
AI 기술이 발전함에 따라, 대규모 언어 모델(LLM)은 이제 더 이상 미래의 이야기가 아닙니다. 특히 Qwen 2.5는 그 중에서도 탁월한 성능을 자랑하며, AI 연구와 개발에 새로운 이정표를 세우고 있습니다. Qwen 2.5는 중국의 거대 클라우드 서비스 제공업체인 Alibaba Cloud에서 개발한 최신 LLM으로, 특히 오픈소스 모델로써 개발자 커뮤니티에서 큰 주목을 받고 있습니다.
이번 블로그에서는 Qwen 2.5가 무엇인지, 어떤 점에서 우수한 성능을 발휘하는지, 그리고 이 모델이 가진 다양한 특징과 사용 방법을 살펴보겠습니다.
Qwen 2.5란 무엇인가?
Qwen 2.5는 Alibaba Cloud의 Qwen 팀에서 개발한 최신 대규모 언어 모델로, 2024년 가장 주목받는 AI 기술 중 하나입니다. Qwen 2가 출시된 이후 약 3개월 동안 전 세계 개발자들의 피드백을 바탕으로 개선된 Qwen 2.5는, 그 규모와 성능에서 오픈소스 LLM 중 선두에 서 있습니다.
특히 Qwen 2.5는 언어 이해 및 생성, 멀티미디어 이해, 도구 사용 등 다양한 작업에서 강력한 성능을 발휘합니다. 또한 전 세계적으로 가장 큰 오픈소스 릴리스 중 하나로, 수많은 연구자와 개발자들이 이를 활용해 다양한 AI 응용 프로그램을 개발하고 있습니다.
Qwen 2.5의 주요 특징
1. 다양한 모델 크기
Qwen 2.5는 0.5B에서 72B에 이르는 다양한 크기의 모델로 제공됩니다. 사용자는 자신의 요구에 맞는 크기의 모델을 선택할 수 있으며, 소형 모델부터 대형 모델까지 폭넓은 선택지를 제공합니다. 베이스 모델과 지시 조정(Instruct) 모델이 함께 제공되며, 이들 모두 각각의 사용 사례에 최적화되어 있습니다.
2. 방대한 학습 데이터
Qwen 2.5는 최대 18조 토큰에 이르는 최신 대규모 데이터셋으로 학습되었습니다. 이는 자연어 처리(NLP) 분야에서 Qwen 2.5가 매우 강력한 성능을 발휘할 수 있게 만드는 중요한 요소입니다. 특히 이 모델은 최신 데이터셋을 사용하여 더 정확하고 신뢰성 높은 결과를 제공할 수 있습니다.
3. 긴 컨텍스트 처리
Qwen 2.5는 최대 128K 토큰의 컨텍스트 길이를 지원합니다. 이는 더 복잡한 문맥을 이해하고 긴 텍스트를 생성할 수 있는 능력을 의미합니다. 실제로 8K 이상의 텍스트를 생성할 수 있는 Qwen 2.5는 대규모 문서 작성이나 요약과 같은 작업에 최적화되어 있습니다.
4. 다국어 지원
Qwen 2.5는 29개 이상의 언어를 지원하며, 중국어, 영어, 한국어를 포함한 다양한 언어에서 높은 성능을 자랑합니다. 다국어 지원 기능 덕분에 글로벌 사용자들이 언어에 구애받지 않고 이 모델을 활용할 수 있습니다.
5. 뛰어난 성능
Qwen 2.5는 여러 벤치마크 테스트에서 **지시 조정 모델(Instruct Model)**이 특히 우수한 성능을 보였으며, 코딩, 수학, 다국어 이해, 지식 획득 등 다양한 분야에서 타 모델 대비 뛰어난 결과를 제공합니다. 이러한 성능은 Qwen 2.5가 LLM 분야에서 오픈소스 중 최상위 모델 중 하나로 평가받는 이유입니다.
