🚀 AI 추론 모델, 지금 무슨 일이 벌어지고 있는가?
딥시크-R1이 등장했을 때만 해도, “이보다 더 나은 오픈소스 모델은 없을 것”이라는 반응이 많았습니다. 그러나 3개월도 채 지나지 않아, 엔비디아가 그 한계를 깼습니다.
**'라마-3.1 네모트론 울트라 253B(Llama-3.1-Nemotron-Ultra-253B)'**는
- 딥시크-R1의 절반 수준의 크기,
- 하지만 오히려 뛰어난 성능,
- 그리고 오픈소스 자유 라이선스를 내세워 기술 시장에 강한 충격을 줬습니다.
이 블로그에서는 이 모델이 왜 주목받고 있는지, 어떤 구조적 혁신을 이뤘는지, 그리고 실제 사용 환경에서 무엇이 가능한지를 차근차근 살펴보겠습니다.

🧠 ‘라마-3.1 네모트론 울트라 253B’란 무엇인가?
이 모델은 엔비디아가 오픈소스로 공개한 고성능 LLM입니다. 이름이 다소 길지만, 핵심은 이렇습니다.
- 라마-3.1 기반: 메타의 Llama-3.1-405B-Instruct를 바탕으로 개발
- 2530억개의 파라미터: 딥시크-R1(6710억개)의 절반 이하
- Dense 모델: 희소 모델이 아닌 밀집 구조로 정확도 유지
- 상업적 사용 가능: 기업도 자유롭게 활용 가능
- 다국어 지원: 영어 외에도 독일어, 프랑스어, 힌디어, 태국어 등 폭넓은 언어 대응
🏗️ 딥시크-R1과의 차별점: 작지만 강한 구조
단순히 “크기만 줄였다”는 게 아닙니다. 엔비디아는 아래와 같은 구조 최적화 기술을 적용했습니다.
1. NAS 기반 설계
**NAS(Neural Architecture Search)**를 활용해 자동화된 최적 구조를 설계. 성능과 효율의 균형을 잡았습니다.
2. 구조적 경량화 기술
- Attention 레이어 생략
- FFN(Feed-Forward Network) 통합 및 압축 조절
→ 이로 인해 연산 비용과 메모리 사용량이 크게 감소했음에도 성능 저하는 거의 없음.
3. Reasoning Toggle 기능 탑재
앤트로픽의 클로드 3.7에서 봤던 것처럼, 간단한 작업에서는 고비용 추론 모듈을 비활성화할 수 있음.
→ 비용을 아끼면서도, 복잡한 작업엔 정확도를 놓치지 않음.
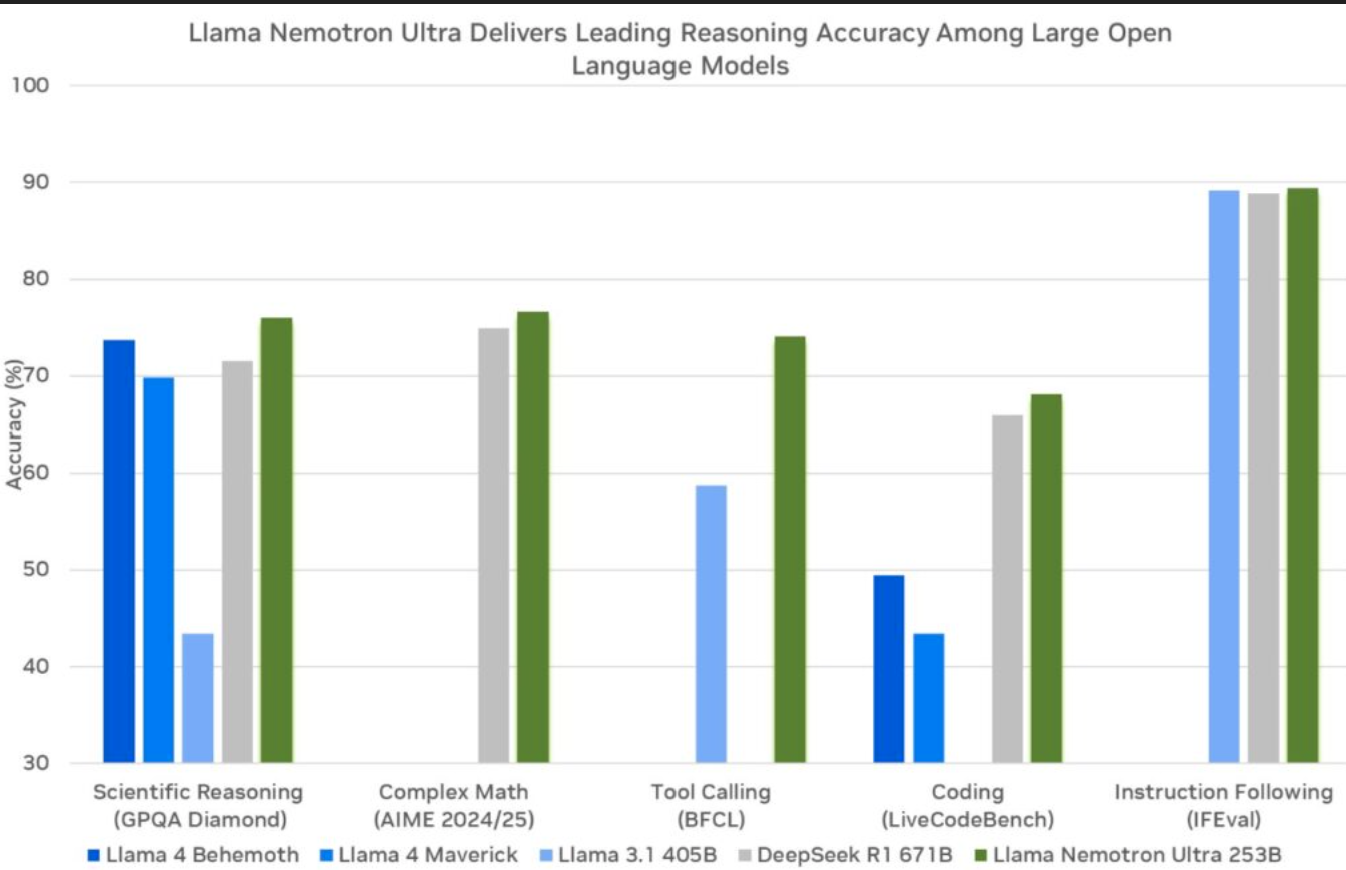
📊 벤치마크로 본 실질 성능
모델이 정말 좋은지 알려면, 결국 숫자로 보여줘야 하죠. 엔비디아는 주요 벤치마크에서 다음과 같은 성능 향상을 입증했습니다.
| 테스트 항목 | 일반 모드 | 정확도 추론 모드 | 정확도 DeepSeek-R1 |
| MATH500 | 80.40% | 97.00% | 97.3% |
| AIME25 | 16.67% | 72.50% | 79.8% |
| LiveCodeBench | 29.03% | 66.31% | - |
