
쿠버네티스 환경에서 GPU 자원을 사용하는 워크로드를 운영하다 보면, 실제로는 연산을 거의 하지 않으면서도 GPU를 계속 점유하는 파드를 종종 마주하게 됩니다. 이러한 파드는 클러스터 내 다른 작업이 실행되는 것을 방해하고, 불필요한 비용을 발생시킵니다.
이번 글에서는 Prometheus와 간단한 스크립트를 활용하여 유휴 GPU 파드를 자동으로 탐지하고 안전하게 회수하는 방법을 소개합니다. 또한, 이 접근 방식의 장점과 한계, 그리고 대안적인 방법에 대해서도 살펴보겠습니다.
GPU 유휴 파드 문제의 본질
GPU는 고가의 자원이며, 주로 대규모 연산에 사용됩니다. 하지만 현실적으로는 다음과 같은 상황이 자주 발생합니다.
- 모델 로딩 후 장시간 대기만 하는 파드
- 개발자가 임시로 띄워 두고 방치한 파드
- 짧은 연산 후에도 GPU를 계속 점유하는 파드
이러한 파드가 클러스터에 남아 있으면, GPU를 필요로 하는 다른 작업은 대기 상태에 놓이게 되고 전체적인 리소스 활용률은 급격히 떨어집니다. 따라서 GPU를 사용하지 않는 파드를 자동으로 식별하고 회수하는 메커니즘이 필요합니다.
유휴 상태 정의하기
자동화의 첫 단계는 무엇을 ‘유휴’ 상태로 정의할 것인지 명확히 하는 것입니다. 이번 사례에서는 다음 조건을 모두 충족하는 경우를 유휴 상태로 간주했습니다.
- GPU 코어 사용률(Core Utilization)이 일정 시간 평균 10% 미만
- GPU 메모리 사용량이 500MiB 미만
- 위 조건이 1시간 이상 연속적으로 유지될 경우
이 정의는 비교적 단순하면서도 실제로 불필요하게 GPU를 차지하고 있는 파드를 식별하는 데 충분히 유효했습니다. 다만 절대값 기준이 아닌, 요청된 리소스 대비 사용률과 같은 상대적 기준이 더 일반적인 상황에 적합할 수 있다는 점은 고려할 만합니다.
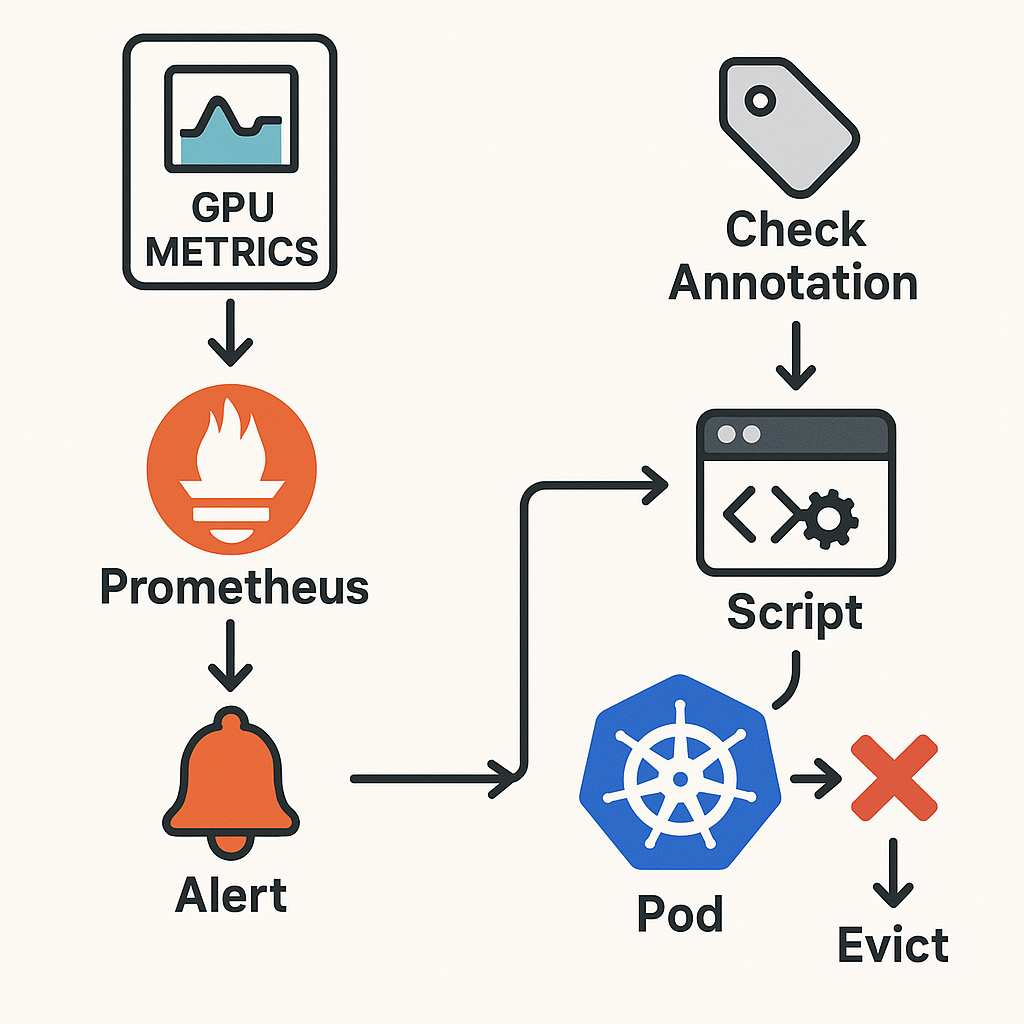
구현 방법: Prometheus와 스크립트 조합
1. GPU 메트릭 수집
파드 단위 GPU 메트릭을 수집하기 위해 HAMi라는 오픈소스 GPU 관리 솔루션을 활용했습니다. HAMi는 Prometheus와 연동되며 다음과 같은 메트릭을 제공합니다.
