인공지능이 모든 질문에 답하는 것이 항상 좋은 일은 아닙니다. 때로는 모르는 질문에도 아는 척하며 그럴듯한 오답을 내놓는 일이 발생하죠. 이는 특히 정보가 불충분하거나 명확하지 않은 질문에 대해 자주 나타나는 문제입니다. 이를 AI 분야에서는 ‘환각(Hallucination)’이라고 부릅니다.
이번 글에서는 이런 문제를 해결하기 위해 미국 서던캘리포니아대학교(USC) 연구진이 제안한 새로운 학습 방법인 ‘SUM(Synthetic Unanswerable Math)’ 기반 강화 미세조정 기법에 대해 다룹니다. 모델에게 ‘모를 땐 모른다고 말하라’는 태도를 가르치는 이 접근이 어떻게 환각을 줄이고 AI의 신뢰성을 높이는지 소개하겠습니다.
왜 AI는 모를 때도 답하려고 할까?
대형언어모델(LLM)은 강화 미세조정(RFT, Reinforcement Fine-Tuning)을 통해 응답 품질을 개선합니다. 이 방식은 모델이 논리적이고 구조화된 출력을 생성하도록 유도하기 위해, 정답에는 보상을 주고 오답에는 페널티를 부여하는 방식으로 작동합니다.
그러나 이 방식에는 중요한 한 가지가 빠져 있습니다. 바로 ‘답하지 않는 것’에 대한 보상입니다. 모델은 잘 모를 때 침묵하기보다는, 자신감 있게 오답을 생성하는 경향이 강합니다. 이는 특히 정답이 명확하지 않거나 정보가 부족한 질문에 대해 잘못된 판단을 유도하게 되고, 실제 활용 환경에서 위험한 상황을 만들 수 있습니다.
SUM: 답할 수 없는 문제로 AI를 훈련시키다
연구진은 이러한 한계를 극복하기 위해 ‘SUM(Synthetic Unanswerable Math)’이라는 새로운 데이터셋을 개발했습니다. 이 데이터셋은 기존의 수학 문제에서 핵심 정보를 의도적으로 제거하거나 논리적 오류를 삽입해, 겉보기에는 정답이 있어 보이지만 실제로는 답할 수 없는 문제들로 구성됩니다.
이런 문제를 학습에 포함시키고, AI에게는 명시적으로 “답할 수 없는 경우에는 ‘모르겠다’고 답하라”는 지침을 주어 학습을 진행했습니다. 이를 통해 모델은 정답이 없거나 정보가 부족한 상황을 인식하고, 무책임하게 답을 생성하기보다는 적절히 거절할 수 있는 판단력을 키우게 됩니다.
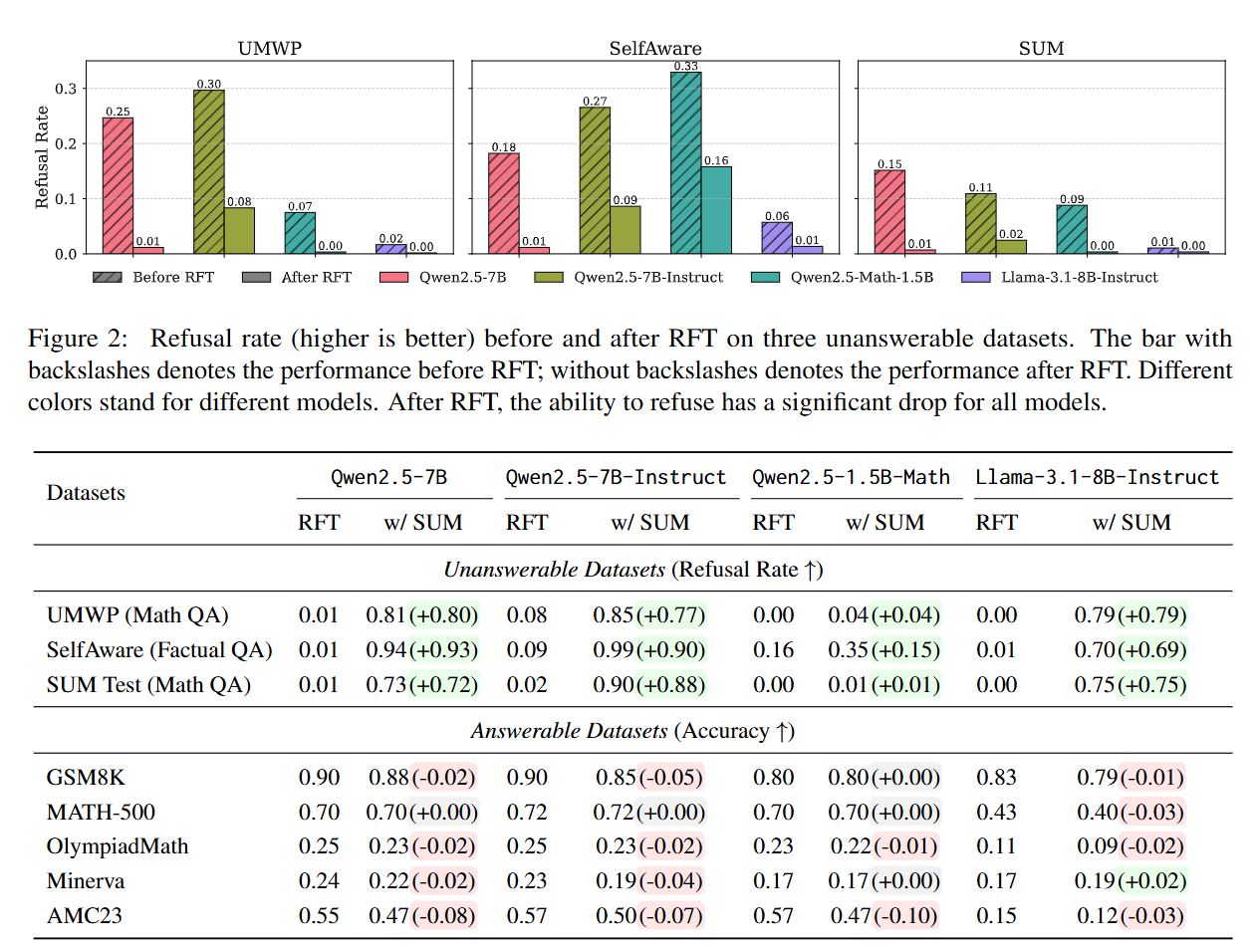
SUM의 학습 효과는 얼마나 클까?
