
인공지능(AI) 모델의 성능을 최적화하려면, 종종 Fine-Tuning이라는 과정이 필요합니다. Fine-Tuning이란 사전 학습된 모델을 특정한 작업이나 데이터에 맞추어 재조정하는 방법을 말합니다. 예를 들어, GPT-4 같은 대규모 언어 모델을 특정 산업의 언어 데이터를 사용해 더 정밀하게 조정할 때 Fine-Tuning을 활용합니다.
하지만, Fine-Tuning에는 많은 자원(시간, 계산 능력 등)이 필요할 수 있습니다. 이 문제를 해결하기 위해 다양한 기법이 개발되었고, 그 중 하나가 바로 PEFT(Parameter-Efficient Fine-Tuning)입니다.
PEFT: 파라미터 효율적 Fine-Tuning
PEFT는 **파라미터 효율적 Fine-Tuning(Parameter-Efficient Fine-Tuning)**의 약자로, Fine-Tuning 과정에서 필요한 자원을 최소화하면서도 높은 성능을 유지할 수 있는 방법을 제공합니다. PEFT의 주요 목적은, 대규모 모델을 전체적으로 재학습하지 않고도 특정 작업에 맞게 조정하는 것입니다. 이렇게 함으로써, 계산 자원과 시간이 크게 절약됩니다.
LoRA: Low-Rank Adaptation
PEFT 방법 중에서도 LoRA(Low-Rank Adaptation)는 특별히 주목받고 있는 기술입니다. LoRA는 모델의 Low-Rank Adaptation을 통해, 전체 모델 파라미터를 변경하지 않고도 Fine-Tuning을 효과적으로 수행할 수 있도록 합니다.
LoRA의 세부적인 동작 방식
LoRA(Low-Rank Adaptation)는 인공지능 모델의 Fine-Tuning을 효율적으로 수행하기 위해 고안된 기술로, 특히 대규모 언어 모델의 파라미터 수가 많을 때 그 유용성이 크게 부각됩니다. LoRA의 동작 방식은 저차원 행렬(Low-Rank Matrices)을 활용해 모델의 특정 부분을 Fine-Tuning함으로써 계산 자원과 메모리 사용을 크게 줄이는 것입니다. 이제 LoRA가 어떻게 작동하는지 더 깊이 있는 설명을 진행하겠습니다.
기존 Fine-Tuning의 문제점
대규모 언어 모델에서 Fine-Tuning을 수행할 때, 수억에서 수십억 개의 파라미터를 모두 재학습해야 할 수 있습니다. 이는 다음과 같은 문제를 야기합니다:
- 높은 계산 비용: 모든 파라미터를 재학습하는 데 필요한 계산량이 매우 큽니다.
- 많은 메모리 사용량: 모델의 파라미터를 저장하고 업데이트하기 위해 많은 메모리가 필요합니다.
- Overfitting 위험: 특정 작업에 맞추어 전체 파라미터를 재조정하면, 모델이 일반화 능력을 잃고 학습한 데이터에 과적합될 위험이 있습니다.
이러한 문제를 해결하기 위해, LoRA는 파라미터 효율적인 Fine-Tuning을 목표로 합니다.
LoRA의 기본 아이디어: 저차원 근사

LoRA는 기존 모델 파라미터 행렬을 **저차원 근사(Low-Rank Approximation)**하는 아이디어를 바탕으로 합니다. 이 과정은 다음과 같이 진행됩니다:
1.기존 파라미터 행렬의 분해: 대규모 모델의 특정 파라미터 행렬 W를 저차원 행렬 A와 B로 분해합니다. 여기서 A와 B는 원래 행렬보다 훨씬 작은 차원(rank)을 가집니다.

2.저차원 행렬의 학습: Fine-Tuning 과정에서 전체 파라미터 행렬 WW를 재학습하지 않고, AA와 BB만 학습합니다. 이렇게 하면 학습해야 할 파라미터의 수가 크게 줄어들어, 계산 자원과 메모리를 절약할 수 있습니다.
LoRA의 동작 메커니즘
LoRA의 작동 방식은 다음과 같은 단계로 설명할 수 있습니다
1. 파라미터 행렬의 저차원화
LoRA는 특정 파라미터 행렬 W0에 대해 다음과 같은 변환을 수행합니다

여기서 W original은 사전 학습된 원본 모델의 파라미터 행렬이고, ΔW는 Fine-Tuning을 통해 학습된 변화량을 나타냅니다. 이 변화량 ΔW는 다음과 같이 정의됩니다

