AI 코딩 에이전트가 점점 똑똑해지고 있다는 건 알고 있지만,
"이 에이전트가 진짜로 쓸만한가?" 라는 질문엔 쉽게 답하기 어렵습니다.
그 이유는 간단합니다.
지금까지 AI 에이전트를 평가하던 방식이 너무 좁고, 너무 인공적이었기 때문입니다.
AWS는 이 문제를 정면 돌파하기 위해 SWE-PolyBench라는 새로운 벤치마크를 공개했습니다.
이 벤치마크는 단순한 테스트 스크립트를 넘어서,
실제 깃허브 리포지토리 기반의, 다국어 코드 과제를 포함한 평가 프레임워크입니다.
이 글에서는 SWE-PolyBench가 무엇이고, 기존 벤치마크와 어떤 차별점이 있는지,
그리고 실제로 어떤 인사이트를 주는지 살펴봅니다.
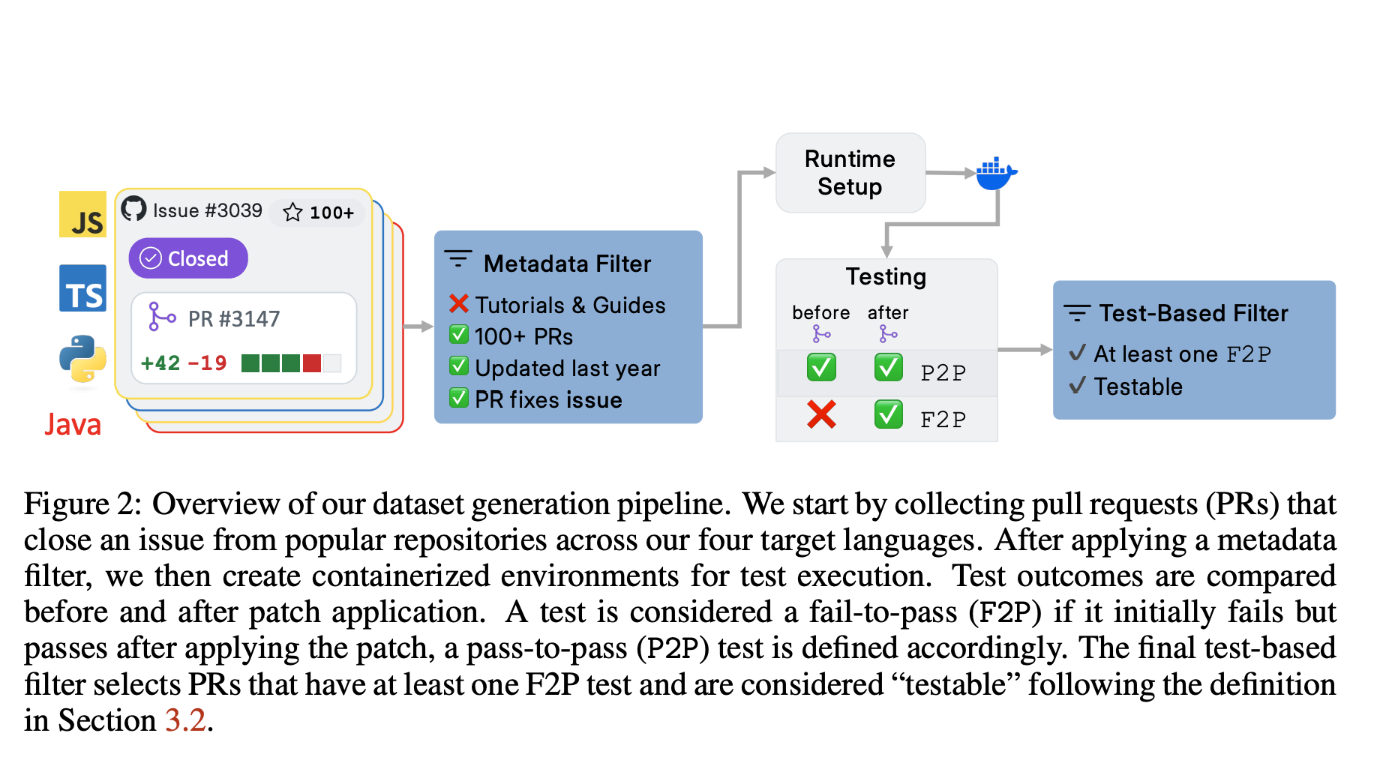
1️⃣ SWE-PolyBench란 무엇인가?
