
XAI(설명 가능한 인공지능, eXplainable AI)는 인공지능(AI) 모델의 결정을 사람이 이해할 수 있게 만드는 기술과 방법론을 의미합니다. 일반적인 AI 모델, 특히 딥러닝 모델은 '블랙박스'로 작동하는 경우가 많습니다. 이는 모델이 어떻게 특정 결정을 내리는지 이해하기 어렵다는 것을 의미합니다. XAI는 이런 블랙박스를 열어보고 그 안을 설명할 수 있도록 하는 것이 목표입니다.
Black Box 모델
블랙박스 모델(Black Box Model)은 내부 구조나 작동 방식이 복잡하여 사람이 이해하기 어려운 AI 모델을 의미합니다. 이러한 모델은 입력 데이터를 받아서 결과를 출력하지만, 그 과정이 어떻게 이루어지는지 명확히 알기 어렵습니다. 딥러닝 모델, 특히 심층 신경망이 대표적인 블랙박스 모델입니다.
블랙박스 모델의 특성
복잡한 내부 구조: 수백만 개의 매개변수와 여러 층(layer)을 가진 신경망 구조.
높은 예측 성능: 데이터를 잘 학습하여 높은 정확도의 결과를 도출하지만, 과정은 불투명함.
설명 어려움: 모델의 예측 결과가 왜 그렇게 나왔는지 설명하기 어려움.
왜 XAI가 중요한가요?
- 투명성: AI가 내린 결정의 이유를 알 수 있으면, 시스템에 대한 신뢰도가 높아집니다. 예를 들어, 의료 진단에서 AI가 특정 병을 진단했다고 할 때, 그 이유를 설명할 수 있으면 의사와 환자가 그 결과를 더 신뢰할 수 있습니다.
- 책임성: AI의 결정을 설명할 수 있으면, 잘못된 결정에 대해 누구에게 책임이 있는지 명확히 할 수 있습니다. 예를 들어, 자동화된 금융 시스템이 대출 신청을 거부했을 때, 그 이유를 설명할 수 있어야 대출 신청자가 이의를 제기할 수 있습니다.
- 규제 준수: 많은 국가와 산업에서는 AI 사용에 대한 규제가 강화되고 있습니다. 특히, GDPR(일반 데이터 보호 규정) 같은 규정은 AI 결정에 대해 설명할 수 있어야 한다고 요구합니다.
- 모델 개선: AI 모델이 어떻게 작동하는지 이해하면, 모델을 더 쉽게 개선할 수 있습니다. 오류나 편향성을 발견하고 수정하는 데 도움이 됩니다.
XAI의 주요 기술들
XAI를 구현하는 데 사용되는 몇 가지 주요 기술이 있습니다.
- 특성 중요도: 각 입력 변수(특성)가 모델의 결정에 얼마나 영향을 미쳤는지 평가합니다. 예를 들어, 주택 가격을 예측하는 모델에서 '지역', '방의 수', '건축 연도' 등의 특성이 각각 얼마나 중요한지 알 수 있습니다.
- LIME(Local Interpretable Model-agnostic Explanations): 특정 예측 결과를 설명하기 위해 간단한 모델(예: 선형 회귀)을 사용하여 복잡한 모델을 근사합니다. 예를 들어, 이미지 분류 모델에서 특정 이미지가 왜 고양이로 분류되었는지 설명할 때 유용합니다.
- SHAP(SHapley Additive exPlanations): 게임 이론을 기반으로 각 특성이 모델의 예측에 기여한 정도를 계산합니다. 예를 들어, 환자의 병을 예측하는 모델에서 각 의료 기록이 예측에 얼마나 기여했는지 알 수 있습니다.