| GPQA | - | 76.01% | 71.5% |
🔍 요약하자면:
- 수학에서는 딥시크-R1이 여전히 약간 우위
- 그 외 대부분의 지시 이행, 추론 능력에서 네모트론 울트라가 우위
🛠️ 어디에, 어떻게 쓸 수 있을까?
이 모델은 단순한 챗봇이나 질문응답용을 넘어서, AI 워크플로우 전체를 설계할 수 있는 기반이 됩니다.
✅ 활용 사례
- RAG (검색 기반 생성) 시스템
- AI 코드 생성기
- 대화형 에이전트
- 멀티랭귀지 AI 어시스턴트
- 수학 및 논리 기반 AI 튜터
✅ 사용 환경
- H100 GPU 8개 구성의 단일 서버에서 실행 가능
- 최대 12만 8000 토큰 입력/출력 지원
- HuggingFace에서 바로 다운로드 및 실험 가능
📌 요약하자면:
- 엔비디아는 작은 모델로 더 나은 성능을 실현하며, 오픈소스 시장에 강한 메시지를 전달했습니다.
- 추론 최적화 + 구조 경량화 + RL 기법 접목이라는 세 가지 축을 통해 성능과 비용 효율을 동시에 챙겼습니다.
- 다양한 AI 제품과 서비스에 즉시 적용 가능하다는 점에서 활용 범위가 넓습니다.
https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1#evaluation-results
nvidia/Llama-3_1-Nemotron-Ultra-253B-v1 · Hugging Face
Llama-3.1-Nemotron-Ultra-253B-v1 Model Overview Llama-3.1-Nemotron-Ultra-253B-v1 is a large language model (LLM) which is a derivative of Meta Llama-3.1-405B-Instruct (AKA the reference model). It is a reasoning model that is post trained for reasoning, hu
huggingface.co

'인공지능' 카테고리의 다른 글
| “에이전트가 개발을 대신해준다?” Google Cloud Next ‘25, 개발의 미래를 엿보다 (0) | 2025.04.11 |
|---|---|
| “AI의 판을 다시 짠다” – 구글 클라우드 Next 25에서 공개된 차세대 AI 기술 총정리 (0) | 2025.04.11 |
| 70B가 109B를 이겼다고? 새로운 오픈소스 LLM ‘Cogito’가 주목받는 이유 (0) | 2025.04.11 |
| Vectara의 ‘Open RAG Eval’로 AI 응답 품질, 더 이상 감으로 판단하지 마세요 (0) | 2025.04.11 |
| ❝처음 보는 도구도 쓴다고?❞ LLM을 위한 새로운 프레임워크 ‘도구 사슬(CoTools)’의 등장 (0) | 2025.04.10 |