기존 벤치마크의 한계
대부분의 기존 AI 코드 에이전트 벤치마크는 다음과 같은 특징을 갖고 있습니다.
- 파이썬에만 집중
- 작고 인위적인 코드 과제
- 실행 가능한 테스트 없이 정적인 평가
- 실제 개발 상황을 반영하지 못함
결과적으로, AI 모델이 벤치마크용 문제에만 과도하게 적응(overfit) 하게 되고,
실제 개발 환경에서는 성능이 확 떨어지는 일이 발생합니다.
SWE-PolyBench의 등장
AWS AI Labs는 이런 문제를 해결하기 위해
현실적인 코드 과제, 다양한 언어, 실제 깃허브 이슈 기반 과제를 포함한
실행 기반 평가 벤치마크, SWE-PolyBench를 발표했습니다.
2️⃣ SWE-PolyBench의 구성 요소와 특징
✅ 다국어 지원
SWE-PolyBench는 4개의 주요 프로그래밍 언어를 지원합니다.
- Java
- JavaScript
- TypeScript
- Python
각 언어는 실제 오픈소스 깃허브 리포지토리에서 발췌한 과제를 포함하고 있으며,
총 2,110개의 과제가 포함되어 있습니다.
✅ 실제 PR 기반 문제
각 과제는 다음과 같은 방식으로 구성됩니다:
- 실제 깃허브 Issue로부터 문제 정의를 수집
- 그 이슈를 해결한 **Pull Request(Pull Request)**를 실제 정답으로 사용
- 관련된 테스트 케이스도 함께 포함
즉, 인공적으로 만든 코드가 아니라, 현실에서 발생한 실제 문제와 그 해결 과정이 포함된 것입니다.
✅ 빠른 테스트용 ‘SWE-PolyBench500’ 제공
전체 벤치마크 외에도, 더 빠른 테스트를 위한 축소 버전인
SWE-PolyBench500도 함께 제공됩니다.
언어와 과제 유형의 다양성은 그대로 유지되며,
빠른 실험에 적합합니다.
3️⃣ 어떻게 평가하는가? SWE-PolyBench의 평가 방식
🧪 실행 기반 평가
기존의 단순 정적 코드 비교를 넘어서, SWE-PolyBench는 실제 코드를 실행해 평가합니다.
- 각 과제는 문제 설명 + 리포지토리 스냅샷으로 제공
- 에이전트는 그 문제를 해결하는 코드를 생성
- 해당 코드를 실제 리포지토리에 적용하고, 컨테이너 환경에서 테스트 실행
✅ 두 가지 테스트 케이스
- Fail-to-Pass (F2P)
기존 테스트가 실패했는데 → 새 코드가 통과하는지 확인 - Pass-to-Pass (P2P)
기존 테스트가 통과했고 → 새 코드도 계속 통과하는지 확인
→ 기존 기능이 깨지지 않았는지를 확인하는 용도
🧬 문법 기반 정밀 평가 (CST 기반)
- 단순한 성공/실패 외에도, 코드의 구조적인 변화를 정밀하게 측정합니다.
- Concrete Syntax Tree(CST) 분석을 통해 다음 항목을 평가합니다:
- 파일 수준에서 수정이 필요한 위치를 제대로 찾았는가?
- 코드 노드 수준에서 수정이 정확히 되었는가?
이 지표들은 특히 다중 파일 수정, 복잡한 코드 리팩토링에 유용합니다.
4️⃣ 실제 결과: AI 코딩 에이전트의 성능은?
평가 대상 에이전트
- Aider
- SWE-Agent
- Agentless
이들 모두 Anthropic의 Claude 3.5 모델을 기반으로 구성되었으며,
SWE-PolyBench에 맞게 멀티언어, 리포지토리 기반 문제를 처리할 수 있도록 커스터마이징 되었습니다.
