
Apache Spark란 무엇인가?

Apache Spark는 대규모 데이터 처리를 위해 설계된 오픈 소스 분산 데이터 처리 프레임워크입니다. 주로 빅데이터 처리를 위한 빠르고 일반적인 엔진으로 사용됩니다. Spark는 Hadoop MapReduce와 같은 분산 컴퓨팅 시스템의 대안으로 개발되었으며, 대규모 데이터를 효율적으로 처리하기 위해 인메모리(메모리 내) 컴퓨팅을 활용합니다.
주요 특징
- 속도: Spark는 인메모리 컴퓨팅을 통해 디스크 기반 처리보다 최대 100배 더 빠른 성능을 제공합니다. 이는 데이터를 메모리에 유지하여 반복 작업에서 성능 저하를 방지합니다.
- 확장성: Spark는 클러스터의 수천 대의 노드에서 작업을 실행할 수 있어 대규모 데이터 세트를 처리하는 데 매우 효율적입니다.
- 다양한 언어 지원: Spark는 Java, Scala, Python, R 및 SQL을 지원하여 다양한 개발자와 데이터 과학자가 쉽게 접근할 수 있습니다.
- 풍부한 API: Spark는 데이터 스트리밍, 머신 러닝, 그래프 처리, SQL 쿼리 등의 다양한 작업을 수행할 수 있는 API를 제공합니다.
- 통합: Spark는 Hadoop HDFS, Cassandra, HBase, Hive 등과 같은 다양한 데이터 소스와의 통합을 지원합니다.
장점
- 빠른 속도: 앞서 언급한 것처럼 인메모리 처리를 통해 매우 빠른 속도를 자랑합니다. 이는 대규모 데이터 분석 및 머신 러닝 모델 훈련 시 매우 유용합니다.
- 유연성: 다양한 언어와 데이터 소스 지원으로 인해 데이터 과학자와 엔지니어들이 필요에 맞게 사용할 수 있습니다.
- 확장 가능성: 작은 규모의 작업에서부터 매우 큰 규모의 작업까지 손쉽게 확장할 수 있습니다. 이는 클러스터 관리 도구와의 통합으로 더욱 강화됩니다.
- 간편한 사용: 풍부한 API와 함께 간편한 사용성 덕분에 개발자들이 빠르게 학습하고 활용할 수 있습니다.
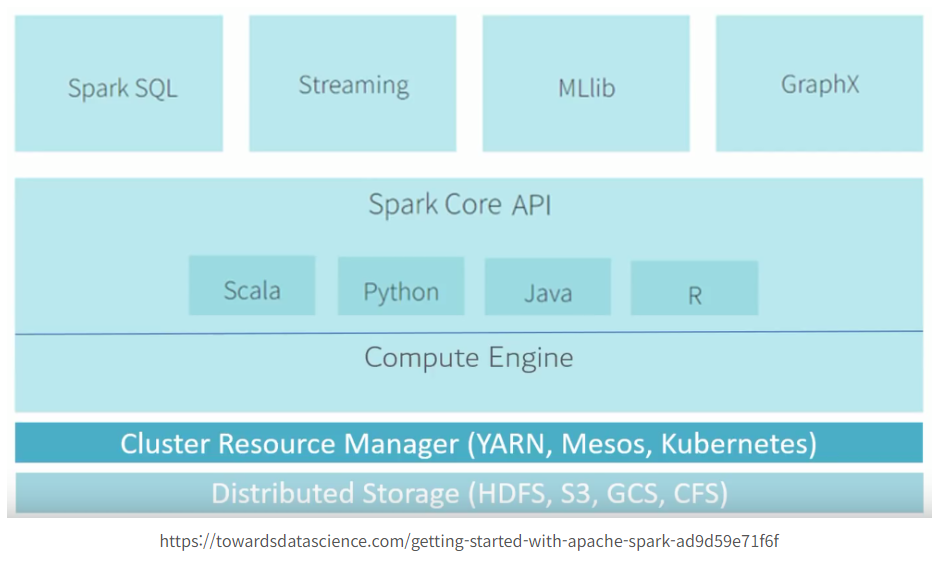
Apache Spark의 구조는 매우 유연하고 확장 가능하게 설계되어 있습니다. Spark는 다양한 컴포넌트로 구성되어 있으며, 각 컴포넌트는 특정 작업을 처리하는 데 최적화되어 있습니다. Spark의 구조를 이해하는 것은 그 작동 원리를 이해하는 데 중요합니다. Spark의 주요 구성 요소와 그 역할에 대해 상세히 설명하겠습니다.
Spark의 주요 구성 요소
- Spark Core
- Spark SQL
- Spark Streaming
- MLlib (Machine Learning Library)
- GraphX
이제 각 구성 요소를 자세히 살펴보겠습니다.
1. Spark Core
Spark Core는 Spark의 중심적인 엔진으로, 다음과 같은 기능을 수행합니다:
- 작업 스케줄링: 작업(Job)을 클러스터의 여러 노드에 분배하고 스케줄링합니다.
- 메모리 관리: 인메모리 컴퓨팅을 통해 데이터 처리를 가속화합니다.
- 장애 복구: 작업 중에 발생하는 오류를 감지하고 복구합니다.
- RDD (Resilient Distributed Dataset): Spark Core는 RDD라는 불변의 분산 데이터 구조를 제공합니다. RDD는 병렬 처리를 지원하고 장애 발생 시 데이터를 복구할 수 있는 기능을 제공합니다.
