
Apache Airflow는 워크플로우 관리 플랫폼으로, 데이터 엔지니어링 작업에서 자주 사용됩니다. Airflow는 워크플로우를 작성, 스케줄링, 모니터링할 수 있는 기능을 제공하여, 복잡한 데이터 파이프라인을 효율적으로 관리할 수 있도록 돕습니다.

주요 특징
- DAG (Directed Acyclic Graph):
- Airflow의 워크플로우는 DAG로 정의됩니다. DAG는 작업(Task)들 간의 의존성을 명확히 나타내는 유향 비순환 그래프입니다. 이를 통해 작업의 실행 순서를 제어하고 모니터링할 수 있습니다.
- 모듈화 및 확장성:
- Airflow는 Python 코드로 작성되어 매우 유연하고 확장 가능합니다. 사용자는 다양한 연산자(Operators)와 센서(Sensors)를 활용해 복잡한 워크플로우를 정의할 수 있습니다.
- 스케줄링:
- 크론 표현식(Cron Expression) 또는 다른 시간 기반 표현식을 사용해 워크플로우의 실행을 스케줄링할 수 있습니다.
- UI 및 모니터링:
- Airflow는 웹 기반 UI를 제공하여 DAG의 상태를 시각적으로 확인하고, 개별 작업의 로그를 확인할 수 있습니다. 이를 통해 워크플로우의 상태를 실시간으로 모니터링하고 문제를 빠르게 해결할 수 있습니다.
- 다양한 연산자 지원:
- BashOperator, PythonOperator, MySqlOperator, S3Operator 등 다양한 연산자를 제공하여, 다양한 시스템과의 통합을 쉽게 할 수 있습니다.
Airflow 장점
| 구분 | 내용 |
| 유연성 |
|
| 확장성 |
|
| 가시성 |
|
| 표준화 |
|
Airflow 기본 구성
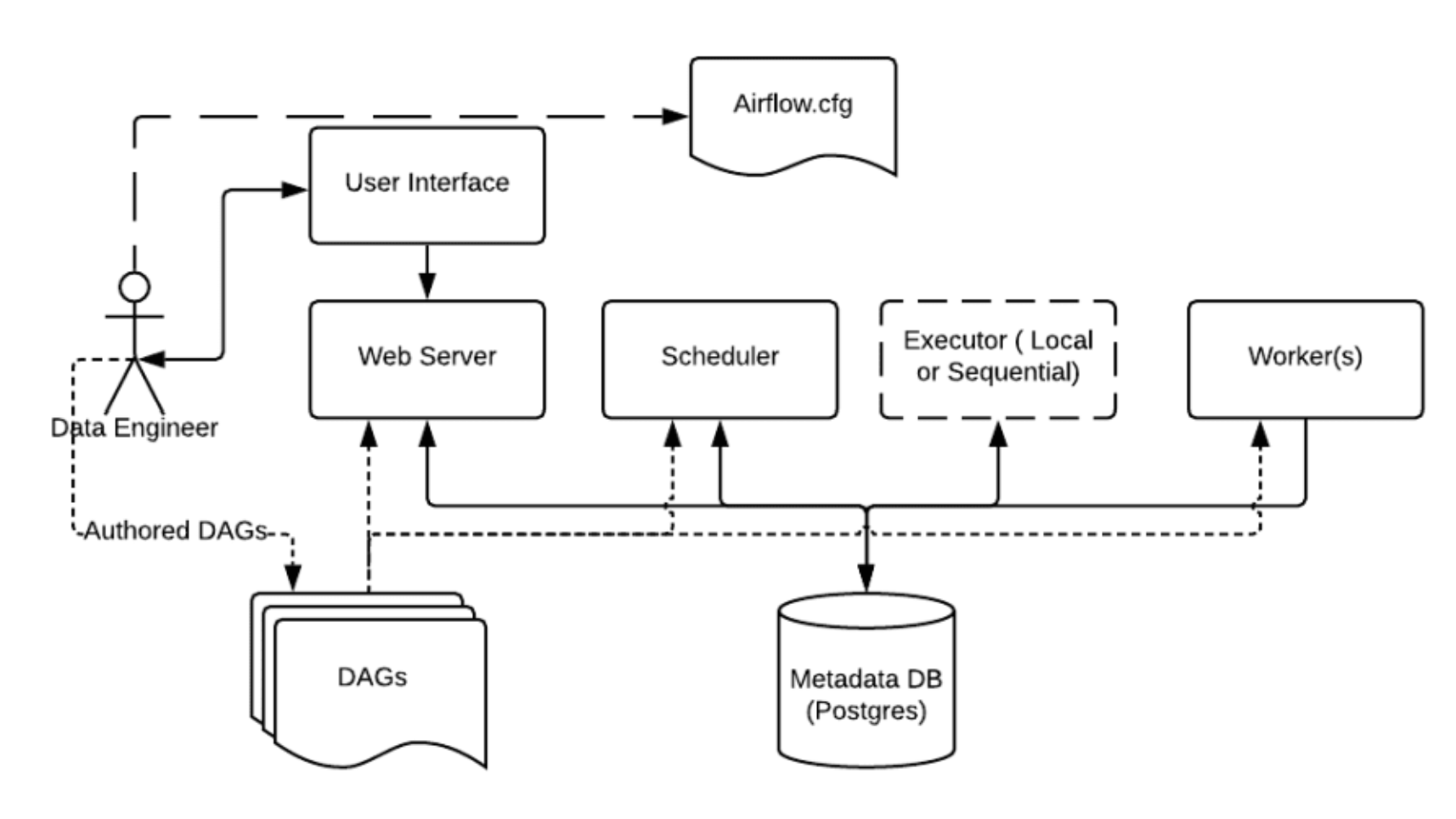
Apache Airflow의 기본 구성 요소와 아키텍처를 이해하는 것은 이를 효과적으로 사용하는 데 필수적입니다.