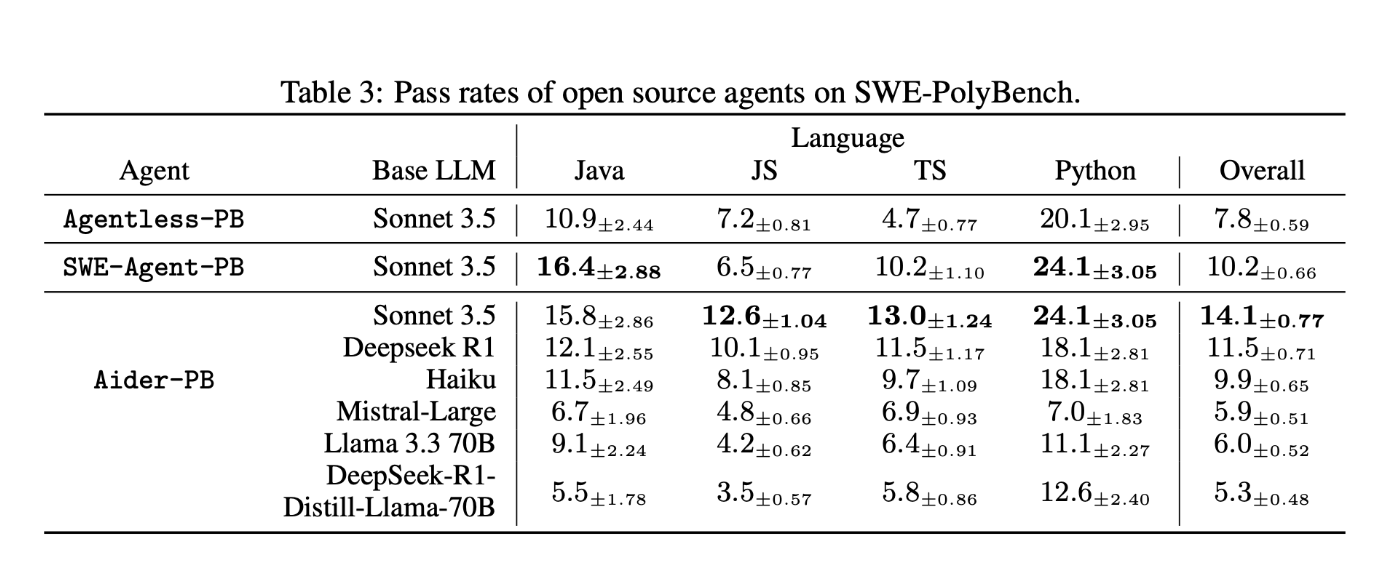
언어별 성능 차이
| 언어 | 최고 성공률 |
| Python | 24.1% |
| Java | ~20% 이상 |
| JavaScript | 낮음 |
| TypeScript | 4.7% |
흥미로운 점은 TypeScript가 Python보다 구문적으로 단순하지만,
성공률은 훨씬 낮았다는 것입니다.
이는 모델의 사전 학습 노출도나 구문 익숙함이 성능에 큰 영향을 준다는 것을 보여줍니다.
과제 난이도에 따른 성능
- 단일 함수 / 클래스 수정 과제: 성공률 최고 40%
- 다중 파일 및 복합 수정 과제: 성공률 급감
즉, 문제를 정확히 ‘어디서’ 수정해야 하는지를 찾는 것은 가능하지만,
‘어떻게’ 해결할지를 정답에 가깝게 구현하는 것은 여전히 어려운 단계입니다.
왜 SWE-PolyBench가 중요한가?
AI 코딩 에이전트는 분명히 가능성이 있습니다.
하지만 지금까지의 벤치마크는 그 가능성을 올바르게 측정하지 못했습니다.
SWE-PolyBench는 다음과 같은 측면에서 차별화됩니다:
- 다국어 지원으로 더 넓은 범위의 평가 가능
- 실제 문제와 PR 기반으로 현실성 높은 과제 제공
- 실행 기반 테스트와 문법 기반 평가로 정밀한 성능 측정
- 다양한 과제 유형으로 진짜 ‘실력’을 가늠할 수 있음
AI 코딩 도구가 현업에 도입되기 위해선,
이런 현실적인 평가 도구가 필수입니다.
SWE-PolyBench는 그 첫걸음을 내디딘 중요한 이정표입니다.
💬 기대되는 점
앞으로 더 많은 벤치마크가 SWE-PolyBench처럼
현실의 문제를 기반으로, 다양한 언어와 평가 기준을 포함하게 된다면,
AI 코딩 에이전트는 단순한 실험용 도구를 넘어서
실제 개발 파트너로서 더 빠르게 자리 잡을 수 있을 것입니다.
개발자라면, 연구자라면, 이제는 SWE-PolyBench를 살펴볼 때입니다.
지금이 바로, 진짜 실력을 가늠할 수 있는 새로운 기준점을 만나볼 시간입니다.
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark for Evaluating AI Coding Agents
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark for Evaluating AI Coding Agents
www.marktechpost.com