- vGPU_device_memory_usage_in_bytes: 파드별 GPU 메모리 사용량
- Device_utilization_desc_of_container: 파드별 GPU 코어 사용률
2. PrometheusRule을 통한 유휴 감지
Prometheus의 Alerting Rule을 정의해 특정 파드가 유휴 조건에 부합할 때 경고를 발생시킵니다.
groups:
- name: gpu_idle_alerts
rules:
- alert: LowGPUUsagePodDetected
expr: |
avg_over_time(Device_utilization_desc_of_container[10m]) < 10
and
avg_over_time(vGPU_device_memory_usage_in_bytes[10m]) / 1024 / 1024 < 500
for: 1h
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.podname }} appears to be idle."
이 설정은 유휴 상태를 탐지할 뿐 자동으로 회수하지는 않습니다.
3. 스크립트 기반 회수(Eviction)
주기적으로 실행되는 CronJob 형태의 스크립트를 작성하여 Prometheus Alert를 조회하고 유휴 파드를 회수합니다.
- Prometheus API로 현재 유휴 상태 알람을 조회
- 대상 파드 이름과 네임스페이스 추출
- 어노테이션을 확인하여 특정 파드는 회수 제외
- Eviction API 또는 kubectl delete pod 명령을 이용해 파드 회수
4. 파드 예외 처리
중요하지만 GPU 사용률이 낮은 파드는 어노테이션을 통해 보호할 수 있습니다.
metadata:
annotations:
gpu-eviction-policy: "never"
접근법의 장점
- 기존 도구 활용: Prometheus만 있으면 추가적인 복잡한 설치 불필요
- 단순성: Alert와 스크립트 조합으로 빠르게 적용 가능
- 가시성 확보: Prometheus 경고와 로그를 통해 현황 파악 가능
- 확장성: 필요하다면 Operator 개발로 발전 가능
고려할 점과 대안
현재 접근 방식은 간단하고 효과적이지만 개선할 여지는 있습니다.
- Alertmanager의 Webhook 기능을 활용하여 CronJob 없이 처리할 수 있을까?
- Custom Resource Definition(CRD)을 도입한 전용 Operator 개발이 더 정교한 관리에 적합하지 않을까?
- 단순한 사용률 외에 CUDA API 호출 여부, nvidia-smi 프로세스 상태와 같은 더 정밀한 기준은 어떨까?
- 이미 유사 문제를 해결하는 다른 오픈소스 도구가 존재하지는 않을까?
쿠버네티스에서 GPU 자원은 비싸고 귀중한 리소스입니다. 따라서 유휴 파드를 자동으로 감지하고 회수하는 체계를 구축하면,
- GPU 활용률 극대화
- 비용 절감
- 워크로드 스케줄링 효율 향상
과 같은 효과를 얻을 수 있습니다.
이번 글에서 소개한 Prometheus와 스크립트 기반 방식은 빠르게 적용할 수 있는 실용적인 해법입니다. 다만 환경과 요구사항에 따라 더 정교한 방법이 필요할 수도 있습니다. 앞으로 다양한 아이디어와 경험이 공유된다면, GPU 최적화의 모범 사례를 함께 만들어갈 수 있을 것입니다.
Reclaiming Idle GPUs in Kubernetes: A Practical Approach (and a Call for Ideas!)
Recently, I stumbled upon a Reddit thread asking a question many of us working with GPU-accelerated workloads in Kubernetes have likely…
blog.devops.dev

'DevOps' 카테고리의 다른 글
| 깔끔한 Git 히스토리를 만드는 가장 쉬운 방법: AI 기반 커밋 메시지 자동 재작성 도구 git-rewrite-commits (0) | 2025.11.26 |
|---|---|
| LazyGit – 게으른 개발자를 위한 똑똑한 Git UI (0) | 2025.11.12 |
| Flatpak의 미래 – 성숙기 진입인가, 정체기인가? (0) | 2025.05.24 |
| AI가 코드를 짜줘도 느려지는 개발팀, 해답은 CI/CD에 있다 (0) | 2025.05.18 |
| AgentOps: AI 에이전트의 신뢰성과 효율성을 높이는 통합 운영 도구 (0) | 2025.04.06 |