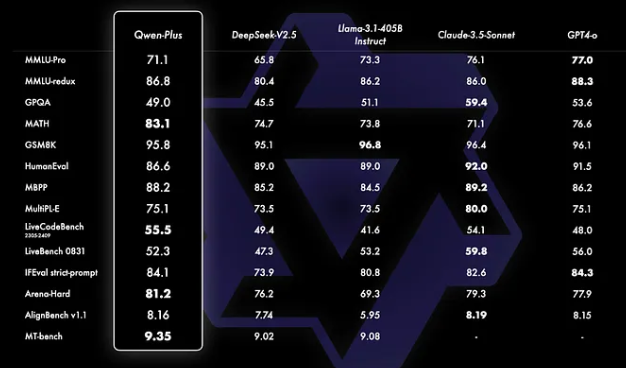
특화 모델: Qwen 2.5-Coder와 Qwen 2.5-Math

1. Qwen 2.5-Coder
Qwen 2.5-Coder는 코드 작성에 특화된 모델입니다. 5.5조 토큰에 이르는 코드 데이터를 학습했으며, 다양한 프로그래밍 언어를 지원합니다. 이 모델은 코드 디버깅, 질문 응답, 코드 추천 등 여러 작업에서 뛰어난 성능을 발휘하며, 대형 모델에 필적하는 성능을 보입니다. 개발자들에게는 실질적인 도움을 줄 수 있는 중요한 도구로 자리 잡을 것입니다.
2. Qwen 2.5-Math
수학 전용으로 설계된 Qwen 2.5-Math는, 이전 버전보다 더 많은 수학 데이터를 학습했으며, Chain-of-Thought(CoT), Program-of-Thought(PoT), Tool-Integrated Reasoning(TIR) 등의 고급 추론 방법을 통합하였습니다. 이로 인해 일반적인 수학 문제를 해결하는 데 뛰어난 능력을 발휘합니다.
Hugging Face를 통해 간단히 Qwen 2.5 사용하기
Qwen 2.5를 활용하는 가장 간단한 방법 중 하나는 Hugging Face의 Transformer 라이브러리를 사용하는 것입니다. 아래 코드를 통해 Qwen 2.5를 직접 활용해 볼 수 있습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Qwen 2.5 모델 로드
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 프롬프트 생성
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
# 텍스트 처리 및 생성
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)Qwen 2.5는 다양한 크기의 모델을 제공하며, 방대한 학습 데이터와 뛰어난 다국어 지원, 긴 컨텍스트 처리 능력 등에서 다른 오픈소스 LLM보다 한 발 앞서 있습니다. 특히 특화 모델인 Qwen 2.5-Coder와 Qwen 2.5-Math는 각각 코드 작성과 수학 문제 해결에 매우 강력한 성능을 발휘하여 다양한 개발자 및 연구자들에게 실질적인 도움을 줄 수 있습니다.
이 모델은 다양한 플랫폼에서 쉽게 활용할 수 있으며, AI 연구와 개발을 한 단계 더 발전시키고자 하는 사용자들에게 큰 가치를 제공합니다.


'인공지능' 카테고리의 다른 글
| 적은 자원으로도 모델의 재학습이 가능하다? Unsloth로 효율적인 CPT 구현하기 (0) | 2024.10.21 |
|---|---|
| CPU에서도 거대한 언어 모델을 가볍게! Microsoft의 혁신적 오픈소스 프레임워크, bitnet.cpp (0) | 2024.10.21 |
| Instruct Model: 대화형 인공지능의 미래를 엿보다 (0) | 2024.10.18 |
| 혁신적인 정보 탐색의 진화: Perplexity의 '내부 지식 검색'과 '스페이스'를 소개합니다 (0) | 2024.10.18 |
| 가난한 자의 파인튜닝 솔루션: Unsloth로 효율적인 모델 튜닝하기 (0) | 2024.10.16 |