2. Spark SQL
Spark SQL은 구조화된 데이터를 처리하고 쿼리하는 데 사용되는 컴포넌트입니다. 주요 기능은 다음과 같습니다:
- DataFrame API: 데이터프레임은 분산 데이터 컬렉션으로, 구조화된 데이터를 다루기 위한 고수준 API를 제공합니다.
- Dataset API: 데이터셋은 강타입화된 API로, 컴파일 시점에 데이터의 타입을 검사할 수 있습니다.
- SQL 쿼리: Spark SQL을 통해 SQL 쿼리를 작성하고 실행할 수 있습니다. Hive와의 통합도 지원하여 기존 Hive 쿼리를 쉽게 실행할 수 있습니다.
- 통합: 다양한 데이터 소스 (HDFS, Cassandra, HBase 등)와의 통합을 지원합니다.
3. Spark Streaming
Spark Streaming은 실시간 데이터 스트리밍 처리를 위한 컴포넌트입니다. 주요 기능은 다음과 같습니다:
- DStream (Discretized Stream): 연속적인 실시간 데이터 스트림을 RDD의 연속으로 처리합니다.
- 변환 연산: 맵(map), 리듀스(reduce), 조인(join) 등의 변환 연산을 실시간 데이터 스트림에 적용할 수 있습니다.
- 통합: Kafka, Flume, Kinesis 등 다양한 데이터 소스와의 통합을 지원합니다.
4. MLlib
MLlib는 기계 학습 라이브러리로, 다음과 같은 기능을 제공합니다:
- 알고리즘: 분류, 회귀, 군집화, 협업 필터링 등의 다양한 기계 학습 알고리즘을 제공합니다.
- 특징 추출: 텍스트 데이터 처리, 피처 변환 등의 기능을 포함합니다.
- 평가 지표: 모델 성능 평가를 위한 다양한 지표를 제공합니다.
- 파이프라인: 데이터 처리와 모델 학습 과정을 연결하는 파이프라인을 구성할 수 있습니다.
5. GraphX
GraphX는 그래프 데이터 처리를 위한 컴포넌트입니다. 주요 기능은 다음과 같습니다:
- 그래프 생성 및 변환: 정점(Vertex)과 간선(Edge)을 이용하여 그래프를 생성하고 변환할 수 있습니다.
- 그래프 알고리즘: 페이지랭크(PageRank), 연결 요소(Connected Components), 삼중족검출(Triangle Counting) 등의 그래프 알고리즘을 제공합니다.
- 속성 그래프: 속성을 가진 정점과 간선을 처리할 수 있습니다.
Spark의 실행 구조
Spark의 실행 구조는 클러스터 매니저, 드라이버 프로그램, 익스큐터로 구성됩니다.
- 드라이버 프로그램: 사용자가 작성한 애플리케이션을 실행하며, 메인 함수를 포함하고 있습니다. 드라이버는 작업(Job)을 DAG(Directed Acyclic Graph)로 나누고, 각 작업을 태스크(Task)로 분할하여 익스큐터에게 분배합니다.
- 클러스터 매니저: 클러스터 리소스를 관리하는 역할을 합니다. Spark는 다양한 클러스터 매니저를 지원합니다:
- Standalone: Spark 전용 클러스터 매니저
- YARN (Yet Another Resource Negotiator): Hadoop 에코시스템에서 널리 사용됨
- Mesos: 다양한 프레임워크를 지원하는 범용 클러스터 매니저
- Kubernetes: 컨테이너 기반 클러스터 매니저
- 익스큐터: 클러스터의 각 노드에서 실행되며, 실제 작업(Task)을 수행합니다. 각 익스큐터는 메모리와 디스크를 사용하여 데이터를 처리하고 저장합니다.
Spark 예시
Java로 DataFrame 처리 예시
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.functions;
public class SparkDataFrameExample {
public static void main(String[] args) {
// Spark 세션 생성
SparkSession spark = SparkSession.builder()
.appName("Java Spark DataFrame Example")
.master("local")
.getOrCreate();
// CSV 파일에서 DataFrame 읽기
Dataset<Row> df = spark.read().option("header", "true").csv("path/to/data.csv");
// DataFrame 출력
df.show();
// 특정 조건으로 필터링
Dataset<Row> filteredDf = df.filter(df.col("age").gt(30));
// 필터링된 DataFrame 출력
filteredDf.show();
// 집계 작업 (age 컬럼의 평균 계산)
Dataset<Row> avgAge = df.agg(functions.avg("age"));
// 결과 출력
avgAge.show();
// Spark 세션 종료
spark.stop();
}
}Python으로 DataFrame 처리 예시
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
# Spark 세션 생성
spark = SparkSession.builder \
.appName("Python Spark DataFrame Example") \
.master("local") \
.getOrCreate()
# CSV 파일에서 DataFrame 읽기
df = spark.read.option("header", "true").csv("path/to/data.csv")
# DataFrame 출력
df.show()
# 특정 조건으로 필터링
filtered_df = df.filter(df.age > 30)
# 필터링된 DataFrame 출력
filtered_df.show()
# 집계 작업 (age 컬럼의 평균 계산)
avg_age = df.agg(avg("age"))
# 결과 출력
avg_age.show()
# Spark 세션 종료
spark.stop()'빅데이터' 카테고리의 다른 글
| [Airflow] Airflow란 무엇인가? (0) | 2024.06.13 |
|---|---|
| [Flink] Apache Flink란 무엇인가? (0) | 2024.06.10 |
| [데이터 거버넌스] 데이터 거버넌스란 무엇인가? (0) | 2024.06.09 |
| [객체 스토리지] Object Storage(객체 스토리지)란 무엇인가? (0) | 2024.06.04 |
| [빅데이터] Data Mesh란 무엇인가? (0) | 2024.05.27 |



