🔍 DeepGEMM이란?
최근 딥러닝 모델이 점점 커지고, 계산량이 급격히 증가하면서 FP8(Floating Point 8-bit) 연산이 주목받고 있습니다. FP8은 기존 FP16/FP32보다 메모리 사용량을 줄이면서도 높은 연산 성능을 유지할 수 있어 특히 NVIDIA Hopper 아키텍처에서 강력한 성능을 발휘합니다.
DeepGEMM은 FP8 기반의 일반 행렬 곱셈(GEMM) 연산을 효율적으로 수행하는 CUDA 라이브러리로, DeepSeek-V3 모델에서 제안된 미세 조정 스케일링(fine-grained scaling) 방식을 지원합니다. 특징적으로, Mix-of-Experts(MoE) 모델의 그룹화 GEMM(Grouped GEMM)도 지원하여 최신 AI 모델에서의 효율적인 연산을 돕습니다.
또한, JIT(Just-In-Time) 컴파일을 활용한 경량 설계로, 설치 과정에서 별도의 컴파일이 필요하지 않으며, NVIDIA Hopper Tensor Core에 최적화된 연산을 제공합니다.
🔹 DeepGEMM의 주요 특징
✅ 1. FP8 GEMM 연산 최적화
- FP8 행렬 연산을 활용해 기존 FP16/FP32보다 메모리 사용량 감소 및 연산 속도 향상
- Hopper Tensor Core 전용 최적화로 높은 연산 성능 제공
- CUDA 코어 기반 이중 누적(promotion) 기법을 사용하여 FP8 연산의 정확도 문제 보완
✅ 2. Mix-of-Experts(MoE) 모델 지원
- Grouped GEMM 연산을 제공하여 MoE 모델의 전문가(Experts) 연산을 최적화
- 연속된(Contiguous) 및 마스킹(Masked) 레이아웃 지원
- Contiguous: M 축을 기준으로 그룹화하여 연산 수행
- Masked: CUDA 그래프 활용 시 특정 토큰만 연산하도록 최적화
✅ 3. JIT(Just-In-Time) 컴파일을 통한 경량 설계
- 설치 시 별도 컴파일 없이 실행 시점(runtime)에서 자동 커널 생성
- CUTLASS 및 CuTe와 비교하여 템플릿 의존도 최소화
- 약 300줄의 커널 코드로 간결한 코드베이스 유지
✅ 4. 기존 라이브러리 대비 뛰어난 성능
- 일반 GEMM 및 MoE 모델에서 전문가 수준의 성능을 발휘
- 다양한 행렬 크기에서 최대 2.7배 성능 향상
- 특정 MoE 모델에서 1.1~1.2배 속도 개선
⚡ DeepGEMM 성능 비교
📌 일반 GEMM 성능 (Dense 모델 기준)
DeepSeek-V3/R1 환경에서 성능 테스트를 진행한 결과, NVIDIA H800 GPU(NVCC 12.8) 환경에서 CUTLASS 3.6 기반의 내부 최적화 버전과 비교 시 최대 2.7배 속도 향상을 보였습니다.
행렬 크기 (M, N, K) 연산 성능 (TFLOPS) 속도 향상 (배)
| 행렬 크기 (M, N, K) | 연산성능(TFLOPS) | 속도 향상(배) |
| 64 × 2112 × 7168 | 206 | 2.7x |
| 64 × 24576 × 1536 | 289 | 1.7x |
| 128 × 2112 × 7168 | 352 | 2.4x |
| 128 × 7168 × 2048 | 510 | 1.7x |
📌 MoE 모델을 위한 그룹화 GEMM 성능
MoE 모델에서는 전문가의 연산을 그룹화하여 성능을 극대화합니다.
그룹 개수 M per group N K 연산 성능 (TFLOPS) 속도 향상 (배)
| 그룹개수 | M per group | N | K | 연산성능(TFLOPS) | 속도 향상(배) |
| 4 | 8192 | 4096 | 7168 | 1297 | 1.2x |
| 8 | 4096 | 4096 | 7168 | 1288 | 1.2x |
🚀 DeepGEMM 빠른 시작 가이드 (Quick Start)
📌 1. 설치 방법
DeepGEMM은 JIT 컴파일을 사용하므로 별도의 컴파일 과정 없이 간단하게 설치할 수 있습니다.
