오늘날 정보 검색(Information Retrieval)은 효율적이고 정확한 결과를 제공하기 위해 빠르게 발전하고 있습니다. 그러나 대부분의 기존 임베딩 모델은 영어 중심으로 설계되고, 특정 검색 방식에만 제한되며, 긴 문서를 처리하기 어려운 한계를 가지고 있었습니다. 이런 문제를 해결하기 위해 등장한 BGE M3-Embedding은 다국어 지원, 다기능 검색, 긴 문서 처리 능력을 하나로 통합한 혁신적인 모델입니다. 이 블로그에서는 BGE M3-Embedding의 주요 특징, 기술적 혁신, 성능 및 활용 가능성을 살펴보겠습니다.
BGE M3-Embedding의 배경과 필요성
기존 임베딩 모델의 한계
- 언어적 제한: 대부분의 모델은 영어에 최적화되어 있어 다른 언어에서는 성능이 저하됩니다.
- 단일 검색 방식: 하나의 검색 방식에 특화된 모델은 다양한 검색 작업에서 유연성이 부족합니다.
- 긴 문서 처리 미흡: 긴 문서를 처리하거나 분석하는 데 어려움이 있습니다.
BGE M3-Embedding은 이러한 문제를 해결하기 위해 설계된 다목적 임베딩 모델입니다.
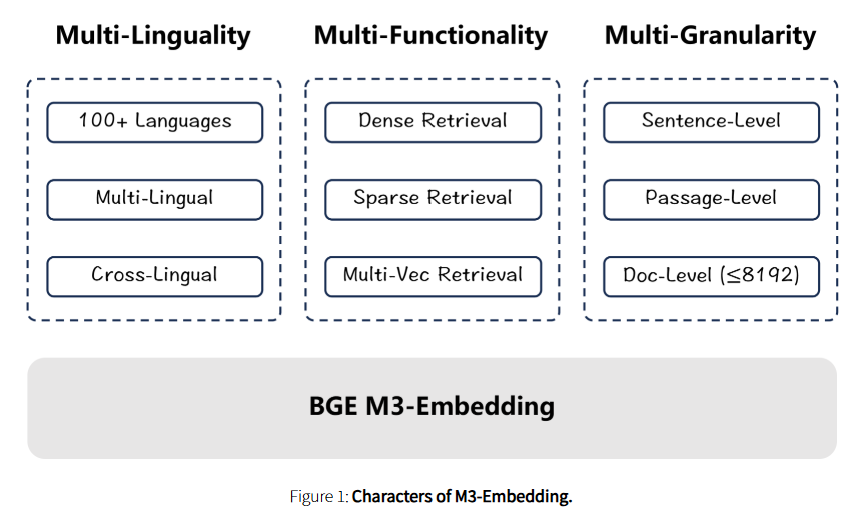
BGE M3-Embedding의 주요 특징
1. 다국어 지원 (Multi-Linguality)
- 100개 이상의 언어를 지원하며, 한국어를 포함한 다양한 언어의 문서를 효율적으로 검색할 수 있습니다.
- 교차 언어 검색: 영어로 질문하고 한국어 문서를 검색하거나 그 반대도 가능합니다.
2. 다기능 검색 (Multi-Functionality)
- Dense Retrieval, Sparse Retrieval, Multi-Vector Retrieval을 모두 지원하며, 하나의 모델에서 통합적으로 작동합니다.
- Self-Knowledge Distillation 기술을 통해 각 검색 방식의 점수를 통합하여 최적의 검색 결과를 제공합니다.
3. 다중 입력 길이 지원 (Multi-Granularity)
- 최대 8192 토큰 길이의 문서도 처리 가능하도록 설계되었습니다.
- 짧은 문장과 긴 문단 단위 모두에서 뛰어난 성능을 발휘합니다.
- 효율적인 배칭 전략을 적용해 긴 시퀀스 처리에서도 높은 효율성을 보장합니다.
검색 방식의 세부 설명
Dense Retrieval
- 사전 훈련된 인코더(예: BERT)를 활용하여 질문과 문서의 [CLS] 토큰 임베딩으로 유사도를 계산합니다.
Sparse Retrieval
- BM25와 같은 기존 방식의 연장선에서, 단어 토큰에 초점을 맞춘 검색 방식을 적용합니다.
- 각 토큰의 임베딩 값을 활용해 더 정밀한 검색 결과를 제공합니다.