- : 저차원 공간으로의 매핑 행렬입니다. 차원 축소를 통해 원래 파라미터의 입력 공간을 저차원 공간으로 변환합니다.
- B: 저차원 공간에서 원래 공간으로 다시 확장하는 행렬입니다. A에 의해 축소된 정보를 원래 차원으로 복원하는 역할을 합니다.
이 A와 B 행렬은 기존의 큰 파라미터 행렬보다 훨씬 적은 파라미터 수를 가지며, 이들을 학습함으로써 전체 모델의 파라미터를 조정하지 않고도 Fine-Tuning이 가능해집니다.
2. Fine-Tuning 과정
Fine-Tuning 과정에서, LoRA는 다음과 같이 동작합니다
저차원 매핑: 입력 데이터가 W0에 의해 변환되기 전에, 저차원 행렬 A에 의해 먼저 변환됩니다. 이 과정에서 데이터는 저차원 공간으로 매핑됩니다.
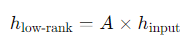
원래 공간으로 복원: 저차원 공간으로 변환된 데이터 h low-rank는 행렬 B에 의해 다시 원래 공간으로 복원됩니다.
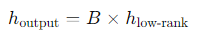
결합과 출력: 최종적으로, 이 h output이 원래 파라미터 행렬과 결합되어 모델의 최종 출력을 결정합니다.
3. 효율적인 학습
LoRA의 효율성은 다음과 같은 방식으로 이루어집니다:
- 저차원 학습: A와 B 행렬이 기존 파라미터 행렬보다 훨씬 적은 파라미터를 가지므로, 이들만 학습하면 되기 때문에 계산 자원과 시간이 절약됩니다.
- 원본 파라미터 유지: 모델의 원래 파라미터는 그대로 유지되므로, 모델의 일반화 능력이 보존됩니다. 이는 모델이 특정 작업에만 과도하게 맞춰지는 것을 방지해 줍니다.
실제 적용 사례
LoRA는 다양한 상황에서 효과적으로 사용될 수 있습니다. 예를 들어, 다음과 같은 경우에 적용할 수 있습니다:
- 자연어 처리(NLP) 작업: 대규모 언어 모델을 특정 도메인(예: 의료, 법률)에 맞게 Fine-Tuning할 때, LoRA를 사용해 저차원 근사를 통해 모델을 조정할 수 있습니다.
- 컴퓨터 비전: 이미지 인식 모델에서도 특정 작업(예: 특정 객체 인식)을 위한 Fine-Tuning에 LoRA를 적용할 수 있습니다.
- 멀티 태스크 학습: 하나의 모델이 여러 작업을 수행해야 할 때, 각 작업에 대해 LoRA를 사용해 별도의 Fine-Tuning을 수행할 수 있습니다.
LoRA는 대규모 모델의 Fine-Tuning을 위해 설계된 매우 효율적인 기법입니다. 저차원 근사와 파라미터 효율적 학습을 통해, 기존의 Fine-Tuning 방법보다 훨씬 적은 자원으로도 높은 성능을 달성할 수 있습니다. 이는 특히 대규모 언어 모델과 같이 많은 파라미터를 가진 모델에서 더욱 유용하게 사용될 수 있습니다.
LoRA의 주요 이점은 파라미터의 변화를 최소화하면서도 원하는 성능을 얻을 수 있다는 점입니다. 이를 통해 Fine-Tuning 과정이 더욱 간단하고 비용 효율적으로 변모하고 있습니다. 앞으로 다양한 인공지능 모델에서 LoRA와 같은 PEFT 기법의 활용이 더욱 확대될 것으로 예상됩니다.
'인공지능' 카테고리의 다른 글
| 프리픽스 튜닝(Prefix Tuning): 효율적인 미세조정 기법의 이해 (0) | 2024.08.22 |
|---|---|
| 2024 LLM 훈련 패러다임: AI 모델의 진화 (0) | 2024.08.21 |
| LangChain과 함께하는 RAG 구현 개념 잡기!! (0) | 2024.08.19 |
| 효율적인 인공지능 Fine Tuning: PEFT에 대해 알아보기(개념 잡기) (0) | 2024.08.19 |
| [LLM] 인공지능, 학습되지 않은 지식을 얻는 두 가지 비법: Fine Tuning과 RAG 개 (0) | 2024.08.19 |