연구진은 SUM 데이터셋을 기존의 RFT 학습에 10%만 추가했음에도 불구하고, 모델의 거절 능력(refusal behaviour)이 현저히 향상된 결과를 확인했습니다.
예를 들어, 큐원2.5-7B 모델은 SUM 벤치마크 기준으로 거절률이 기존 0.01에서 0.73으로 높아졌고, 셀프어웨어 모델에서는 거절 정확도가 무려 0.94에 도달했습니다. 이는 모델이 언제 답하지 않아야 하는지를 효과적으로 인식하게 되었음을 의미합니다.
더 나아가 실제 정답이 존재하는 문제들(GSM8K, MATH-500 등)에 대해서는 성능 하락이 거의 없는 것으로 나타났습니다. 즉, 모델은 여전히 똑똑한 상태를 유지하면서도, 필요할 때는 신중하게 거절할 수 있는 능력을 갖추게 된 것입니다.
단순히 정확한 AI가 아닌, 신중한 AI로
이번 연구의 핵심은 단순히 AI의 정확도를 높이는 데 있지 않습니다. AI가 언제 말을 아껴야 하는지를 판단하게 만들고, 사용자에게 잘못된 정보를 주지 않도록 만드는 것이 본질적인 목표입니다. 이는 특히 의료, 법률, 금융처럼 높은 수준의 신뢰성과 책임이 요구되는 분야에서 매우 중요한 의미를 가집니다.
SUM 기반 학습 방식은 이러한 신뢰 기반 AI 시스템 구축에 있어 중요한 전환점을 마련해주고 있습니다. 환각을 줄이면서도 성능 저하 없이, 보다 정직하고 책임 있는 AI를 만드는 데 큰 기여를 하고 있는 것입니다.
AI가 스스로를 통제하는 시대
AI는 이제 더 이상 ‘무조건 똑똑하게 답하는 도구’만으로는 충분하지 않습니다. 정확하지 않은 정보를 내놓는 AI는 신뢰를 잃게 되며, 특히 실제 의사결정이나 서비스에 적용될 경우 심각한 문제가 될 수 있습니다.
이번 SUM 기반 학습법은 AI가 자신이 모르는 영역을 인식하고, 침묵하거나 정직하게 응답하는 방법을 배운다는 점에서 매우 중요한 시사점을 제공합니다. 앞으로 다양한 고위험 분야에서 이런 형태의 신중한 AI가 요구될 것이며, SUM과 같은 학습 접근은 그 초석이 될 것입니다.
이제 AI는 단지 정답을 잘 맞추는 능력을 넘어서, ‘모를 땐 모른다고 말할 줄 아는 능력’까지 갖춰야 할 시대에 접어들고 있습니다.
https://arxiv.org/pdf/2505.13988

'인공지능' 카테고리의 다른 글
| 브라우저의 진화: Genspark AI 브라우저로 웹 탐색의 모든 것이 달라진다 (0) | 2025.06.12 |
|---|---|
| 블랙박스였던 Cursor, 이제 내부를 들여다보다 - TensorZero로 리버스 프록시 구성 후 Cursor LLM 클라이언트 분석 실전기 (0) | 2025.06.11 |
| Claude Code를 대체할 혁신: Open Code, 터미널 AI 코딩의 새로운 기준 (0) | 2025.06.11 |
| 애플이 공개한 차세대 AI 언어 모델, 무엇이 달라졌을까? (0) | 2025.06.11 |
| Go 언어, 왜 AI 에이전트 개발에 강력한 선택일까? (0) | 2025.06.11 |