설명가능한 AI(XAI)의 작동원리
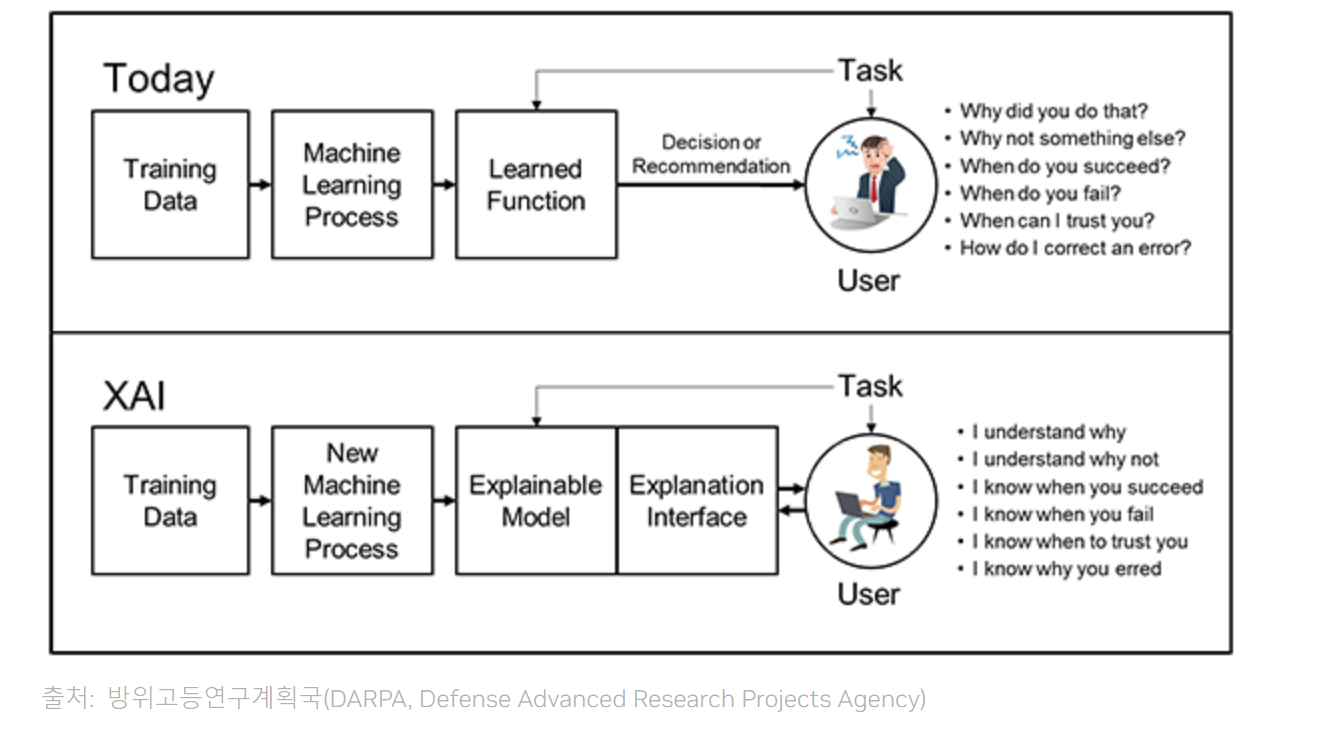
모델 설명 방법
a. 글로벌 설명
글로벌 설명은 전체 모델의 동작 방식을 설명하는 방법입니다. 모델이 모든 입력 데이터에 대해 어떻게 동작하는지, 어떤 특성이 가장 중요한지를 이해하는 데 중점을 둡니다.
- 특성 중요도(Feature Importance): 특성이 모델 예측에 기여하는 정도를 평가합니다. 이를 통해 어떤 특성이 가장 큰 영향을 미치는지 알 수 있습니다.
- 부분 의존 플롯(Partial Dependence Plot): 특정 특성이 예측 결과에 어떻게 영향을 미치는지 시각화합니다. 특성 값이 변할 때 예측 결과가 어떻게 변하는지 보여줍니다.
b. 지역 설명
지역 설명은 특정 예측 결과에 대한 모델의 동작 방식을 설명하는 방법입니다. 개별 데이터 포인트에 대해 모델이 어떤 결정을 내렸는지 이해하는 데 중점을 둡니다.
- LIME(Local Interpretable Model-agnostic Explanations): 개별 예측을 설명하기 위해 간단한 모델을 사용합니다. 예측을 설명하기 위해 입력 데이터 주변의 데이터를 샘플링하고, 간단한 모델을 학습시켜 이를 설명합니다.
- SHAP(SHapley Additive exPlanations): 개별 예측에 대한 각 특성의 기여도를 계산합니다. SHAP 값은 공정하고 일관된 방식으로 특성의 중요도를 측정합니다.
모델 종류에 따른 설명 방법
a. 모델 내부 설명
모델 내부 설명은 모델 자체가 해석 가능하도록 설계된 경우입니다. 이런 모델은 구조적으로 직관적이고 이해하기 쉽습니다.
- 결정 트리(Decision Tree): 트리 구조를 통해 예측 과정을 단계별로 시각적으로 이해할 수 있습니다.
- 선형 회귀(Linear Regression): 각 특성의 가중치를 통해 특성의 영향을 직관적으로 알 수 있습니다.
b. 모델 외부 설명
모델 외부 설명은 블랙박스 모델(예: 딥러닝, 앙상블 모델)에서 설명을 도출하는 방법입니다. 이러한 모델은 내부 구조가 복잡하기 때문에 별도의 해석 도구를 사용합니다.
- LIME: 복잡한 모델을 단순한 모델로 근사하여 개별 예측을 설명합니다.
- SHAP: 게임 이론을 사용하여 각 특성의 기여도를 계산하고, 이를 통해 모델의 예측을 설명합니다.
SHAP의 작동 원리
SHAP는 게임 이론의 샤플리 값(Shapley Value)에 기반하여 각 특성이 예측에 기여한 정도를 계산합니다. 샤플리 값은 협력 게임 이론에서 각 플레이어의 공정한 기여도를 계산하는 방법입니다. 이를 AI 모델에 적용하면 다음과 같은 과정을 거칩니다:
- 모든 특성 조합 고려: 각 특성이 포함되거나 제외된 모든 가능한 조합을 고려합니다.
- 기여도 계산: 각 조합에서 특정 특성을 추가하거나 제거했을 때 예측값이 얼마나 변하는지 계산합니다.