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
python setup.py install
📌 2. 기본 FP8 GEMM 연산 실행
Python에서 DeepGEMM을 불러와 FP8 GEMM 연산을 수행할 수 있습니다.
import deep_gemm
# FP8 GEMM 실행
output = deep_gemm.gemm_fp8_fp8_bf16_nt(lhs, rhs)
📌 3. Grouped GEMM 실행 (MoE 모델 지원)
Grouped GEMM을 활용해 MoE 모델의 연산을 최적화할 수 있습니다.
output = deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous(lhs, rhs, num_groups=4)
🎯 DeepGEMM의 핵심 최적화 기법
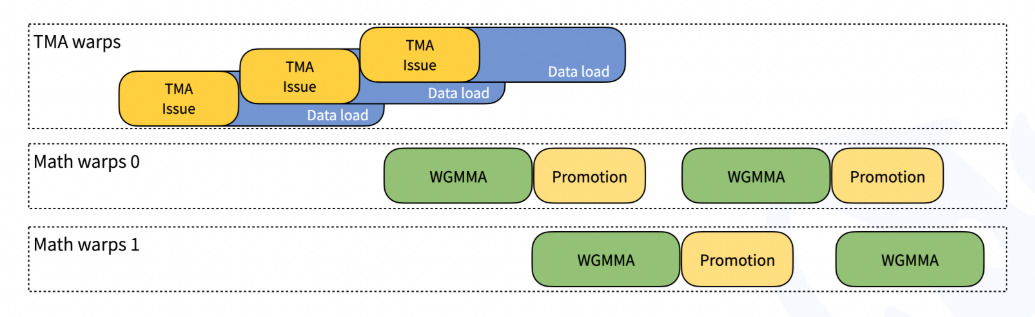
🔹 1. Hopper TMA (Tensor Memory Accelerator) 활용
- TMA Load/Store 최적화를 통해 데이터 이동 속도를 극대화
- TMA Multicast 및 TMA Descriptor Prefetching 지원
🔹 2. FFMA SASS Interleaving 최적화
- FFMA(Fused Multiply-Add) 명령어 간의 인터리빙(Interleaving) 적용
- 연산 중 레지스터 재사용률을 높여 최대 10% 이상의 성능 개선
🔹 3. 블록 크기 최적화 (Unaligned Block Sizes)
- GPU Streaming Multiprocessors(SMs) 활용도를 극대화하기 위해 블록 크기 조정
- M=256, N=7168의 경우 기존 128 정렬 대신 112 크기의 블록을 사용하여 SM 활용도를 증가
🔮 DeepGEMM이 가져올 변화
DeepGEMM은 NVIDIA Hopper 아키텍처에 최적화된 초경량 FP8 GEMM 라이브러리로,
✅ 일반 FP8 GEMM 및 MoE 모델에서 높은 성능을 제공하며,
✅ JIT 기반 경량 설계로 사용이 간편합니다.
특히, FP8 연산 최적화와 CUDA 기반 최적화 기법을 적용하여 기존 라이브러리 대비 더 빠른 연산 속도와 낮은 메모리 사용량을 제공합니다.
GitHub - deepseek-ai/DeepGEMM: DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling
DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling - deepseek-ai/DeepGEMM
github.com

'인공지능' 카테고리의 다른 글
| GPT-4.5: AI의 새로운 도약! 무엇이 달라졌을까? (0) | 2025.02.28 |
|---|---|
| Claude 3.7과 Grok 3: 새로운 세대의 AI는 얼마나 강력할까? (0) | 2025.02.27 |
| Claude Code: AI 기반 개발 도우미 – 코드 작성부터 Git 관리까지 한 번에 (0) | 2025.02.26 |
| 무료 AI 코딩 도우미, Gemini Code Assist 공개! (0) | 2025.02.26 |
| [DeepSeek 두번째 공개] DeepEP: Mixture-of-Experts를 위한 고성능 GPU 통신 라이브러리 (0) | 2025.02.25 |



