LLM의 다음 진화는 어디서 올까?
트랜스포머 기반의 대형언어모델(LLM)이 지금까지 자연어 처리의 중심 기술로 자리잡아왔습니다. 하지만 여러분도 느끼셨을 겁니다. 성능은 더 이상 눈에 띄게 오르지 않고, 한계에 다다른 느낌 말이죠.
이제 메타는 여기서 한발 더 나아가, 확산(diffusion) 모델과 강화학습(RL)을 결합한 새로운 방식을 제안했습니다. 바로 ‘d1 프레임워크’입니다. 기존과는 완전히 다른 작동 원리를 갖고 있는 이 접근법은, 단순한 속도 향상 그 이상을 보여줍니다.
이 글에서는 메타가 발표한 dLLM과 d1 프레임워크를 중심으로, 왜 이 기술이 중요한지, 어떻게 동작하는지, 그리고 향후 어떤 가능성을 품고 있는지 쉽게 설명해드립니다.
🔍 트랜스포머 기반 LLM, 한계에 봉착하다
지금까지 우리가 써온 대부분의 언어모델은 자기회귀(autoregressive) 방식의 트랜스포머였습니다. GPT도, Claude도, 대부분 이 방식을 따릅니다. 이 방식의 핵심은 “이전 토큰을 보고 다음 토큰을 예측하는 것”이죠.
하지만 이 방식엔 분명한 한계가 있습니다:
- 한 번에 한 토큰씩 생성되므로 병렬 처리에 비효율적
- 추론 단계가 길어질수록 속도 저하 발생
- 전체 문맥을 고려하기보단 순차적 예측에 의존
이런 단점을 극복하기 위해 이미지 생성에서 쓰였던 **‘확산 모델’**을 텍스트에도 적용하려는 시도가 이어졌습니다.
🌫️ 확산 모델, 텍스트에 적용하면?
확산 모델은 원래 이미지 생성 분야에서 각광받았습니다. ‘달리(DALL·E)’나 ‘미드저니(Midjourney)’를 보면 알 수 있죠.
이미지를 노이즈로 변환한 후, 이 노이즈를 점차 되돌리는 과정에서 새로운 이미지를 만들어냅니다.
하지만 문제는 텍스트입니다.
이미지는 연속적인 픽셀 값으로 이루어져 있지만, 텍스트는 불연속적인 토큰 단위입니다. 따라서 동일한 방식으로 노이즈를 주입하고 되돌리는 것이 어렵습니다.
🧠 메타의 해법: 마스크 기반 dLLM
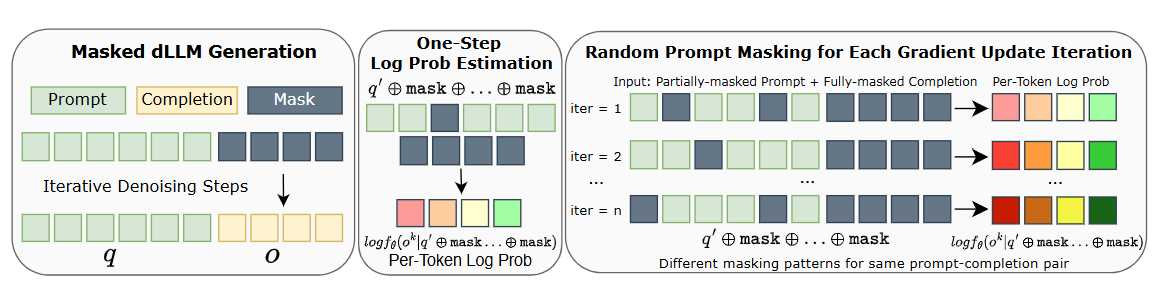
메타와 UCLA 연구팀은 이 문제를 해결하기 위해 **‘마스크된 dLLM(Masked dLLM)’**이라는 접근을 고안했습니다.
여기서 핵심 아이디어는 다음과 같습니다:
- 노이즈 대신 토큰 일부를 무작위로 마스크(mask)
- 모델이 마스크된 부분을 복원하도록 학습
- 이를 통해 점차 텍스트를 정제하는 과정이 확산처럼 작동
즉, 전체 텍스트 시퀀스의 일부가 가려진 상태에서 시작해, 점차 복원하며 일관성 있고 고품질의 문장을 생성하는 방식입니다.