- 평균 기여도 산출: 모든 조합에서 계산된 기여도를 평균내어 각 특성의 샤플리 값을 구합니다.
이렇게 계산된 샤플리 값은 각 특성이 예측값에 얼마나 기여했는지를 공정하고 일관된 방식으로 나타냅니다.
XAI(eXplainable Artificial Intelligence) 등장배경
AI 기술의 급속한 발전과 복잡성 증가
a. 딥러닝과 복잡한 모델의 등장
딥러닝과 같은 복잡한 모델들은 뛰어난 성능을 보여주지만, 그 내부 구조는 매우 복잡하고 비직관적입니다. 이러한 모델들은 수백만 개의 매개변수를 포함하고 있어, 사람이 이해하기 어렵습니다. 복잡한 모델이 "블랙박스"처럼 작동함에 따라, AI 시스템의 예측과 결정을 이해하고 설명하는 것이 중요한 과제가 되었습니다.
b. 다양한 응용 분야
AI 기술은 의료, 금융, 법률, 자율주행, 보안 등 다양한 분야에 널리 사용되고 있습니다. 이러한 분야에서는 AI의 예측이 매우 중요한 영향을 미치기 때문에, 예측의 근거를 이해하는 것이 필수적입니다.
투명성 및 신뢰성에 대한 요구 증가
a. 신뢰성 확보
AI 시스템이 복잡해질수록 사용자는 시스템의 결정에 대한 신뢰성을 확보하기 어려워집니다. 특히 의료 진단, 금융 대출 승인 등과 같이 중요한 결정을 내리는 상황에서는 AI의 결정이 왜 그렇게 되었는지 설명할 수 있어야 합니다.
b. 투명성 요구
기업과 정부 기관은 AI 기술을 사용할 때 그 과정이 투명하게 공개되기를 원합니다. 이는 사용자와 이해관계자들이 AI 시스템을 더 신뢰할 수 있게 합니다.
책임성 및 규제 준수
a. 책임성 확보
AI가 내리는 결정에 대해 설명할 수 없으면, 잘못된 결정에 대한 책임 소재를 명확히 하기 어렵습니다. 이는 특히 법적 문제나 윤리적 문제와 관련될 수 있습니다. 예를 들어, 자동화된 채용 시스템이 특정 그룹을 차별한다면, 그 원인을 설명하고 책임을 명확히 할 수 있어야 합니다.
b. 규제 준수
여러 국가와 지역에서 AI 기술에 대한 규제를 강화하고 있습니다. 예를 들어, 유럽 연합의 GDPR(일반 데이터 보호 규정)은 자동화된 결정에 대해 설명할 수 있는 권리를 포함하고 있습니다. 이는 개인이 AI의 결정에 이의를 제기하고 그 결정의 근거를 요구할 수 있도록 합니다.
모델 개선 및 오류 수정
a. 모델 개선
AI 모델이 어떻게 작동하는지 이해하면, 모델을 더 쉽게 개선할 수 있습니다. 오류나 편향성을 발견하고 수정하는 데 도움이 됩니다. 이는 AI 시스템의 성능을 향상시키고, 더 공정하고 신뢰할 수 있는 시스템을 구축하는 데 기여합니다.
b. 오류 수정 및 편향성 제거
AI 모델이 잘못된 결정을 내리거나 특정 편향성을 보일 때, 이를 설명할 수 있다면 문제를 더 빠르고 정확하게 수정할 수 있습니다. 예를 들어, 특정 인종이나 성별에 대해 편향된 결과를 내는 모델을 발견하면, 그 원인을 분석하고 수정할 수 있습니다.
예시
- 의료 분야: AI 시스템이 환자의 진단 결과를 제공할 때, 그 결과를 설명할 수 있어야 의사와 환자가 신뢰할 수 있습니다. 예를 들어, AI가 암 진단을 내렸다면, 어떤 특성이 그 결정을 내리게 했는지 설명할 수 있어야 합니다.
- 금융 분야: 대출 승인 모델이 특정 신청자의 대출을 거부했다면, 그 이유를 명확히 설명할 수 있어야 합니다. 이는 신청자가 왜 거부되었는지 이해하고, 필요한 경우 신용 점수를 개선하기 위한 조치를 취할 수 있게 합니다.
- 법률 및 자율주행: 자율주행 자동차가 사고를 일으켰을 때, 그 사고의 원인을 설명할 수 있어야 합니다. 이는 책임 소재를 명확히 하고, 유사한 사고를 예방하는 데 도움이 됩니다.
'인공지능' 카테고리의 다른 글
| [AGI] AGI(인공 일반 지능)란 무엇인가? (0) | 2024.07.11 |
|---|---|
| [AI Agent] AI 에이전트란 무엇인가? (0) | 2024.07.11 |
| [Sovereign AI] 소버린 AI란 무엇인가? (0) | 2024.06.28 |
| [인공지능] RLHF이란 무엇인가? (0) | 2024.06.25 |
| [FMOps] FMOps란 무엇인가? (0) | 2024.06.25 |