1. Scheduler
Scheduler는 DAG의 트리거를 감시하고, 트리거된 DAG를 실행할 작업으로 배치합니다. 이는 작업의 스케줄을 관리하며, DAG 정의에 따라 작업을 순서대로 실행합니다.
2. Executor
Executor는 실제로 작업을 실행하는 역할을 합니다. 여러 종류의 Executor가 있으며, 대표적으로 LocalExecutor, CeleryExecutor, KubernetesExecutor 등이 있습니다. 선택한 Executor에 따라 작업이 단일 서버에서 실행되거나, 여러 서버에 분산되어 실행될 수 있습니다.
3. Worker
Worker는 Scheduler에 의해 배치된 작업을 실제로 수행하는 프로세스입니다. CeleryExecutor나 KubernetesExecutor를 사용할 경우, 여러 Worker가 분산된 환경에서 병렬로 작업을 처리할 수 있습니다.
4. Web Server
Web Server는 Airflow의 웹 UI를 제공하여, DAG와 작업의 상태를 모니터링하고, 로그를 확인하며, DAG의 트리거 및 관리 작업을 수행할 수 있게 합니다. Flask 기반으로 동작하며, 사용자는 이를 통해 Airflow의 모든 기능을 시각적으로 관리할 수 있습니다.
5. Metadata Database
Metadata Database는 Airflow의 핵심 정보를 저장하는 데이터베이스입니다. 여기에는 DAG 정의, 작업 상태, 스케줄러 상태, 로그 등이 저장됩니다. 일반적으로 MySQL, PostgreSQL 등을 사용합니다.
6. DAG (Directed Acyclic Graph)

DAG는 작업의 논리적 흐름을 정의하는 구조입니다. 각 DAG는 하나의 워크플로우를 나타내며, 여러 개의 Task로 구성됩니다. Task 간의 의존성을 정의하여 실행 순서를 지정합니다.
7. Task
Task는 실제로 실행되는 작업의 단위입니다. Python 코드, Bash 스크립트, SQL 쿼리 등 다양한 형태로 작성될 수 있으며, Operator를 사용해 정의합니다.
간단한 예시로 훑어보기
간단한 ETL 파이프라인 예시
- 목표:
- S3에 저장된 CSV 파일을 읽고, 데이터를 변환한 후, 변환된 데이터를 MySQL 데이터베이스에 로드합니다.
- DAG 정의
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.mysql_operator import MySqlOperator
from airflow.contrib.operators.s3_to_gcs_operator import S3ToGCSOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 6, 1),
'retries': 1,
}
def extract():
# S3에서 데이터를 추출하는 로직
pass
def transform():
# 데이터를 변환하는 로직
pass
def load():
# 데이터를 MySQL로 로드하는 로직
pass
with DAG('simple_etl', default_args=default_args, schedule_interval='@daily') as dag:
extract_task = PythonOperator(task_id='extract', python_callable=extract)
transform_task = PythonOperator(task_id='transform', python_callable=transform)
load_task = PythonOperator(task_id='load', python_callable=load)
extract_task >> transform_task >> load_task설명:
- extract_task: S3에서 데이터를 추출하는 작업입니다.
- transform_task: 추출한 데이터를 변환하는 작업입니다.
- load_task: 변환된 데이터를 MySQL에 로드하는 작업입니다.
- extract_task, transform_task, load_task는 의존 관계에 따라 순차적으로 실행됩니다.
'빅데이터' 카테고리의 다른 글
| ETL vs ELT - 데이터 처리 접근 방식 차이점 알아보기 (0) | 2024.06.14 |
|---|---|
| [dbt] dbt란 무엇인가? (0) | 2024.06.14 |
| [Flink] Apache Flink란 무엇인가? (0) | 2024.06.10 |
| [Spark] Apache Spark란 무엇인가? (0) | 2024.06.10 |
| [데이터 거버넌스] 데이터 거버넌스란 무엇인가? (0) | 2024.06.09 |