이 구조 덕분에 dLLM은 자기회귀 모델과 달리 모든 문맥을 동시에 고려할 수 있습니다.
🧩 d1 프레임워크: 두 단계의 학습 구조
메타는 이 마스크 기반 dLLM에 ‘d1’이라는 새로운 학습 프레임워크를 적용했습니다. 핵심은 2단계 사후 훈련(Post-training)입니다:
1️⃣ SFT(Supervised Fine-Tuning)
먼저, 사전 학습된 dLLM에 고품질 추론 예시 데이터셋인 ‘s1k’를 통해 지도 미세조정을 합니다.
이 데이터셋은 아래와 같은 구성으로 되어 있습니다:
- 문제 해결의 단계적 풀이 예시
- 자기 수정 및 백트래킹 사례
- 다양한 유형의 추론 문제
이 과정을 통해 모델은 기본적인 추론 전략과 논리적 사고 패턴을 내재화합니다.
2️⃣ RL 강화를 위한 Diffu-GRPO
그다음 단계는 **강화학습(RL)**입니다. 하지만 기존 RL 알고리즘(PPO, GRPO)은 반복적이고 비순차적인 dLLM에는 적용이 까다롭습니다.
이를 해결하기 위해, 연구팀은 Diffu-GRPO라는 새로운 알고리즘을 제안합니다:
- GRPO 원리를 dLLM 구조에 맞게 수정
- 무작위 프롬프트 마스킹 기법 도입 → 데이터 증강 및 정규화
- RL 과정 중 로그 확률 추정 효율 향상
이 과정을 통해 모델은 추론의 정확도와 효율성을 동시에 향상시킬 수 있습니다.
🧪 실험 결과: 기존 모델보다 뛰어난 성능 입증
연구팀은 이 프레임워크를 LLaDA-8B-Instruct라는 dLLM에 적용했습니다. 이후 여러 벤치마크를 통해 성능을 검증했죠.
✅ 테스트 영역:
- GSM8K: 수학 문제 해결
- MATH500: 고난도 수학 추론
- 4×4 스도쿠: 논리 퍼즐
- 카운트다운 넘버 게임: 조합 추론 문제
✅ 결과 요약:
- SFT + Diffu-GRPO 모델이 모든 기준에서 기존 모델을 능가
- 단순 SFT 적용보다도 RL 적용 모델이 월등한 성능
- 속도와 처리량은 유지하면서도 추론 능력 대폭 향상
LLM의 미래를 다시 그리다
기존 트랜스포머 모델은 여전히 강력하지만, 확산 모델과 강화학습을 결합한 d1 프레임워크는 새로운 가능성을 제시합니다.
단순히 빠른 것뿐 아니라, 더 깊이 있는 추론, 더 정밀한 응답 생성이 가능해졌다는 것이 가장 큰 차이점입니다.
특히 다음과 같은 상황에 적합한 솔루션이 될 수 있습니다:
- 워크플로우 자동화가 필요한 기업용 에이전트
- 복잡한 논리 판단이 요구되는 의사결정 시스템
- 빠른 처리와 고정확성이 동시에 요구되는 실시간 AI 애플리케이션

'인공지능' 카테고리의 다른 글
| 샤오미가 AI판을 흔든다?-MiMo-7B 오픈소스 모델, 왜 주목받고 있는가 (0) | 2025.05.01 |
|---|---|
| 메타가 라마 API로 보여준 AI의 미래: 왜 이 발표가 중요한가? (0) | 2025.05.01 |
| "이젠 오디오로 듣는다!" 구글 NotebookLM의 다국어 오디오 개요 기능 전격 소개 (0) | 2025.05.01 |
| "GPT 4.1 vs Gemini vs Sonnet, 무엇을 써야 할까?" - Cursor에서 개발자들이 진짜로 쓰는 모델 비교 리뷰 (0) | 2025.05.01 |
| Meta AI 앱 출시: "당신의 디지털 일상에 AI 비서가 들어왔다" (0) | 2025.04.30 |