Multi-Vector Retrieval
- Dense 방식과 달리 모든 토큰 임베딩을 활용하거나, 질문 및 문서를 변형해 복수의 벡터를 생성합니다.
- 예: 질문에 대한 다양한 유사 질문을 생성하거나, 문서를 요약하여 여러 벡터를 생성해 검색의 다양성과 정확도를 높입니다.
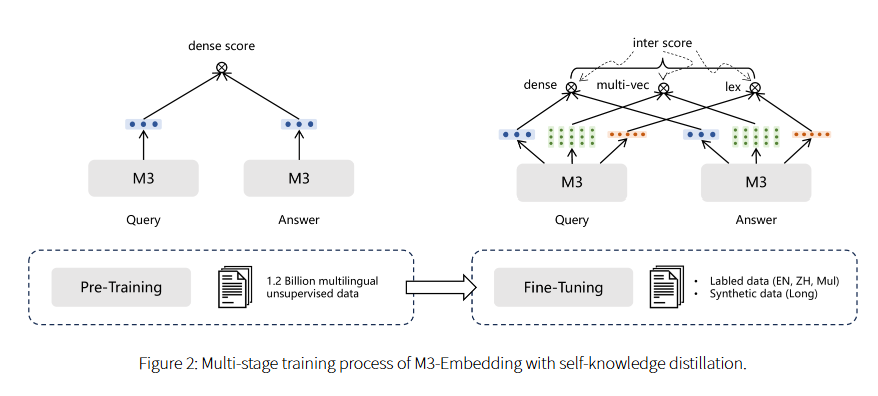
기술적 혁신
1. Self-Knowledge Distillation
- Dense, Sparse, Multi-Vector Retrieval에서 나온 점수를 결합해 모델 학습을 최적화합니다.
2. 효율적인 배칭 전략
- 긴 문서 및 다양한 입력 길이를 처리하기 위해 대규모 배치 크기를 효율적으로 관리하는 전략을 적용했습니다.
3. 종합적인 데이터 큐레이션
- Wikipedia, 뉴스, 번역 데이터셋 등 다양한 출처에서 데이터를 수집하고, 교차 언어 검색을 지원하기 위해 번역 데이터를 활용했습니다.
- GPT-3.5를 활용해 긴 문서와 질문 데이터를 생성하며 데이터 증강을 수행했습니다.
BGE M3-Embedding의 성능 평가
BGE M3-Embedding은 다국어(MIRACL) 및 교차 언어(MKQA) 검색 벤치마크에서 기존 모델들을 뛰어넘는 성과를 보였습니다. 특히 긴 문서 검색에서 Sparse와 Dense Retrieval 방식을 결합하여 탁월한 성능을 발휘했습니다.
BGE M3-Embedding은 다국어 지원, 다양한 검색 기능, 긴 문서 처리 능력을 통합한 강력한 임베딩 솔루션입니다. 이 모델은 연구자와 실무자 모두에게 유용하며, 글로벌 정보 검색 작업에서 특히 큰 가치를 제공합니다.
앞으로 BGE M3-Embedding이 공개된다면, 더욱 다양한 분야에서 활용될 가능성이 큽니다. 다국어 데이터를 다루는 글로벌 기업, 학계 연구자, 그리고 정보 검색 시스템 개발자는 이 모델을 통해 새로운 차원의 검색 효율성을 경험할 수 있을 것입니다.
https://arxiv.org/html/2402.03216v3
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
HTML conversions sometimes display errors due to content that did not convert correctly from the source. This paper uses the following packages that are not yet supported by the HTML conversion tool. Feedback on these issues are not necessary; they are kno
arxiv.org

'인공지능' 카테고리의 다른 글
| Agent Laboratory: 연구 생산성을 혁신하는 AI 기반 연구 도우미 (0) | 2025.01.10 |
|---|---|
| 2025년을 선도할 Agentic AI 프레임워크 TOP 5 소개 (0) | 2025.01.10 |
| 에이전틱 AI 시대의 혁신: NVIDIA Llama Nemotron과 Cosmos Nemotron이 만드는 AI의 미래 (0) | 2025.01.09 |
| NVIDIA Project DIGITS: 책상 위 AI 슈퍼컴퓨터의 새로운 시대 (0) | 2025.01.09 |
| 최신 AI 시대를 이끄는 프롬프트 엔지니어링: 7가지 고급 테크닉으로 LLM을 최대한 활용하기 (0) | 2025.01.09 |



