어 코드 변경 사항을 추적하고 여러 팀원이 협업할 수 있습니다.
- 테스트 및 검증:
- dbt는 데이터 품질을 유지하기 위한 테스트 기능을 제공합니다. 사용자는 모델링된 데이터에 대해 다양한 테스트를 작성하고 실행할 수 있습니다.
- 자동 문서화:
- dbt는 모델과 변환 프로세스를 자동으로 문서화합니다. 이는 데이터 파이프라인에 대한 가시성을 높이고 유지보수를 용이하게 합니다.
- 변환 의존성 관리:
- dbt는 데이터 트랜스포메이션 작업 간의 의존성을 관리합니다. 이는 효율적인 실행 순서를 보장하고 데이터 파이프라인의 신뢰성을 높입니다.
- 유연한 환경 설정:
- dbt는 다양한 환경(dev, staging, prod)에 맞게 구성할 수 있으며, 이를 통해 개발 및 배포 프로세스를 원활하게 관리할 수 있습니다.
dbt의 장점
- 사용자 친화적:
- dbt는 SQL을 중심으로 작동하기 때문에 데이터 분석가와 엔지니어가 쉽게 학습하고 사용할 수 있습니다. 별도의 프로그래밍 언어를 배우지 않아도 됩니다.
- 강력한 커뮤니티와 생태계:
- dbt는 오픈 소스 프로젝트로서 강력한 커뮤니티 지원을 받고 있으며, 다양한 플러그인과 확장 기능을 제공합니다.
- 데이터 품질 보장:
- 자동화된 테스트와 검증 기능을 통해 데이터 품질을 보장할 수 있습니다. 이는 데이터 신뢰성을 높이고 데이터 오류를 사전에 방지합니다.
- 효율적인 데이터 파이프라인 관리:
- dbt는 데이터 트랜스포메이션 간의 의존성을 관리하여 효율적인 데이터 파이프라인을 구축할 수 있습니다. 이는 파이프라인의 유지보수를 쉽게 하고 문제 해결을 용이하게 합니다.
- 비용 절감:
- 클라우드 데이터 웨어하우스와 통합하여 비용 효율적인 데이터 트랜스포메이션을 가능하게 합니다. 예를 들어,dbt는 데이터 웨어하우스의 컴퓨팅 리소스를 활용하여 별도의 인프라 비용을 줄일 수 있습니다.
dbt의 주요 개념인 Materialization이란 무엇인가?
dbt(Data Build Tool)에서의 Materialization은 데이터 변환 작업이 데이터베이스에 저장되는 방식을 정의하는 개념입니다. 쉽게 말해, Materialization은 dbt가 데이터 모델을 어떻게 구현할지 결정하는 방식입니다. dbt는 다양한 Materialization 옵션을 제공하며, 각 옵션은 특정 요구 사항에 맞게 데이터를 저장하고 관리하는 데 사용됩니다.
주요 Materialization 옵션
- View:
- 설명: View는 데이터베이스에 쿼리 정의를 저장하지만 실제 데이터를 저장하지 않는 논리적 테이블입니다.
- 장점: 데이터 업데이트가 실시간으로 반영되어 항상 최신 상태를 유지합니다.
- 단점: 복잡한 쿼리의 경우 성능 저하가 발생할 수 있습니다.
- 사용 예시: 자주 변하지 않는 소규모 데이터 집합이나 실시간 데이터 조회가 필요한 경우.
- Table:
- 설명: Table은 쿼리 결과를 실제 데이터베이스 테이블에 저장합니다. 이는 데이터를 물리적으로 저장하여 빠르게 조회할 수 있도록 합니다.
- 장점: 조회 성능이 뛰어나고, 복잡한 쿼리도 빠르게 처리할 수 있습니다.
- 단점: 데이터가 변경될 때마다 테이블을 다시 생성해야 하므로 데이터 갱신 비용이 발생합니다.
- 사용 예시: 대용량 데이터 집합이나 자주 조회되는 데이터를 저장할 때.
- Incremental:
- 설명: Incremental은 데이터베이스 테이블에 새로운 데이터만 추가하는 방식입니다. 기존 데이터를 모두 다시 처리하는 대신 새로운 레코드나 변경된 레코드만 추가합니다.
- 장점: 데이터 갱신 비용이 줄어들고, 대용량 데이터 처리에 효율적입니다.
- 단점: 초기 설정이 복잡할 수 있으며, 데이터 일관성을 유지하기 위한 추가 로직이 필요할 수 있습니다.
- 사용 예시: 로그 데이터나 주기적으로 추가되는 데이터를 처리할 때.
- Ephemeral:
- 설명: Ephemeral은 물리적 테이블이나 뷰를 생성하지 않고, 다른 모델에서 참조될 때마다 쿼리를 인라인으로 삽입하는 방식입니다.
- 장점: 중간 결과를 저장하지 않아 저장 공간을 절약할 수 있습니다.
- 단점: 복잡한 쿼리의 경우 성능이 저하될 수 있습니다.
- 사용 예시: 중간 계산이나 임시 데이터를 처리할 때.
Materialization 선택의 중요성
dbt 프로젝트에서 올바른 Materialization 방식을 선택하는 것은 매우 중요합니다. 각 방식은 특정 사용 사례에 맞춰 성능 최적화, 저장 공간 절약, 데이터 일관성 보장 등 다양한 이점을 제공합니다. 다음은 Materialization 선택 시 고려해야 할 몇 가지 요소입니다:
- 성능:
- 조회 빈도가 높은 데이터는 Table로 저장하여 성능을 최적화할 수 있습니다.
- 실시간 데이터 업데이트가 필요한 경우 View를 사용하면 유리합니다.
- 저장 공간:
- Ephemeral은 저장 공간을 절약하는 데 유리하지만, 성능 저하를 감수해야 할 수 있습니다.
- 데이터 갱신 주기:
- 자주 갱신되는 데이터는 Incremental 방식으로 처리하여 갱신 비용을 줄일 수 있습니다.
- 데이터 일관성:
- 중요한 데이터의 경우 Table을 사용하여 데이터 일관성을 유지할 수 있습니다.
dbt의 Materialization 개념은 데이터 트랜스포메이션 작업의 효율성을 극대화하고, 다양한 요구 사항에 맞춰 데이터를 효과적으로 관리할 수 있도록 돕는 중요한 요소입니다. 올바른 Materialization 방식을 선택하면 데이터 파이프라인의 성능과 효율성을 크게 향상시킬 수 있습니다.
'빅데이터' 카테고리의 다른 글
| 빅데이터 분석 기사 실기 시험 정보 정리 및 꿀팁 #1 (0) | 2024.06.17 |
|---|---|
| ETL vs ELT - 데이터 처리 접근 방식 차이점 알아보기 (0) | 2024.06.14 |
| [Airflow] Airflow란 무엇인가? (0) | 2024.06.13 |
| [Flink] Apache Flink란 무엇인가? (0) | 2024.06.10 |
| [Spark] Apache Spark란 무엇인가? (0) | 2024.06.10 |



